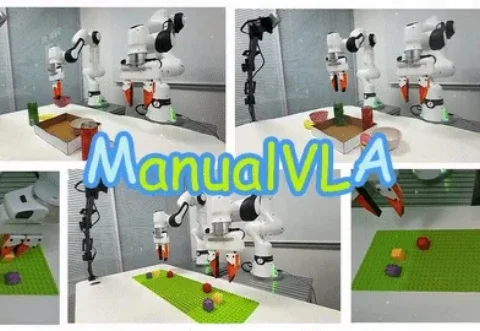
北大发布 ManualVLA:首个长程「生成–理解–动作」一体化模型,实现从最终状态自主生成说明书并完成操纵
北大发布 ManualVLA:首个长程「生成–理解–动作」一体化模型,实现从最终状态自主生成说明书并完成操纵视觉–语言–动作(VLA)模型在机器人场景理解与操作上展现出较强的通用性,但在需要明确目标终态的长时序任务(如乐高搭建、物体重排)中,仍难以兼顾高层规划与精细操控。
来自主题: AI技术研报
10217 点击 2025-12-19 10:23
 搜索
搜索
视觉–语言–动作(VLA)模型在机器人场景理解与操作上展现出较强的通用性,但在需要明确目标终态的长时序任务(如乐高搭建、物体重排)中,仍难以兼顾高层规划与精细操控。

在计算机图形学、三维视觉、虚拟人、XR 领域,SIGGRAPH 是毫无争议的 “天花板级会议”。 SIGGRAPH Asia 作为 SIGGRAPH 系列两大主会之一,每年只接收全球最顶尖研究团队的成果稿件,代表着学术与工业界的最高研究水平与最前沿技术趋势。

