
作业帮出海最猛的产品竟是AI陪伴?单月访问量超4200万,AI百强榜排名超Kimi、千问
作业帮出海最猛的产品竟是AI陪伴?单月访问量超4200万,AI百强榜排名超Kimi、千问当国内的AI大模型战场正陷入“百模大战”的焦灼,巨头们还在比拼参数规模、长文本处理能力和代码生成率时,一家曾经被打上“在线教育”和“题库工具”深深烙印的公司——作业帮,却在海外市场“悄悄”通过一条意想不到的赛道杀出了重围。
来自主题: AI资讯
10592 点击 2026-01-19 09:36
 搜索
搜索
当国内的AI大模型战场正陷入“百模大战”的焦灼,巨头们还在比拼参数规模、长文本处理能力和代码生成率时,一家曾经被打上“在线教育”和“题库工具”深深烙印的公司——作业帮,却在海外市场“悄悄”通过一条意想不到的赛道杀出了重围。
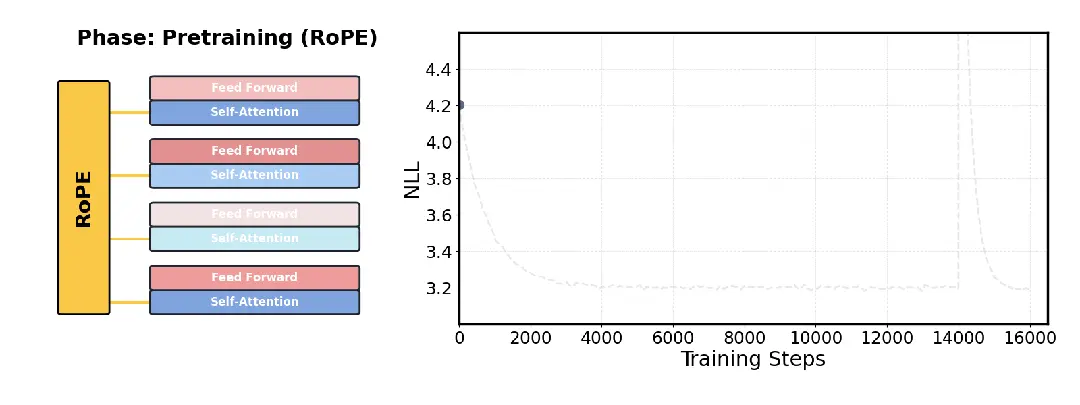
针对大模型长文本处理难题,Transformer架构的核心作者之一Llion Jones领导的研究团队开源了一项新技术DroPE。

256K文本预加载提速超50%,还解锁了1M上下文窗口。
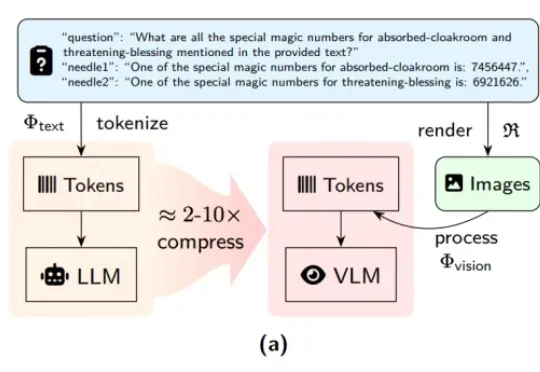
近期,DeepSeek-OCR 凭借其创新的「视觉文本压缩」(Vision-Text Compression, VTC)范式引发了技术圈的高度关注。为了解答这一疑问,来自中科院自动化所、中国科学院香港创新研究院等机构的研究团队推出了首个专门针对视觉 - 文本压缩范式的基准测试 ——VTCBench。

