
Qwen负责人转发2025宝藏论文,年底重读「视觉领域GPT时刻」
Qwen负责人转发2025宝藏论文,年底重读「视觉领域GPT时刻」2025最后几天,是时候来看点年度宝藏论文了。
来自主题: AI技术研报
6184 点击 2025-12-31 14:12
2025最后几天,是时候来看点年度宝藏论文了。
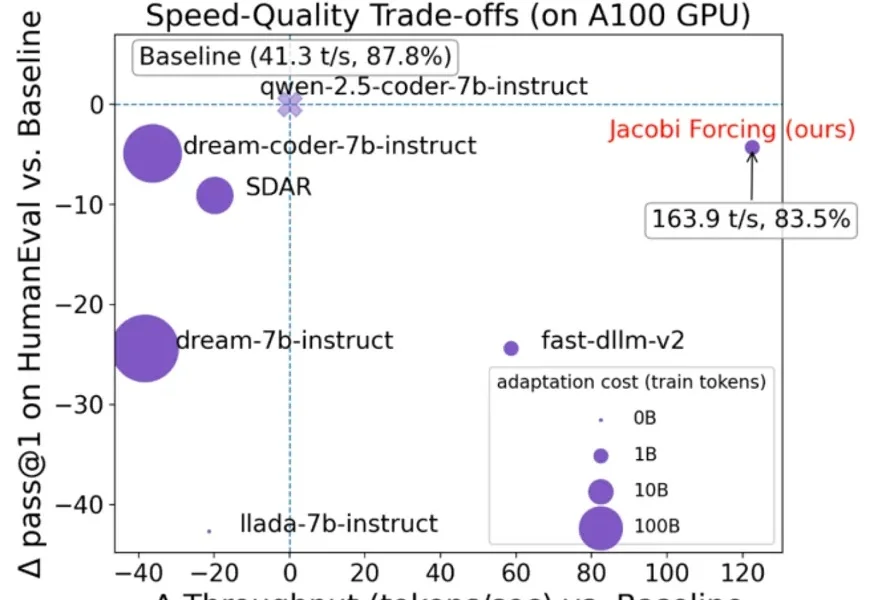
在大语言模型(LLM)落地应用中,推理速度始终是制约效率的核心瓶颈。传统自回归(AR)解码虽能保证生成质量,却需逐 token 串行计算,速度极为缓慢;扩散型 LLM(dLLMs)虽支持并行解码,却面