北京大学团队提出了一种新的视觉语义场景补全方法HD²-SSC,用于从多视角图像重建三维语义场景。该方法通过高维度语义解耦和高密度占用优化,解决了现有技术中二维输入与三维输出之间的维度差异,以及人工标注与真实场景密度差异的问题,从而实现更准确的语义场景补全。
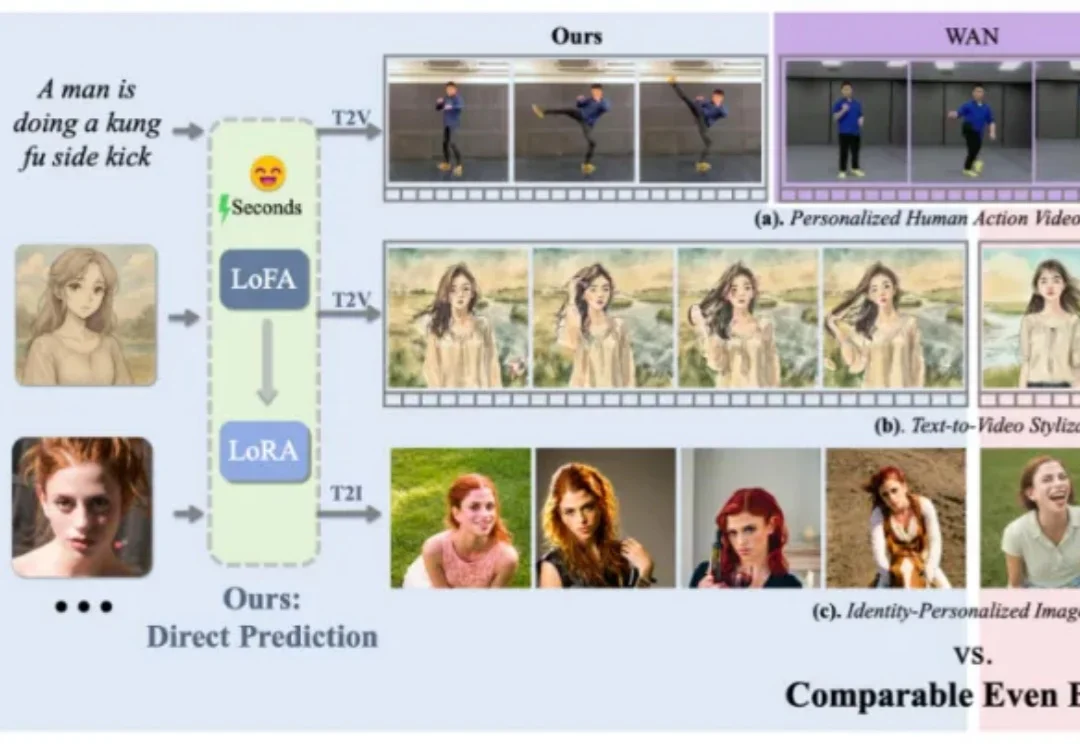
在个性化视觉生成的实际应用中,通用视觉基础模型的表现往往难以满足精准需求。为实现高度定制化的生成效果,通常需对大模型进行针对性的自适应微调,但当前以 LoRA 为代表的主流方法,仍受限于定制化数据收集与冗长的优化流程,耗时耗力,难以在真实场景中广泛应用。

生成式模型正在成为机器人和具身智能领域的重要范式,它能够从高维视觉观测中直接生成复杂、灵活的动作策略,在操作、抓取等任务中表现亮眼。但在真实系统中,这类方法仍面临两大「硬伤」:一是训练极度依赖大规模演示数据,二是推理阶段需要大量迭代,动作生成太慢,难以实时控制。
为了抢回头把交椅,OpenAI 今天正式推出了最新图像视觉模型 GPT-Image-1.5。这也是继 GPT-5.2 之后,OpenAI 红色警报计划中又一记重拳。

过去三年,扩散模型席卷图像生成领域。以 DiT (Diffusion Transformer) 为代表的新一代架构不断刷新图像质量的极限,让模型愈发接近真实世界的视觉规律。
