
LeCun创业0产品估值247亿,回应谢赛宁入伙
LeCun创业0产品估值247亿,回应谢赛宁入伙新公司名为Advanced Machine Intelligence(AMI),也就是先进机器智能,法语里意为“朋友”。总部位于巴黎,并将在纽约、蒙特利尔、新加坡等地分别设立运营机构。而且和硅谷最近的闭源趋势不同,AMI all in开源。
来自主题: AI资讯
9849 点击 2026-01-23 16:25
 搜索
搜索
新公司名为Advanced Machine Intelligence(AMI),也就是先进机器智能,法语里意为“朋友”。总部位于巴黎,并将在纽约、蒙特利尔、新加坡等地分别设立运营机构。而且和硅谷最近的闭源趋势不同,AMI all in开源。
要说真学术,还得看推特。
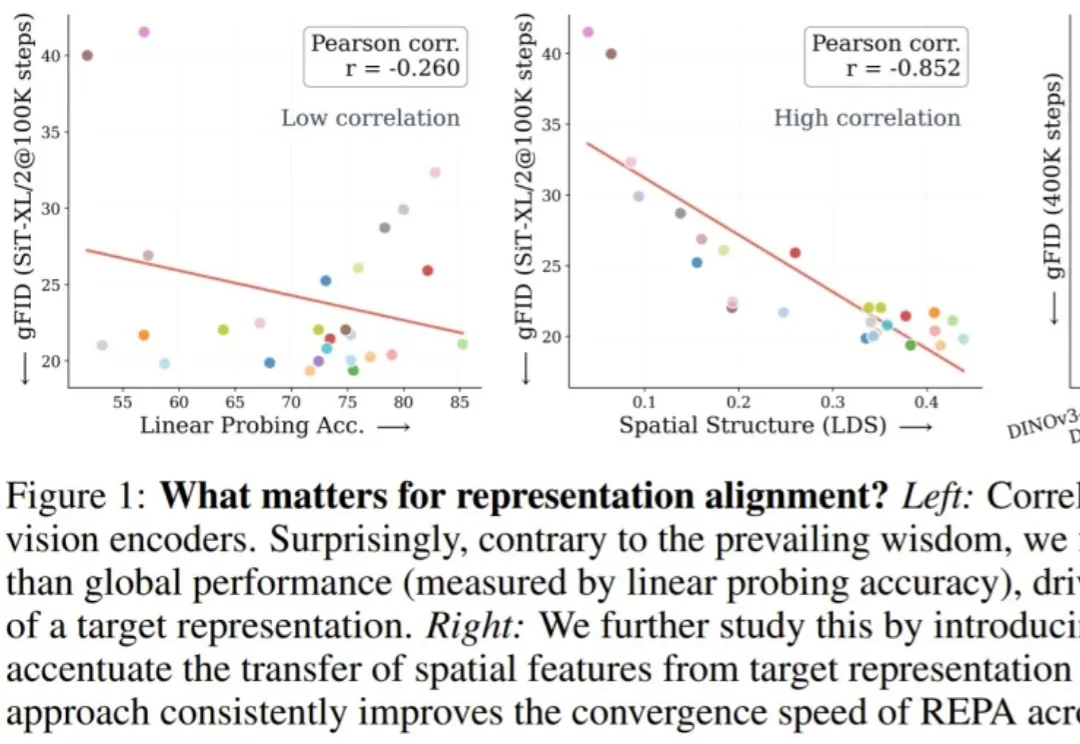
邹忌曾经有一个问题:吾与徐公孰美?

前些天,一项「AI 传心术」的研究在技术圈炸开了锅:机器不用说话,直接抛过去一堆 Cache 就能交流。让人们直观感受到了「去语言化」的高效,也让机器之心那条相关推文狂揽 85 万浏览量。参阅报道《用「传心术」替代「对话」,清华大学联合无问芯穹、港中文等机构提出 Cache-to-Cache 模型通信新范式》。
“寒武纪”这个名字在AI圈里火得发烫。

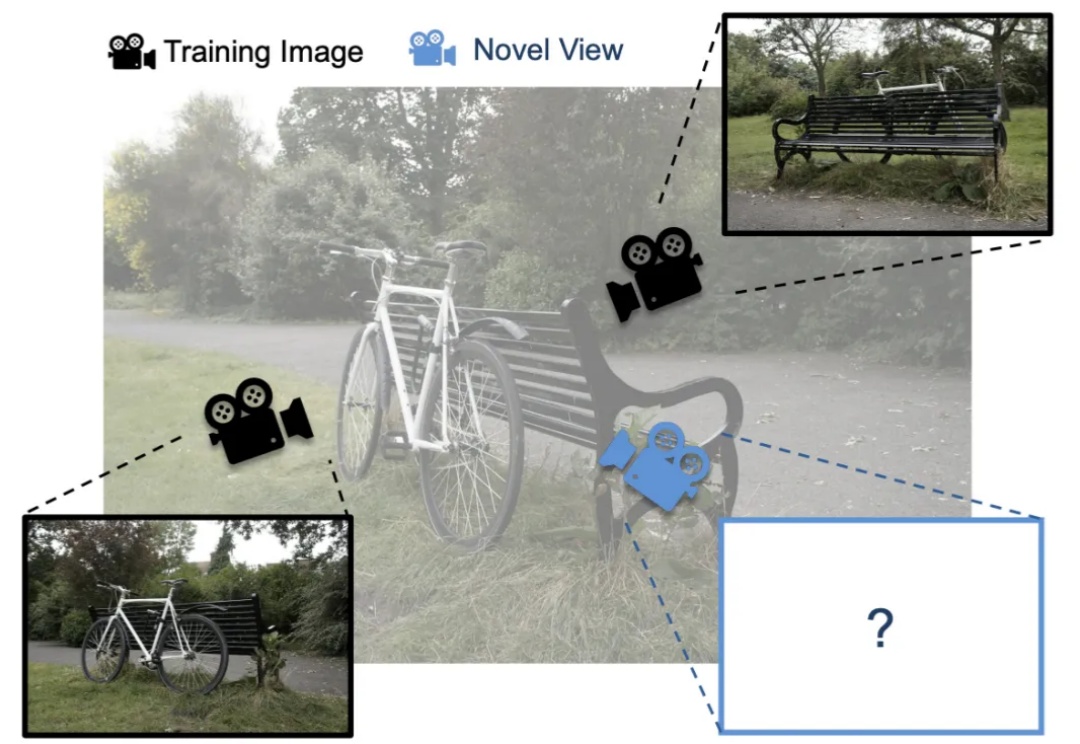
单Transformer搞定任意视图3D重建!

机器之心报道 编辑:泽南、杨文 现在,只需要一个简单的、用深度光线表示训练的 Transformer 就行了。 这项研究证明了,如今大多数 3D 视觉研究都存在过度设计的问题。 本周五,AI 社区最热
3D Gaussian Splatting (3DGS) 是一种日益流行的新视角合成方法,给定 3D 场景的一组带位姿的图像(即带有位置和方向的图像),3DGS 会迭代训练一个场景表示,该表示由大量各向异性 3D 高斯体组成,用以捕捉场景的外观和几何形状。

当AI不再对着文字死记硬背,而是学会在视频里对人类世界进行超感知,这套全新范式会不会撬开AGI的大门?

去年,谢赛宁(Saining Xie)团队发布了 Cambrian-1,一次对图像多模态模型的开放式探索。但团队没有按惯例继续推出 Cambrian-2、Cambrian-3,而是停下来思考:真正的多