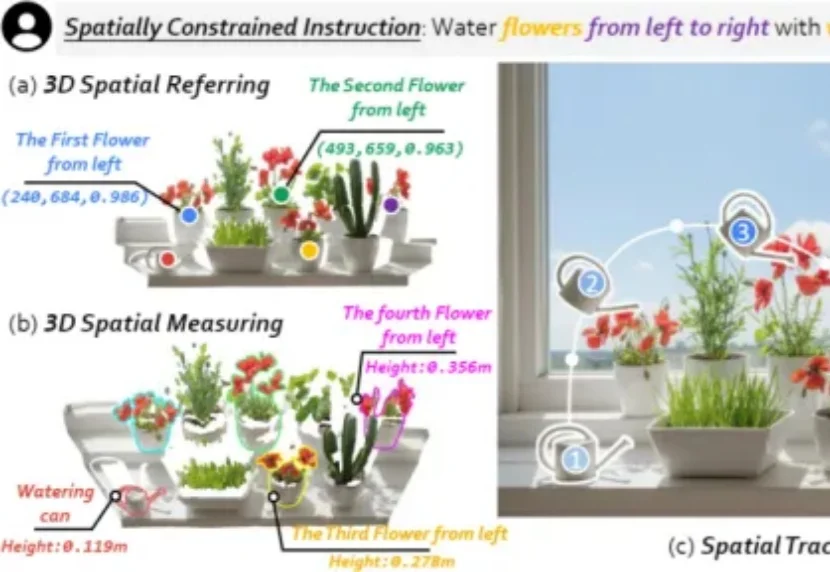
我们希望具身机器人真正走进真实世界,尤其走进每个人的家里,帮我们完成浇花、收纳、清洁等日常任务。但家庭环境不像实验室那样干净、单一、可控:物体种类多、摆放杂、随时会变化,这让机器人在三维物理世界中「看懂并做好」变得更难。

作为一名 AI 领域的博士生,徐玉庄的经历比较特殊。本科毕业于国防科技大学,随后在部队工作了 5 年,接着在清华大学获得硕士学位,目前在哈尔滨工业大学读博。
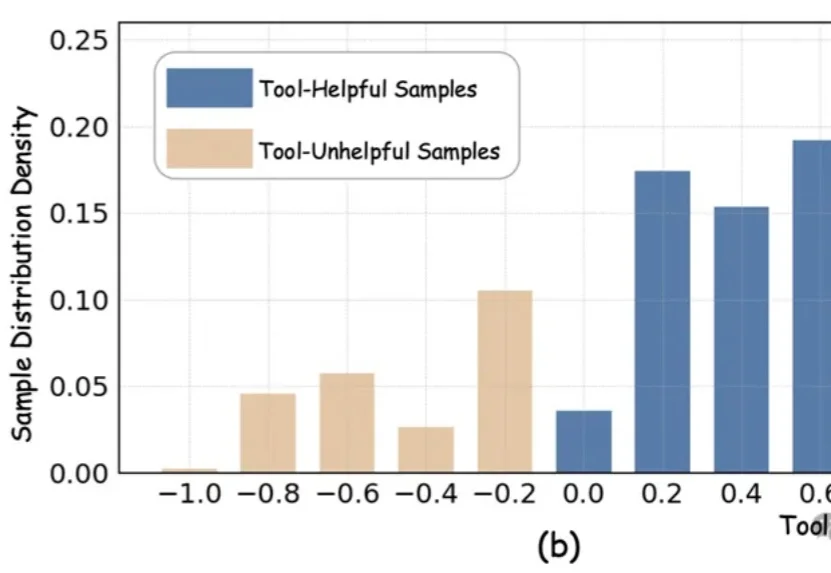