DeepSeek-OCR的视觉文本压缩(VTC)技术通过将文本编码为视觉Token,实现高达10倍的压缩率,大幅降低大模型处理长文本的成本。但是,视觉语言模型能否理解压缩后的高密度信息?中科院自动化所等推出VTCBench基准测试,评估模型在视觉空间中的认知极限,包括信息检索、关联推理和长期记忆三大任务。
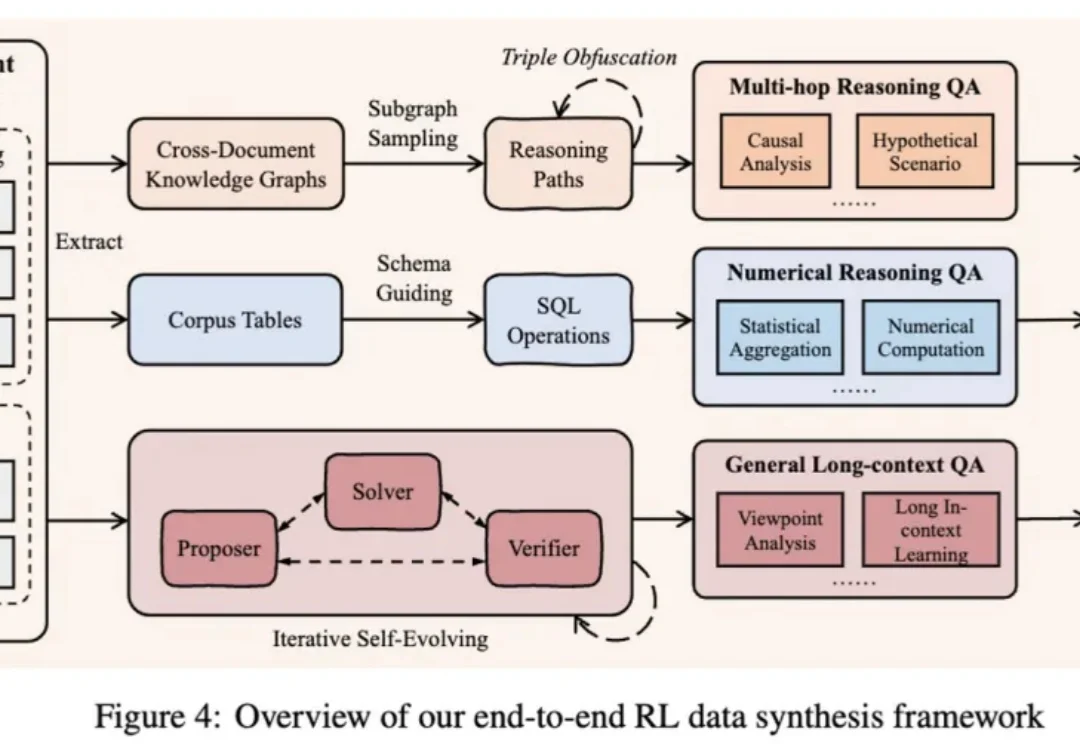
作为大模型从业者或研究员的你,是否也曾为一个模型的 “长文本能力” 而兴奋,却在实际应用中发现它并没有想象中那么智能?
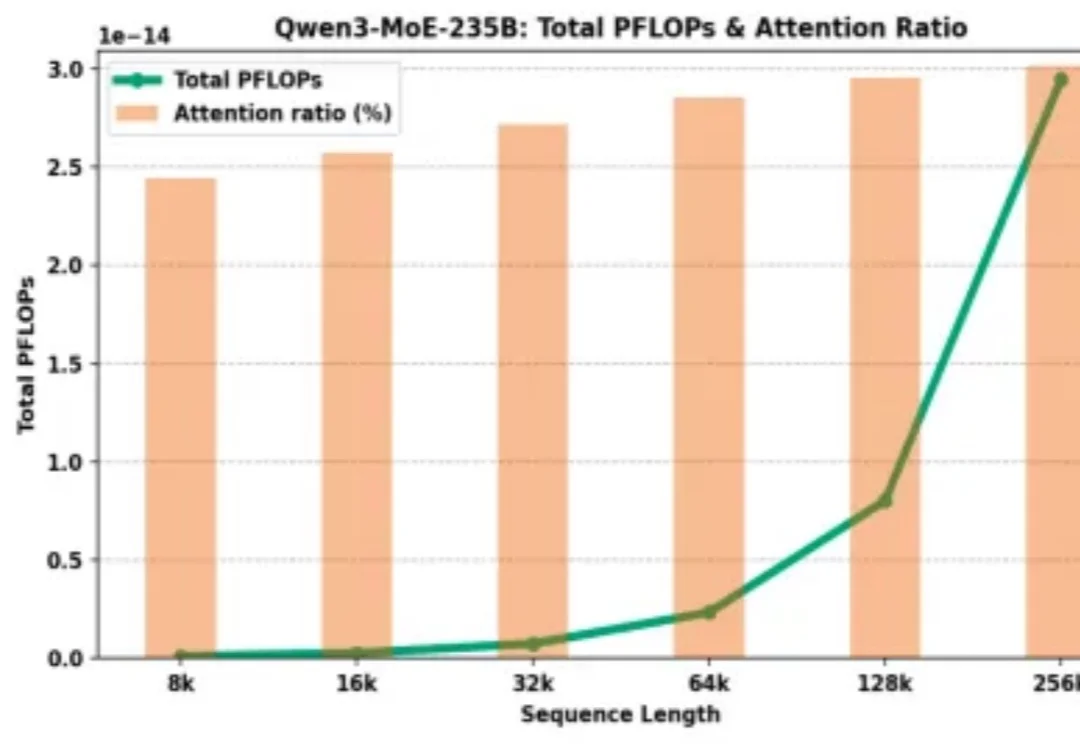
为什么大模型厂商给了 128K 的上下文窗口,却在计费上让长文本显著更贵?

在处理短文本时,大语言模型(LLM)已经表现出惊人的理解和生成能力。但现实世界中的许多任务 —— 如长文档理解、复杂问答、检索增强生成(RAG)等 —— 都需要模型处理成千上万甚至几十万长度的上下文。

在NeurIPS 2025论文中,来自「南京理工大学、中南大学、南京林业大学」的研究团队提出了一个极具突破性的框架——VIST(Vision-centric Token Compression in LLM),为大语言模型的长文本高效推理提供了全新的「视觉解决方案」。值得注意的是,这一思路与近期引起广泛关注的DeepSeek-OCR的核心理念不谋而合。

月之暗面在这一方向有所突破。在一篇新的技术报告中,他们提出了一种新的混合线性注意力架构 ——Kimi Linear。该架构在各种场景中都优于传统的全注意力方法,包括短文本、长文本以及强化学习的 scaling 机制。