
美团LongCat模型负责人将离职
美团LongCat模型负责人将离职有知情人士透露,美团LongCat团队基础模型负责人裴鹏即将离职。公开资料显示,裴鹏毕业于北京大学,长期深耕信息检索与自然语言处理方向,职业履历覆盖多家全球顶尖科技企业。
来自主题: AI资讯
9105 点击 2026-07-26 14:53
 搜索
搜索
有知情人士透露,美团LongCat团队基础模型负责人裴鹏即将离职。公开资料显示,裴鹏毕业于北京大学,长期深耕信息检索与自然语言处理方向,职业履历覆盖多家全球顶尖科技企业。

大模型浪潮席卷全球数年,技术形态持续迭代,也开始从办公、编程领域,深度渗透到科研这一核心赛道。从中科大夯实数理根基,到哈佛、MIT 完成联合培养,青年学者陈勇超横跨力学、机器人、自然语言处理、大模型等多个领域,完整亲历 AI 一轮轮技术变革。
过去几年,大模型把自然语言处理彻底重塑了。GPT 出来之前,NLP 领域的状态是:每个任务一套模型,每个场景一批数据,每个公司一条流水线,互不通用,边界清晰。GPT 之后,这套逻辑被一个预训练底座 + 任务微调的范式整个替换掉了。
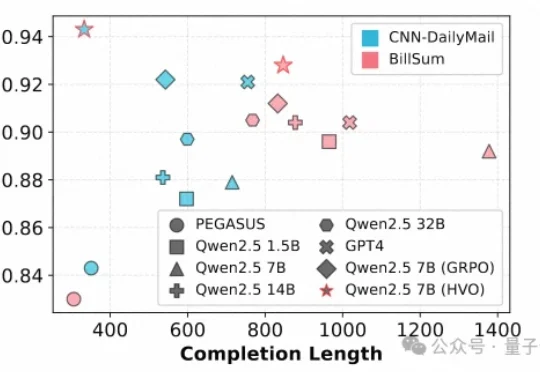
文本摘要作为自然语言处理(NLP)的核心任务,其质量评估通常需要兼顾一致性(Consistency)、连贯性(Coherence)、流畅性(Fluency)和相关性(Relevance)等多个维度。
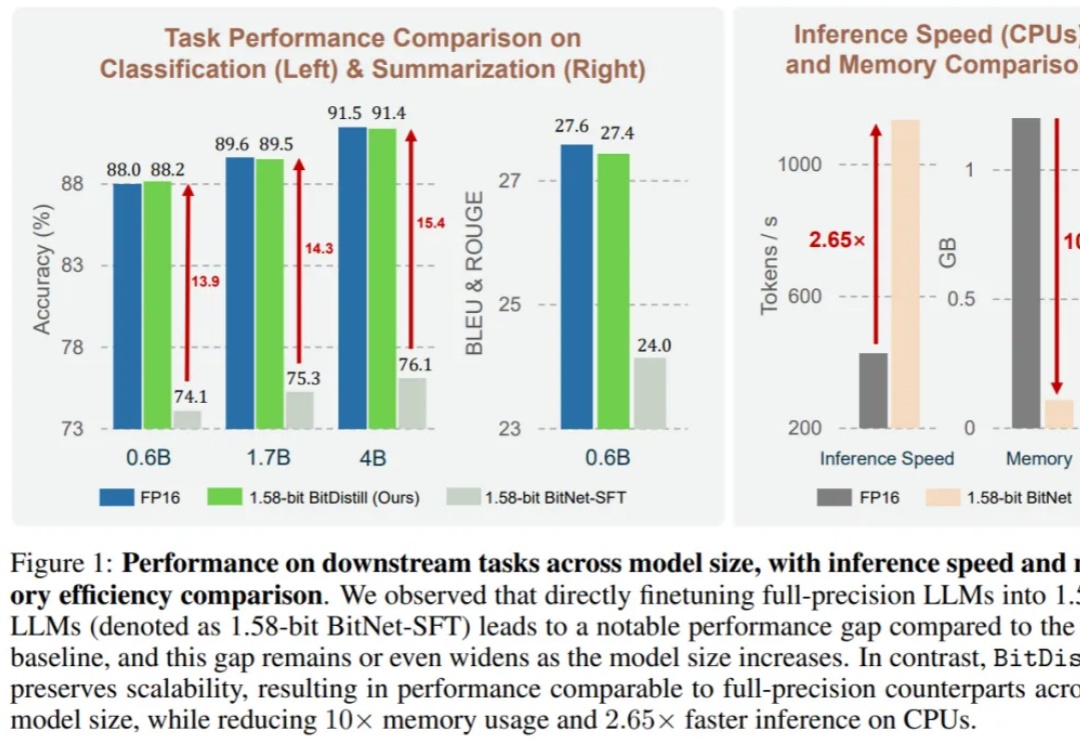
大语言模型(LLM)不仅在推动通用自然语言处理方面发挥了关键作用,更重要的是,它们已成为支撑多种下游应用如推荐、分类和检索的核心引擎。尽管 LLM 具有广泛的适用性,但在下游任务中高效部署仍面临重大挑战。
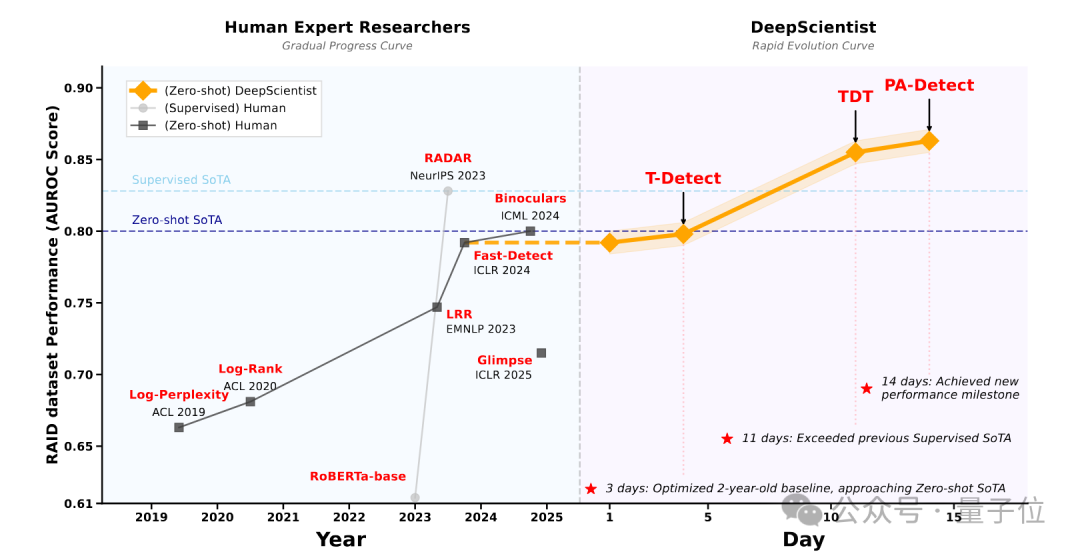
