
物理AI的「原生」时刻:原力灵机发布具身大模型DM0
物理AI的「原生」时刻:原力灵机发布具身大模型DM0当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。
来自主题: AI技术研报
6920 点击 2026-03-11 15:04
 搜索
搜索
当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。
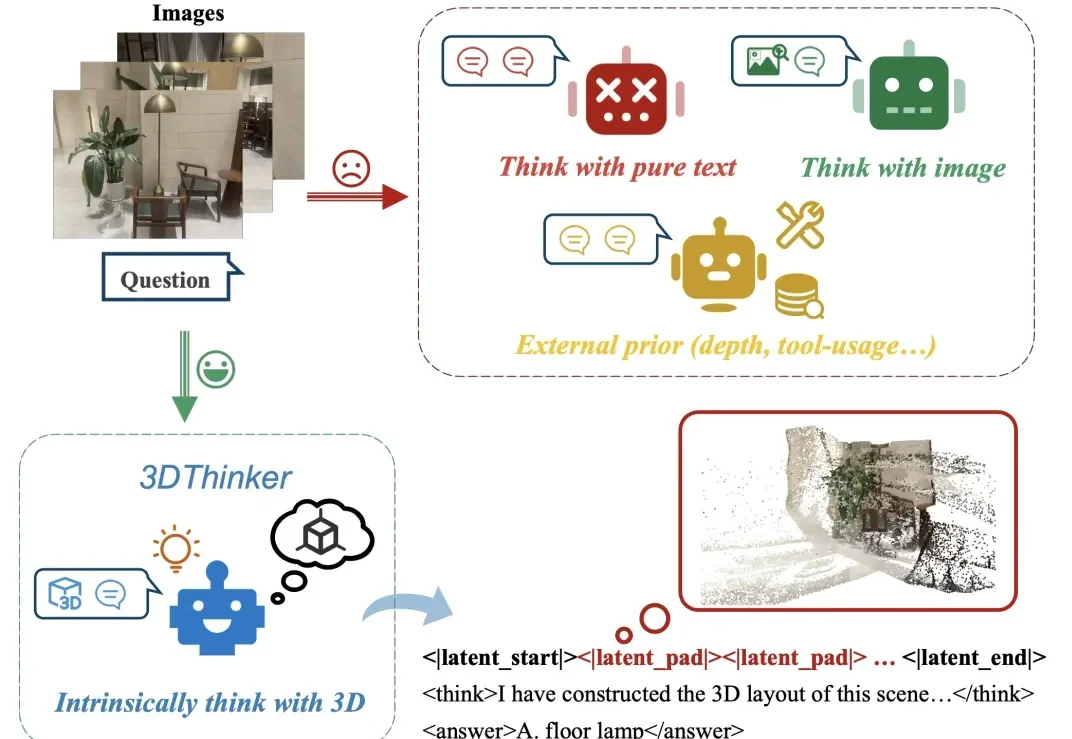
大家是否有这样的感觉?给定几张场景中拍摄的图片,往往能够在脑海中想象出这个场景的三维布局,然而当前的多模态大模型还停留于纯文本或者 2D 视觉的推理表示,限制了图像中隐含几何结构的表达能力。

NUS、ZJU、UW、Stanford、CUHK 联合提出 「ThinkMorph」,主张让文字与图像在统一架构里「原生协作」、「共同演化」,而不是像当下大多数多模态模型那样,看完图像就闭上眼睛,后续完全靠文字链条推进。仅用 2.4 万条数据微调 7B 统一模型,视觉推理平均提升 34.74%,多项任务比肩甚至超越 GPT-4o 和 Gemini 2.5 Flash。

在 AI 视觉生成领域,扩散模型(DM)凭借其强大的高保真数据生成能力,已成为图像合成、视频生成等多模态任务的核心框架。然而,预训练后的扩散模型如何高效适配下游应用需求,一直是行业面临的关键挑战。
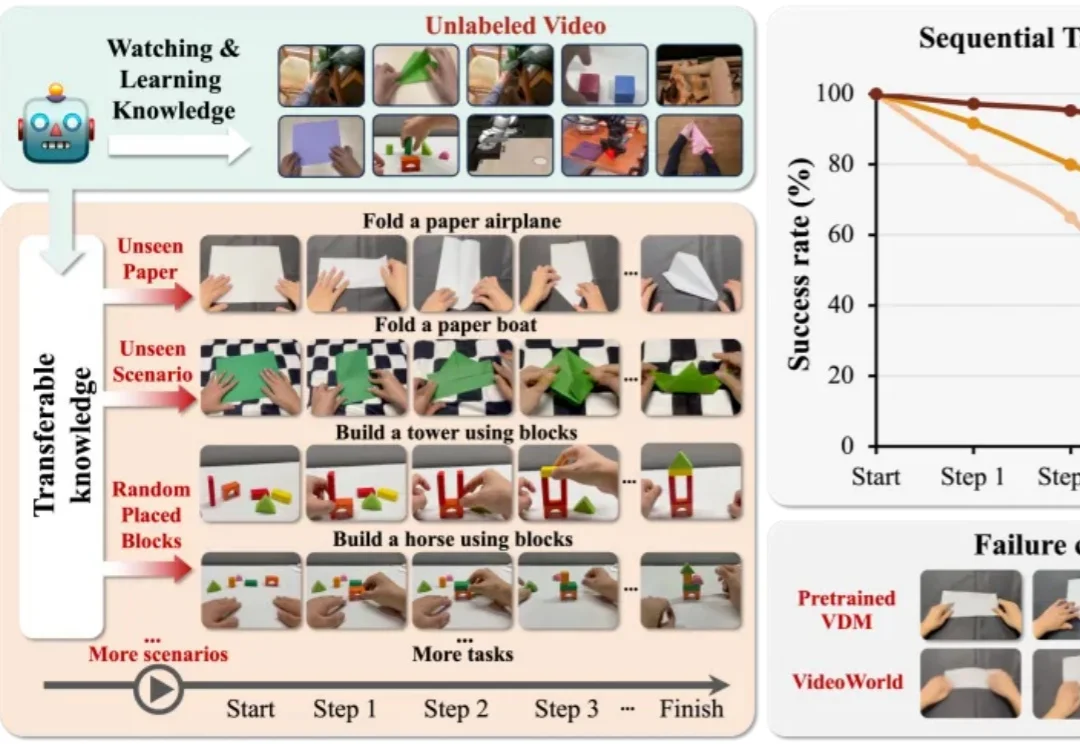
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。

