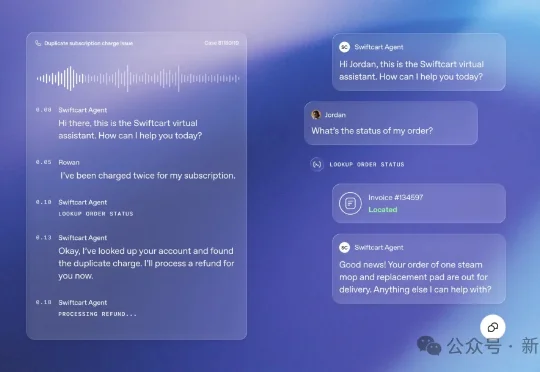
OpenAI发布新产品,亲自下场搅动千亿市场
OpenAI发布新产品,亲自下场搅动千亿市场AI 客服在最近两年被认为是 Agent 商业化落地的为数不多的最佳场景之一,借助 RAG 技术,成本远低于人工客服,也让我们过上了被迫绞尽脑汁「转人工」的生活。
来自主题: AI资讯
10180 点击 2026-07-27 11:31
 搜索
搜索
AI 客服在最近两年被认为是 Agent 商业化落地的为数不多的最佳场景之一,借助 RAG 技术,成本远低于人工客服,也让我们过上了被迫绞尽脑汁「转人工」的生活。
当大模型 Agent 被部署到工具调用、长程任务和开放环境中,一个关键问题会随之出现:能否在不更新模型参数的情况下,将执行经验沉淀下来,并在下一次做得更好?
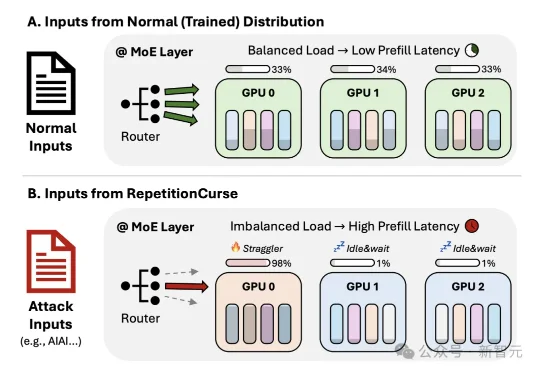
来自港科大的研究团队提出了RepetitionCurse,这是一种针对MoE大模型服务的黑盒压力测试方法。它不需要模型权重,不需要梯度,也不需要知道后端专家如何部署,只利用高度重复的输入模式,就能诱导专家路由把大量token路由到同一小批专家上。

终于,现学现用的风也是吹到了具身智能。

4月30号,快手Krow团队推出了一款桌面端AI智能体KroWork,在这里你不用写一行代码,对着它说一句话,它就能自己写代码、调试、部署,最后交付一个能直接在桌面运行的应用。
这家名为 PrismML 的初创公司表示,已将 Qwen 3.6 缩减至可在 iPhone 17 Pro 上运行,该模型拥有 270 亿参数(参数大致类似于大脑中的突触,能够帮助决定模型可处理数据的复杂性)。相比之下,大多数在手机上运行的模型一次仅有几十亿个参数处于活动状态。

今天,OpenAI的“二号人物”、曾主导OpenAI战略转型的AGI部署CEO Fidji Simo在一封内部信中宣布,她已决定辞去在OpenAI的全职职务,成为OpenAI的兼职顾问。外界原本普遍预计,此前曾领导OpenAI产品和业务部门的Simo,会在OpenAI上市后担任更重要的领导角色。

Broadcom 周一表示,将在一项扩展协议中为 Apple 提供定制芯片,该协议将持续至 2031 年。两家公司已签署一项新的多年期协议,博通将开发定制 ASIC 芯片,即专用集成电路(application-specific integrated circuit)。

两年后,Fable 5 级 AI,可能就躺在你的笔记本里。就在昨天,全球最大的本地大模型社区r/LocalLLaMA,一张图刷屏了整个AI圈——标题简单粗暴:如果趋势持续,Mythos级能力可能在2年内运行在高端消费级硬件上。

UC Berkeley团队提出的端到端流程旨在解决该问题,研究团队跑通了首条能够从网络视频生成真实灵巧手实机执行轨迹的完整链路:先从真实场景中的单目RGB视频中重建4D手-物交互过程,再将这些交互轨迹重定向到拥有22个自由度的Sharpa Wave灵巧手上。