最近,来自西湖大学的自然语言处理实验室发布了DeepScientist系统,这也是首个具有完整科研能力,且在无人工干预下,展现出目标导向、持续迭代、渐进式超越人类研究者最先进研究成果的AI科学家系统。
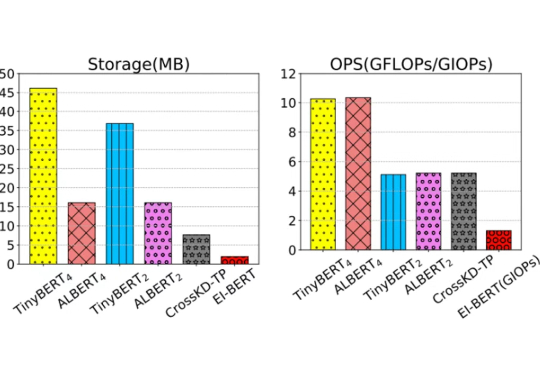
在移动计算时代,将高效的自然语言处理模型部署到资源受限的边缘设备上面临巨大挑战。这些场景通常要求严格的隐私合规、实时响应能力和多任务处理功能。
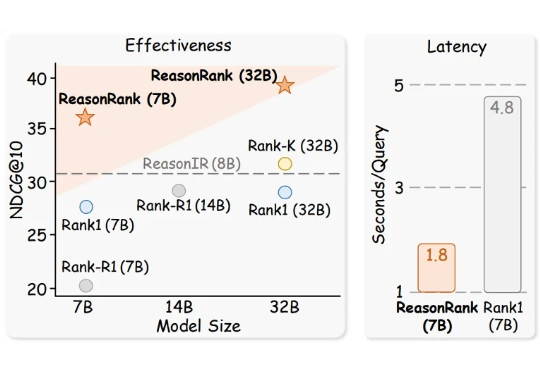
推理大模型(Large Reasoning Model)极大的促进了自然语言处理领域的发展,而信息检索领域的核心问题之一是文档排序,如何利用强大的推理大模型通过主动推理来判断文档的相关性,进而再对文档进行排序是一个值得探索的方向。
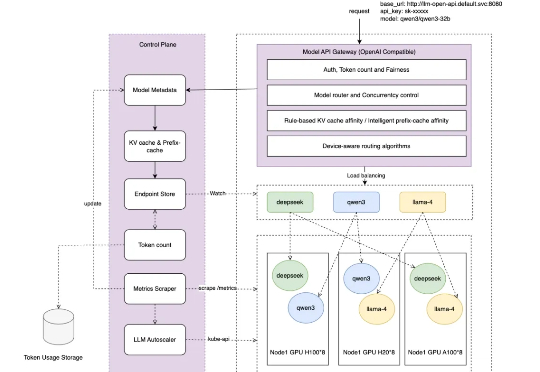
随着人工智能技术的快速发展,大语言模型在自然语言处理领域引发了深刻变革。大语言模型在实际应用中的使用越来越广泛,这些模型通常部署在云原生的基础设施上,需要复杂的流量管理机制以确保服务的稳定性、性能、可扩展性和成本效益。在 Kubernetes(K8S)这一容器编排标准中,现有的 Ingress 组件的流量转发机制提供了基于主机名和请求路径的基本流量路由功能。
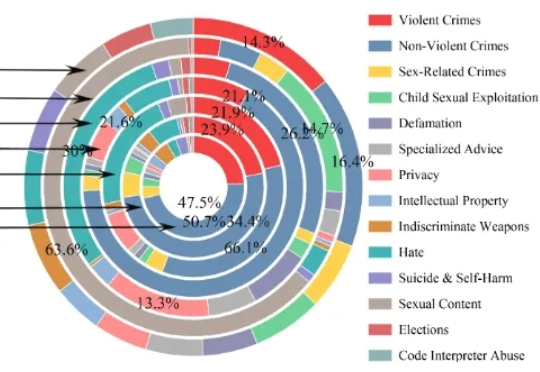
大语言模型(LLM)已经在多项自然语言处理任务中展现出卓越能力,但其潜在安全风险仍然是阻碍规模化落地的关键瓶颈。目前社区用于安全对齐的公开数据集,往往偏重于「词汇多样性」,即让同一种风险指令尽可能用不同的表达方式出现,却很少系统考虑指令背后的「恶意意图多样性」以及「越狱策略多样性」。