近期,以DeepEyes、Thymes为代表的类o3模型通过调用视觉工具,突破了传统纯文本CoT的限制,在视觉推理任务中取得了优异表现。
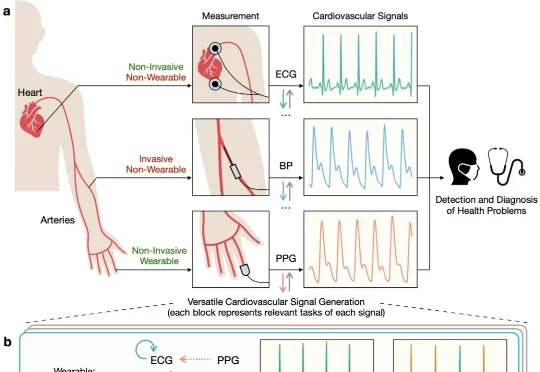
近日,清华朱军等团队提出了一种统一的多模态生成框架 UniCardio,在单扩散模型中同时实现了心血管信号的去噪、插补与跨模态生成,为真实场景下的人工智能辅助医疗提供了一种新的解决思路。
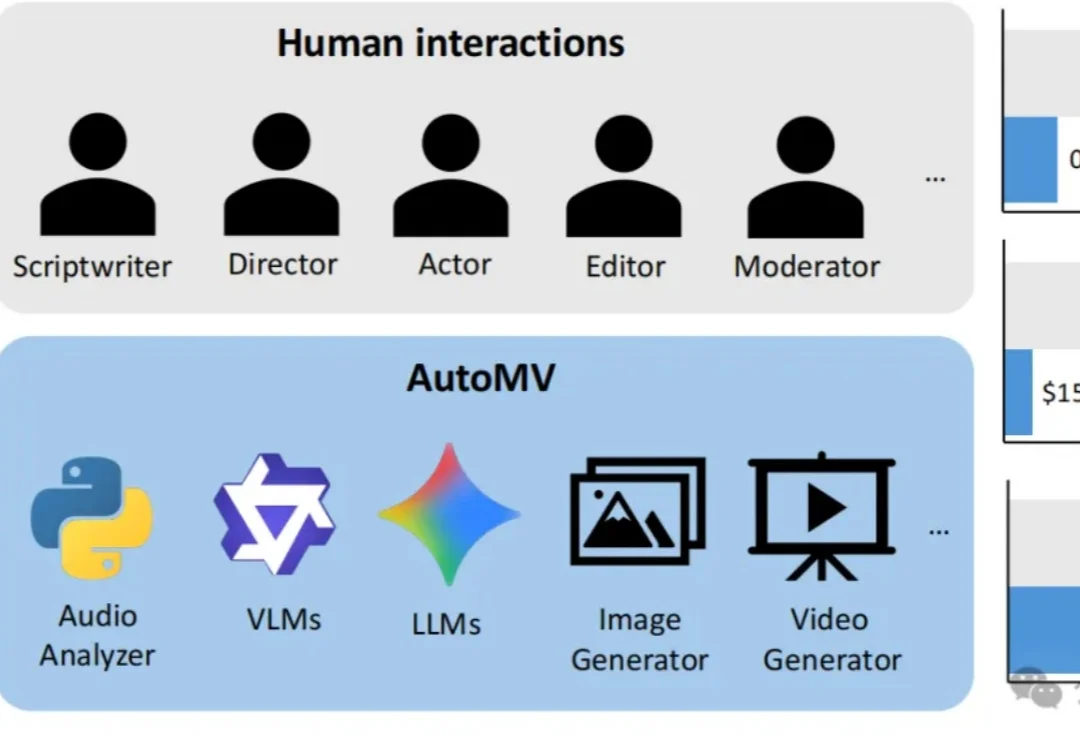
现有的AI视频生成模型虽然在短片上效果惊人,但面对一首完整的歌曲时往往束手无策——画面不连贯、人物换脸、甚至完全不理会歌词含义。
