
把 Kimi 接进 Codex ,小白用 Agent 的最好选择
把 Kimi 接进 Codex ,小白用 Agent 的最好选择如果是小白第一次上手,我会更建议从 Kimi 开始。Kimi 的中文理解、长文本处理、Coding、多模态综合能力都很强,是最适合 Codex 的国产模型。今天这篇内容,手把手教大家如何将第三方大模型接入 Codex 搞定日常任务。
来自主题: AI资讯
10419 点击 2026-07-05 11:05
 搜索
搜索
如果是小白第一次上手,我会更建议从 Kimi 开始。Kimi 的中文理解、长文本处理、Coding、多模态综合能力都很强,是最适合 Codex 的国产模型。今天这篇内容,手把手教大家如何将第三方大模型接入 Codex 搞定日常任务。

从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。

ElevenLabs的声音克隆和长文本音频生成质量确实很好,但也太贵了。
ElevenLabs的声音克隆和长文本音频生成质量确实很好,但也太贵了。

英伟达提出了全球首个三模式的大语言模型系列,只需简单更改注意力模式 / 掩码,即可在自回归、扩散和自推测解码之间切换。一个模型,三种解码模式,没有额外的草稿模型,没有架构变更。最快的模式 token 吞吐量能提升 4 倍。
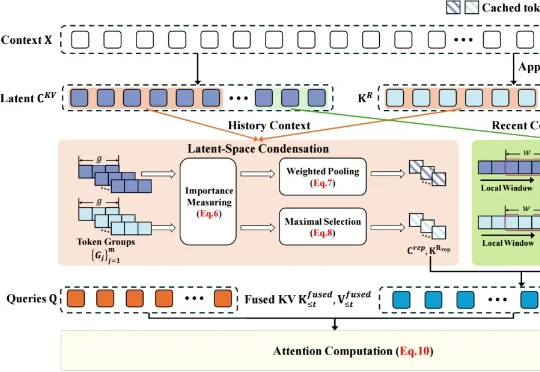
近日,琶洲实验室、华南理工大学、蔻町(AIGCode)等单位科研团队联合提出潜在空间压缩注意力(Latent-Condensed Attention,LCA),研究成果入选 ACL 2026。

在 AI 工程界,长文本推理一直是个“富贵病”。

龙虾终于会画图了!阿里Wan2.7-Image刚刚上线,捏脸到骨相级、首创「调色盘」、3K超长文本写满A4不崩,还能接入OpenClaw一句话出图。

MLRA通过拆分KV缓存为四个并行分支,显著降低显存占用并实现4路张量并行。推理速度比MLA最高快2.8倍,支持百万级上下文,且模型质量更优。无需牺牲性能,即可高效扩展长文本处理能力。

来自阿里高德的一篇最新 ICLR 2026 中稿论文《Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models》提出了面向文生图空间智能的系统性评估基准 SpatialGenEval,旨在通过长文本、高信息密度的 T2I prompt 设计,以及围绕空间感知