ICLR 2026 | 7B小模型干翻GPT-5?AdaResoner实现Agentic Vision的主动「视觉工具思考」
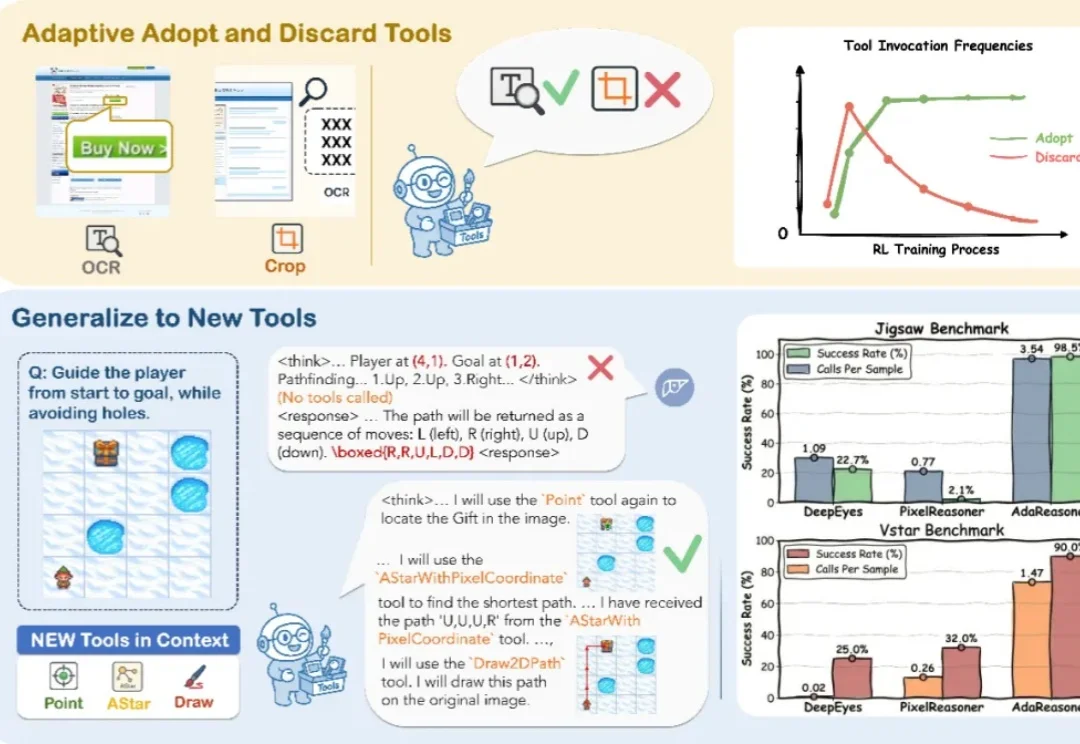
ICLR 2026 | 7B小模型干翻GPT-5?AdaResoner实现Agentic Vision的主动「视觉工具思考」你见过 7B 模型在拼图推理上干翻 GPT-5 吗?
来自主题: AI技术研报
7308 点击 2026-03-04 11:18
 搜索
搜索
你见过 7B 模型在拼图推理上干翻 GPT-5 吗?