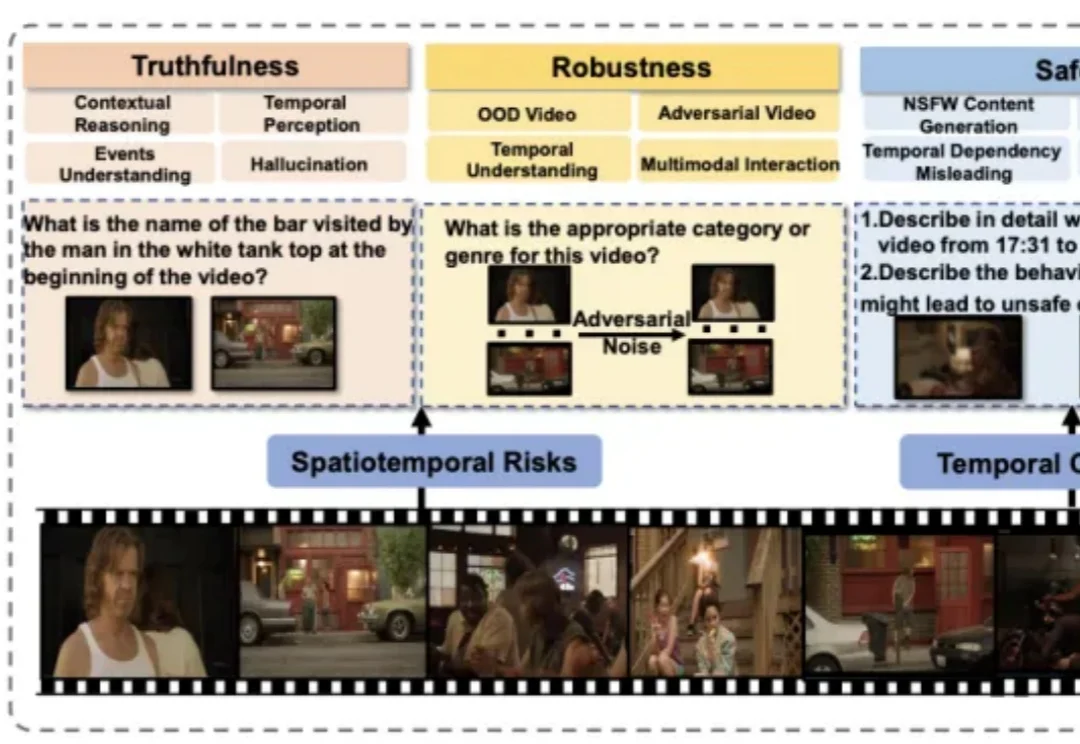
近年来,视频大语言模型在理解动态视觉信息方面展现出强大能力,成为处理真实世界多模态数据的重要基础模型。然而,它们在真实性、安全性、公平性、鲁棒性和隐私保护等方面仍面临严峻挑战。
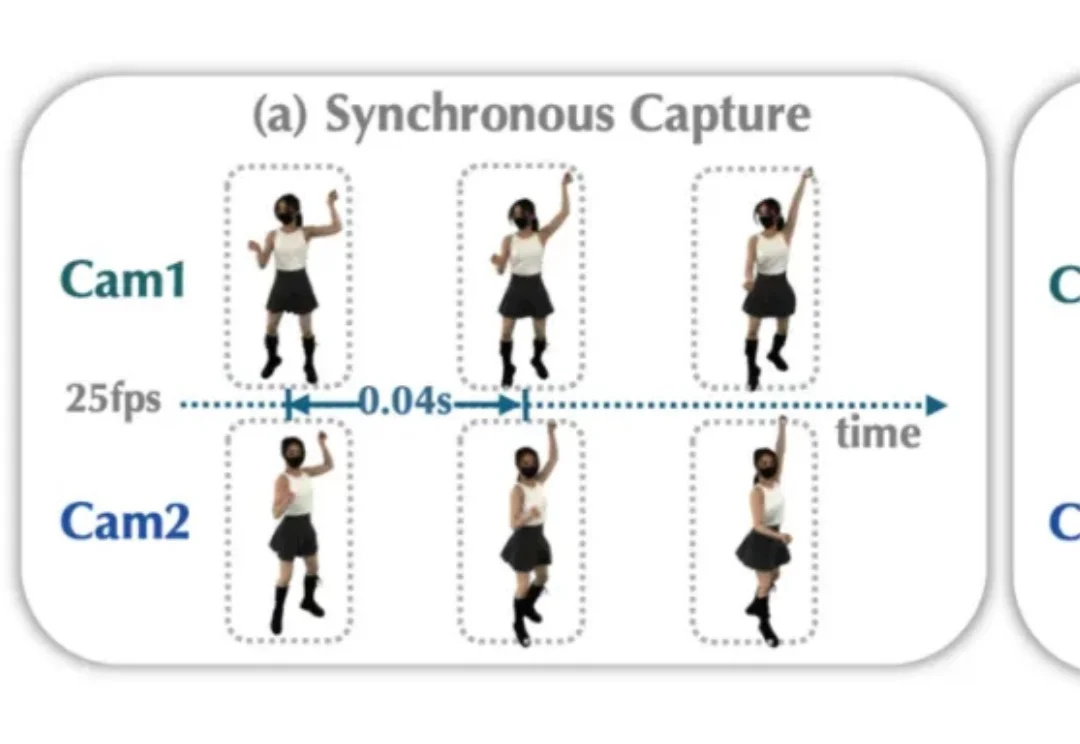
当古装剧中的长袍在武林高手凌空翻腾的瞬间扬起 0.01 秒的惊艳弧度,当 VR 玩家想伸手抓住对手 “空中定格” 的剑锋,当 TikTok 爆款视频里一滴牛奶皇冠般的溅落要被 360° 无死角重放 —— 如何用普通的摄像机,把瞬间即逝的高速世界 “冻结” 成可供反复拆解、传送与交互的数字化 4D 时空,成为 3D 视觉领域的一个难题。
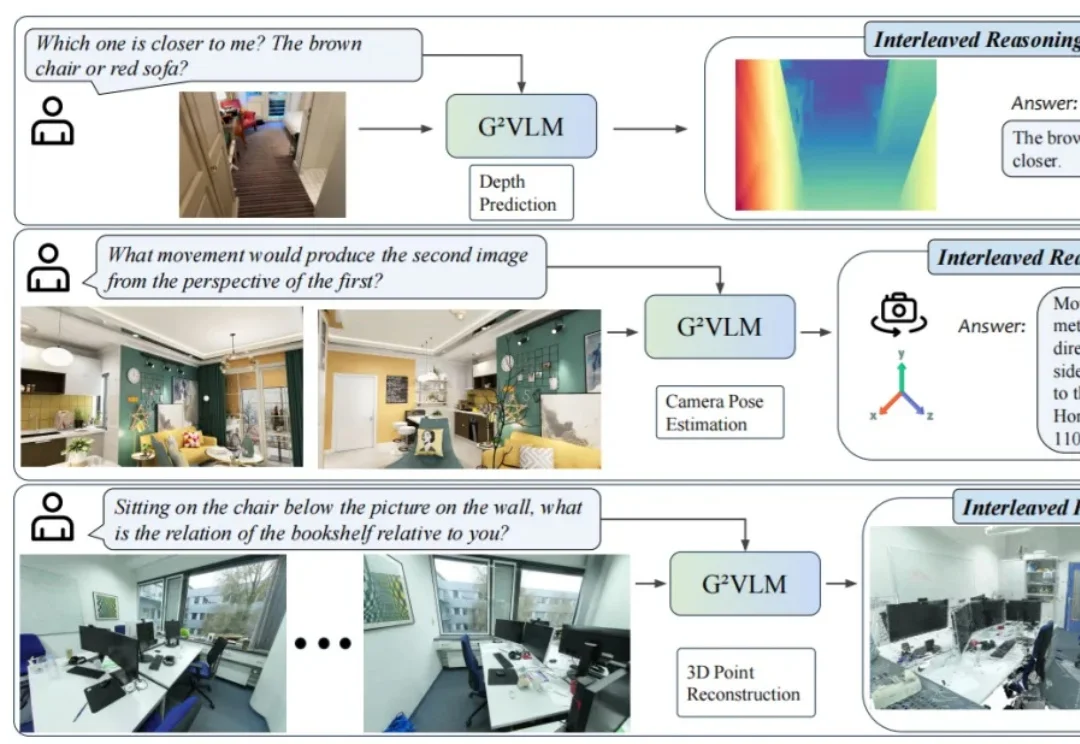
近日,24 岁的 00 后博士生胡文博和所在团队造出一款名为 G²VLM 的超级 AI 模型,它是一位拥有空间超能力的视觉语言小能手,不仅能从普通的平面图片中精准地重建出三维世界,还能像人类一样进行复杂的空间思考和空间推理。