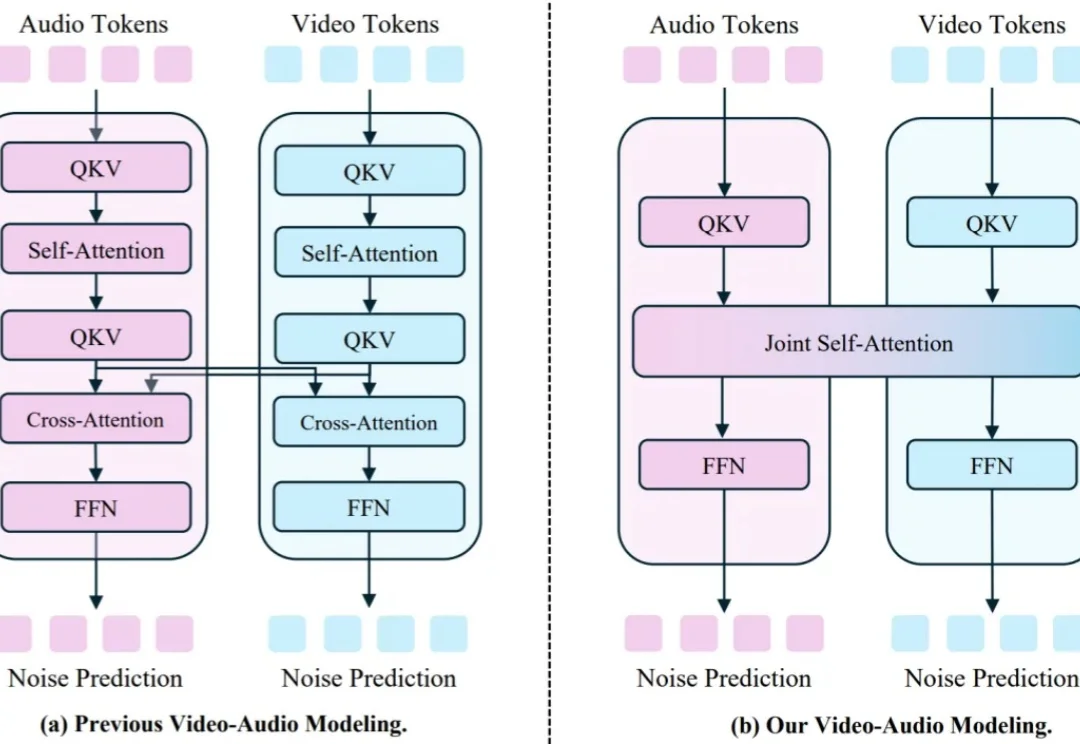
视频 - 音频联合生成的研究近期在开源与闭源社区都备受关注,其中,如何生成音视频对齐的内容是研究的重点。
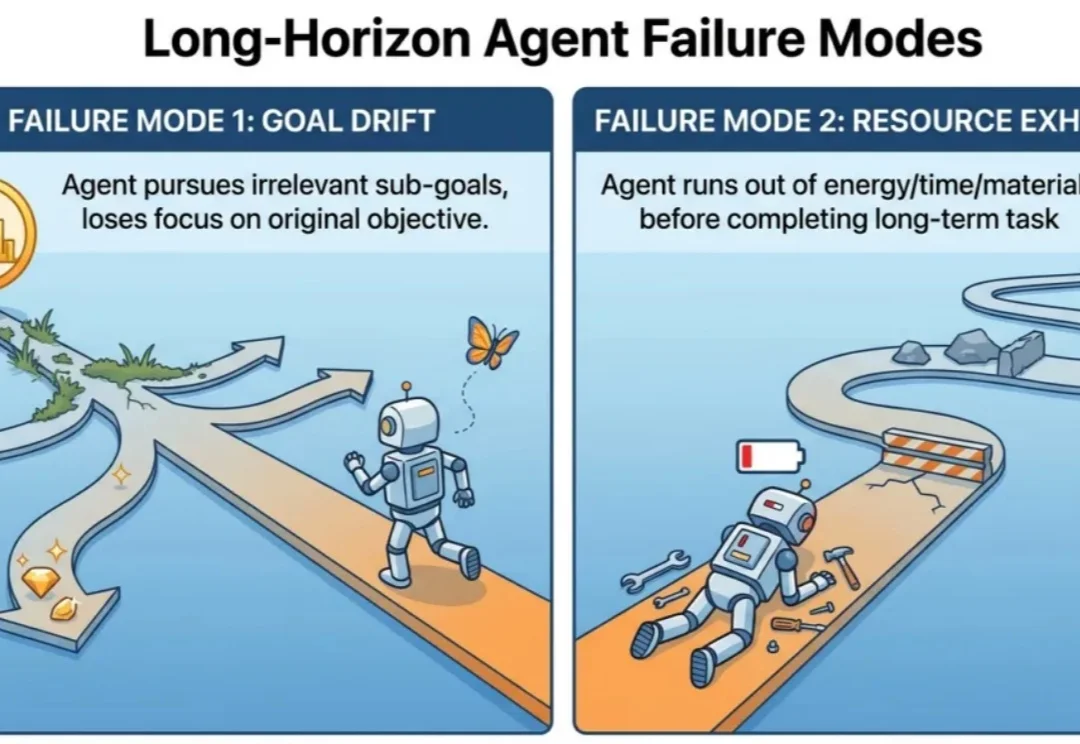
做agent简单,但是做能落地的agent难,做能落地的长周期agent更是难上加难!

在空间智能(Spatial Intelligence)飞速发展的今天,全景视角因其 360° 的环绕覆盖能力,成为了机器人导航、自动驾驶及虚拟现实的核心基石。然而,全景深度估计长期面临 “数据荒” 与 “模型泛化差” 的瓶颈。