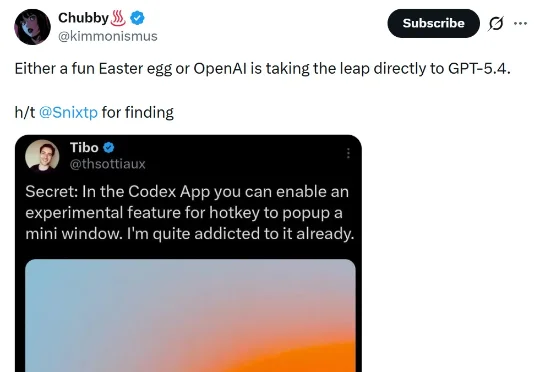
OpenAI 意外泄露 GPT-5.4!新版凭 200 万 Tokens 与「状态化 AI」实现跨会话持久记忆,并支持全分辨率视觉直读。AI 将从聊天工具向「全自动代理」进化,彻底重塑工作流并引爆底层硬件内存之战。

从电商团队到视觉设计师,如今任何人都能在几分钟内生成数百张可投入生产的图片。几年前,这样的产量需要数千名摄影师、工作室和制作人员。长期以来支配电商及其他数字领域的成本结构已经发生了转变。传统的内容生产
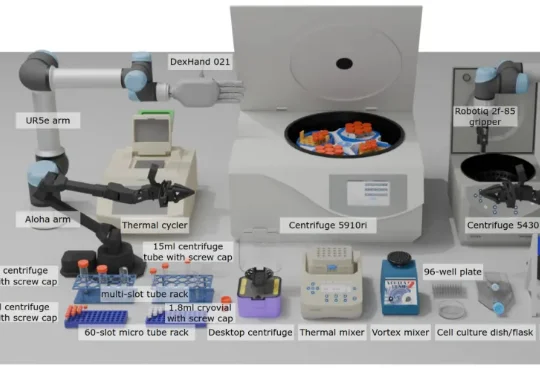
现有 VLA 模型的研究和基准测试多局限于家庭场景(如整理餐桌、折叠衣物),缺乏对专业科学场景(尤其是生物实验室)的适配。生物实验室具有实验流程结构化、操作精度要求高、多模态交互复杂(透明容器、数字界面)等特点,是评估 VLA 模型精准操作、视觉推理和指令遵循能力的理想场景之一。

据彭博社记者 Mark Gurman 爆料,苹果正在加速推进三款全新的 AI 可穿戴设备。这三款产品都将围绕 Siri 数字助手构建,通过摄像头获取视觉上下文来执行各种操作。
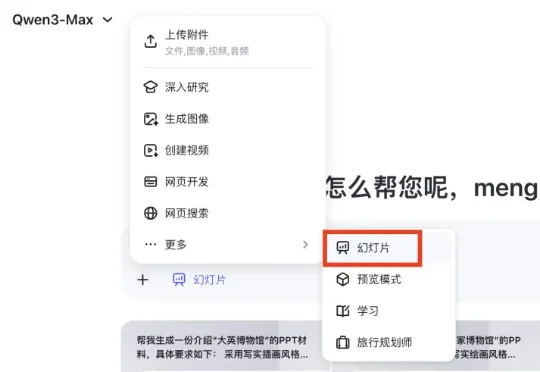
千问前脚刚把Qwen-Image-2.0甩出来,后脚就又放大招,冲着牛马党学生党的「痛处」下手了——就在这两天,重磅发布了AI PPT生成工具:Qwen AI Slides(幻灯片),据说从内容结构到视觉配图,一套全包……