是不是经常纠结于 VLA(视觉 - 语言 - 动作)模型的训练技巧?面对层出不穷的 VLA 算法,是不是常常感到眼花缭乱,不知道哪种数据模态、训练策略最有效? 别急,丰田研究院(TRI)和清华大学刚刚
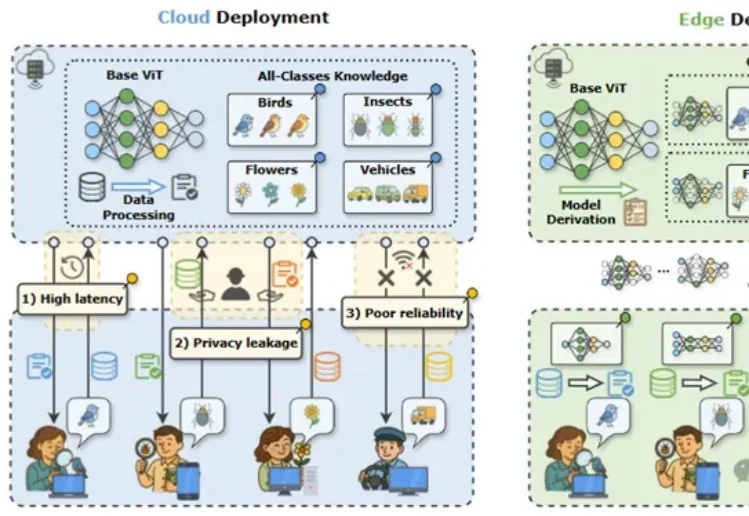
近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。
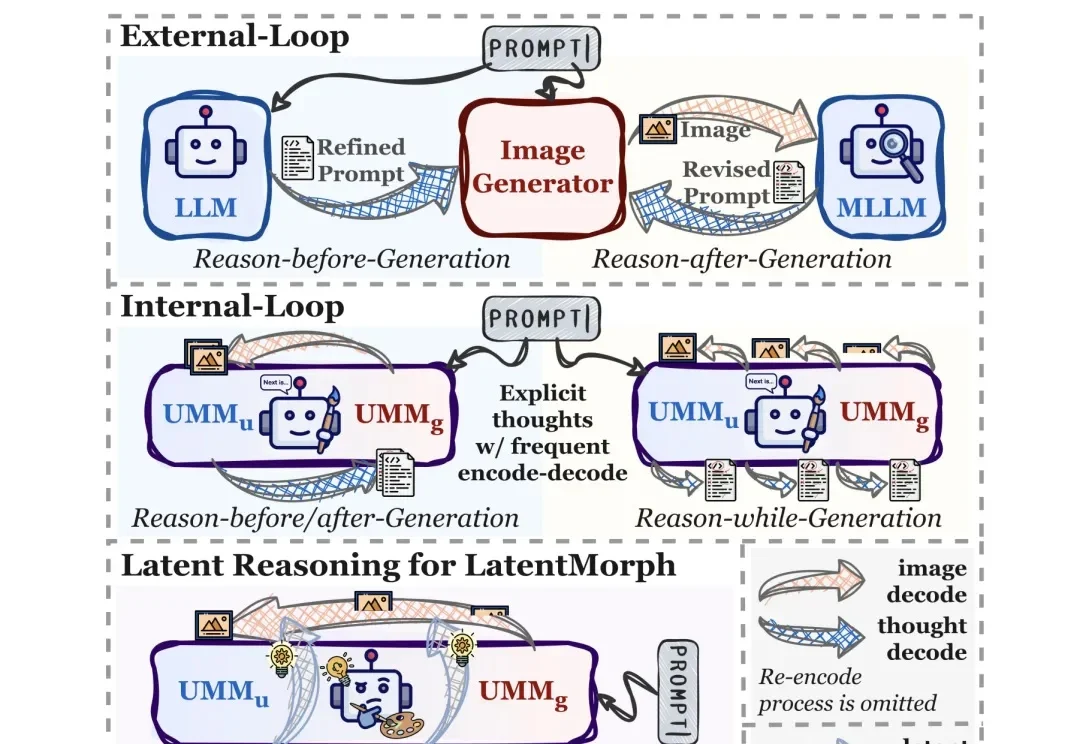
人类在创作艺术时,大脑并非一味地输出,而是在每一笔落下时都在进行着复杂的、难以言表的 “视觉优化”。

激进投资者艾略特投资管理公司已持有Pinterest 价值 10 亿美元股份,该公司以积极参与企业决策而闻名。该机构首次投资这家社交平台是在 2022 年。

长期以来,计算机视觉领域陷入了一个 “表征(Representation)” 的执念。我们习惯设计各种精巧的 Encoder,试图将动态世界压缩成一组特征向量。然而,视频作为现实的高维投影,其熵值之高、动态之复杂,让这种试图 “定格” 的表征显得力不从心。