
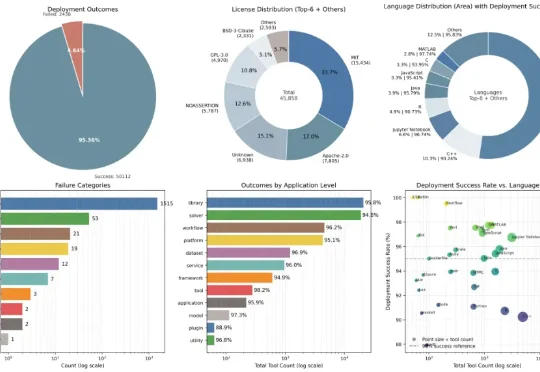
让两个大模型「在线吵架」,他们跑通了全网95%科研代码|深势发布Deploy-Master
让两个大模型「在线吵架」,他们跑通了全网95%科研代码|深势发布Deploy-Master在真实世界中,部署并不是一个孤立步骤,而是一条连续链路:工具能否被发现、是否被正确理解、能否构建环境,以及是否真的可以被执行。Deploy-Master 正是围绕这条链路,被设计为一个以执行为中心的一站式自动化工作流。
来自主题: AI资讯
8829 点击 2026-01-10 17:04
在真实世界中,部署并不是一个孤立步骤,而是一条连续链路:工具能否被发现、是否被正确理解、能否构建环境,以及是否真的可以被执行。Deploy-Master 正是围绕这条链路,被设计为一个以执行为中心的一站式自动化工作流。

几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。
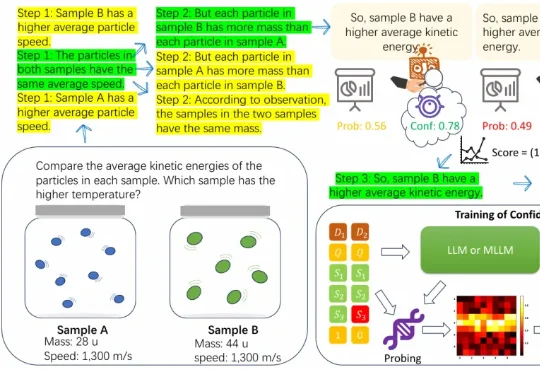
近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式
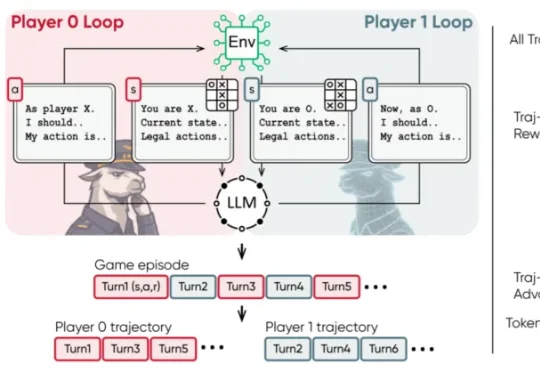
近日,清华大学等机构的研究团队提出了 MARSHAL 框架。该框架利用强化学习,让大模型在策略游戏中进行自博弈(Self-Play)。实验表明,这种多轮、多智能体训练不仅提升了模型在游戏中的博弈决策水

MIT天才博士一毕业,火速加盟OpenAI前CTO初创!最近,肖光烜(Guangxuan Xiao)在社交媒体官宣,刚刚完成了MIT博士学位。下一步,他将加入Thinking Machines,专注于大模型预训练的工作。
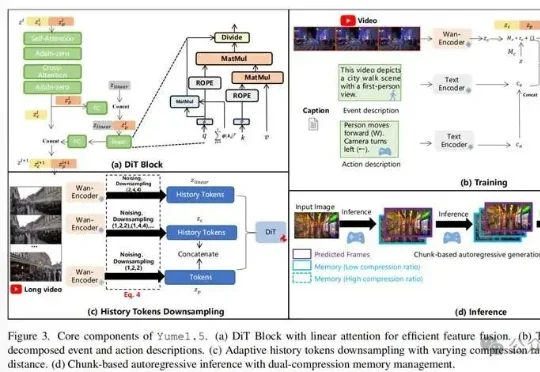
上海AI Lab联合多家机构开源的Yume1.5,针对这一核心难题提出了时空信道联合建模(TSCM),在长视频生成中实现了近似恒定计算成本的全局记忆访问。

CaveAgent的核心思想很简单:与其让LLM费力地去“读”数据的文本快照,不如给它一个如果不手动重启、变量就永远“活着”的 Jupyter Kernel。这项由香港科技大学(HKUST)领衔的研究,为我们展示了一种“Code as Action, State as Memory”的全新可能性。它解决了所有开发过复杂Agent的工程师最头疼的多轮对话中的“失忆”与“漂移”问题。

借鉴人类联想记忆,嵌套学习让AI在运行中构建抽象结构,超越Transformer的局限。谷歌团队强调:优化器与架构互为上下文,协同进化才能实现真正持续学习。这篇论文或成经典,开启AI从被动训练到主动进化的大门。

“我们只交付100%可以复现的轨迹。”

针对端到端全模态大模型(OmniLLMs)在跨模态对齐和细粒度理解上的痛点,浙江大学、西湖大学、蚂蚁集团联合提出 OmniAgent。这是一种基于「音频引导」的主动感知 Agent,通过「思考 - 行动 - 观察 - 反思」闭环,实现了从被动响应到主动探询的范式转变。