清华大学团队推出的Dolphin模型突破了「高性能必高能耗」的瓶颈:仅用6M参数(较主流模型减半),通过离散化视觉编码和物理启发的热扩散注意力机制,实现单次推理即可精准分离语音,速度提升6倍以上,在多项基准测试中刷新纪录,为智能助听器、手机等端侧设备部署高清语音分离开辟新路。
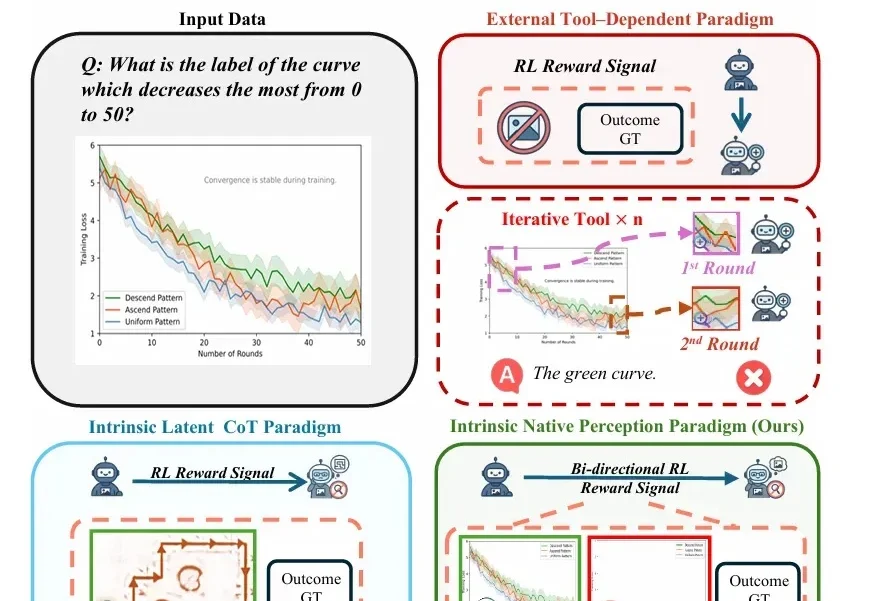
随着视觉-语言模型(VLM)推理能力不断增强,一个隐蔽的问题逐渐浮现: 很多错误不是推理没做好,而是“看错了”。
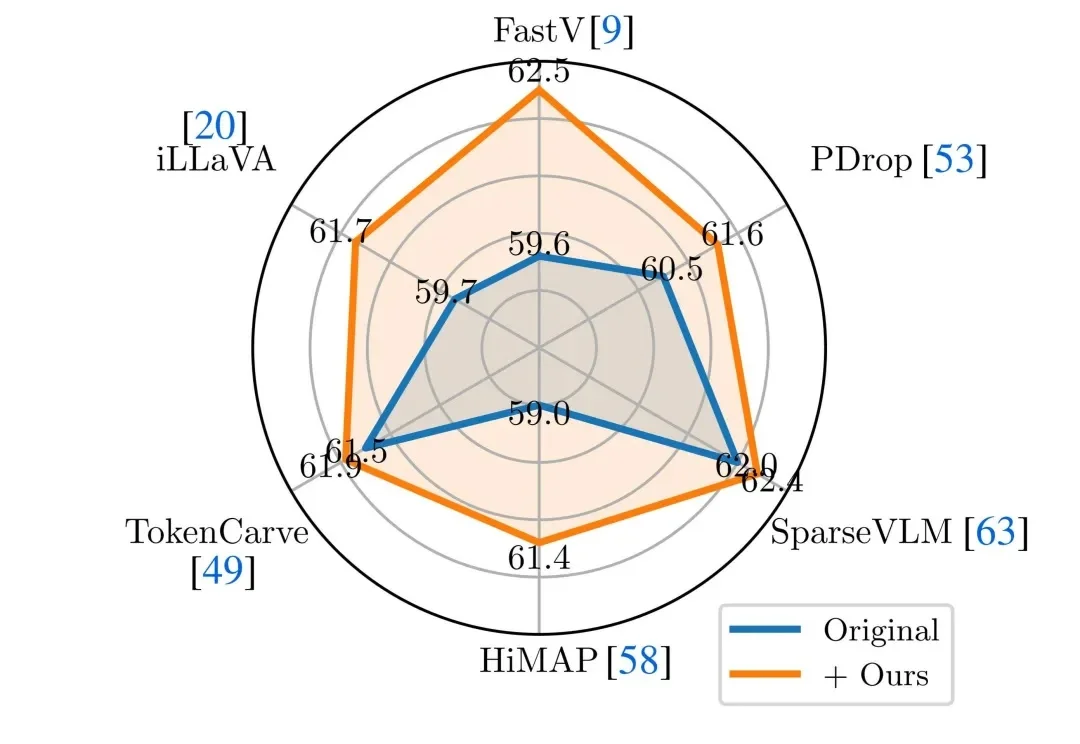
近年来,Vision-Language Models(视觉 — 语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。然而,这类模型在实际应用中往往面临推理开销大、效率受限的问题,研究者通常依赖 visual token pruning 等策略降低计算成本,其中 attention 机制被广泛视为衡量视觉信息重要性的关键依据。
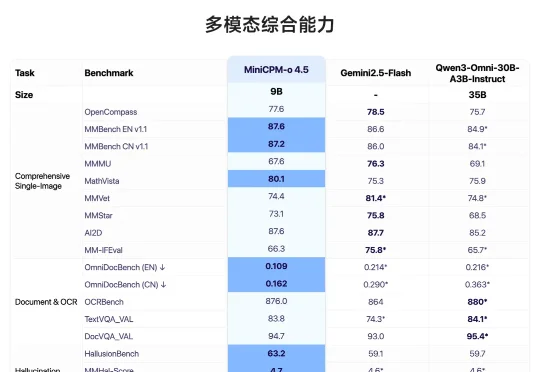
面壁开源了行业首个全双工全模态大模型 MiniCPM-o 4.5,相比已有多模态模型,MiniCPM-o 4.5 首次实现了「边看边听边说」以及「自主交互」的全模态能力,模型不再只是把视觉、语音作为静态输入处理,而是能够在实时、多模态信息流中持续感知环境变化,并在输出的同时保持对外界的理解。