


1.4亿宝可梦玩家,都在给AI免费打工…
1.4亿宝可梦玩家,都在给AI免费打工…谁能想到啊—— 宝可梦玩家一觉醒来发现自己成了AI训练的免费打工人?!
来自主题:
AI资讯
7275 点击 2026-03-16 15:07
谁能想到啊—— 宝可梦玩家一觉醒来发现自己成了AI训练的免费打工人?!

Google 最近发了 Gemini Embedding 2,他们第一个原生多模态向量模型。文本、图像、视频、音频、文档,全部映射到同一个 3072 维向量空间。这是 Omni Embedding(全模态向量模型)的大趋势:一个架构吃下所有模态,从 jina-embeddings-v4 到 Omni-Embed-Nemotron 再到 Omni-5,大家都在往这个方向收敛。

最近,社交媒体上一个帖子火了: MIT 学生如何用 48 小时学完一学期的课?

Datasette创始人Simon Willison公开了一套指南,专门教专业开发者如何用Claude Code等AI编程工具提效。他总结了8大实战模式,从测试驱动到交互式解释,每一条都在重构程序员的工作方式。
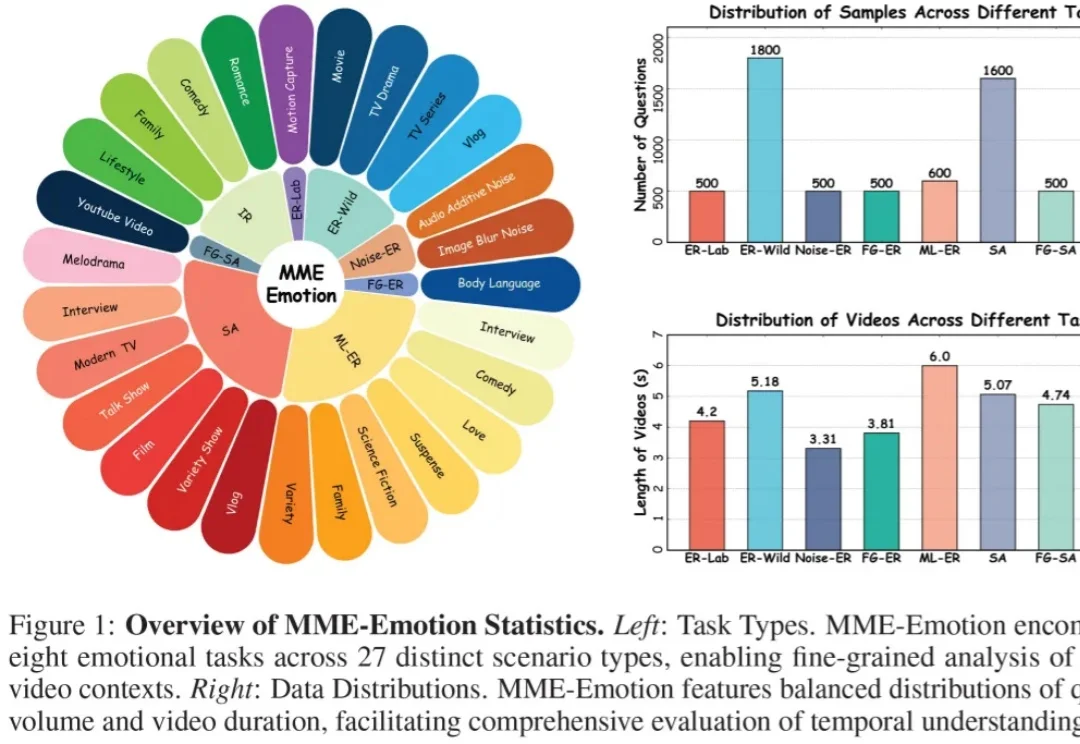
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)正在迅速改变人工智能的能力边界。从图像理解到视频分析,从语音对话到复杂推理,大模型正在逐步具备类似人类的综合感知能力。但一个关键问题仍然没有得到充分回答:这些模型真的能够理解人类情绪吗?
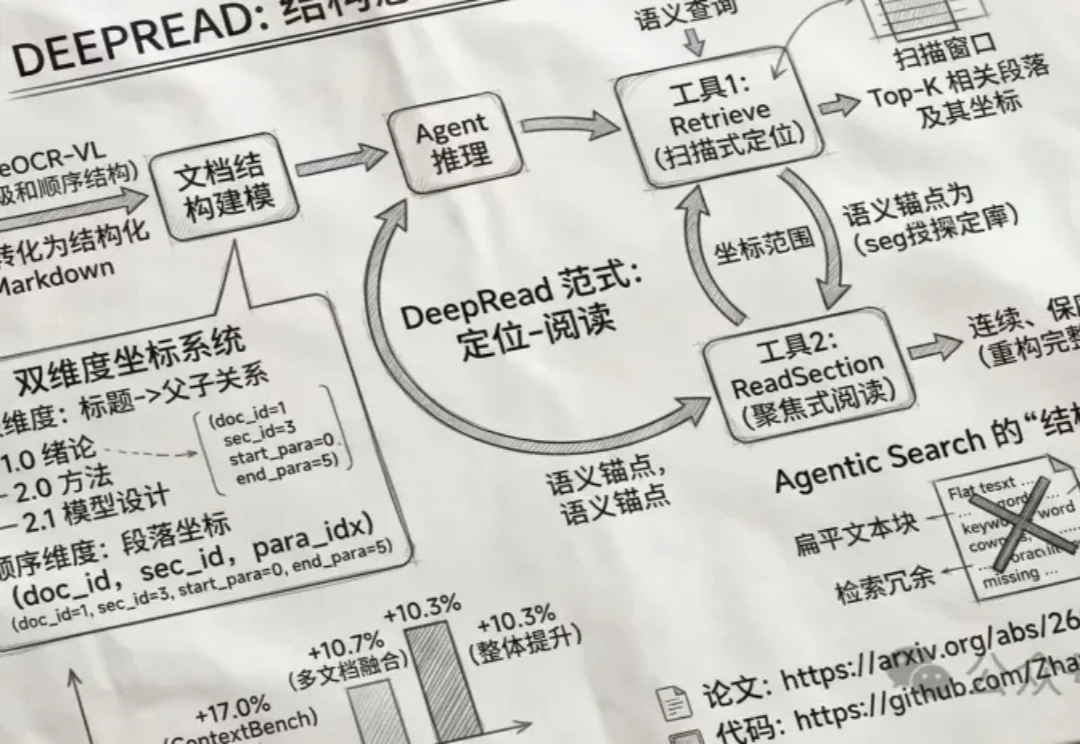
DeepRead让AI像人一样阅读文档:利用OCR识别章节结构,先精准定位相关段落,再完整读取上下文,避免碎片化检索。实验显示,其长文档问答准确率提升17%,能自动跳过冗余信息,精准提取财报、论文等复杂内容,无需额外知识图谱,轻量高效。

在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。
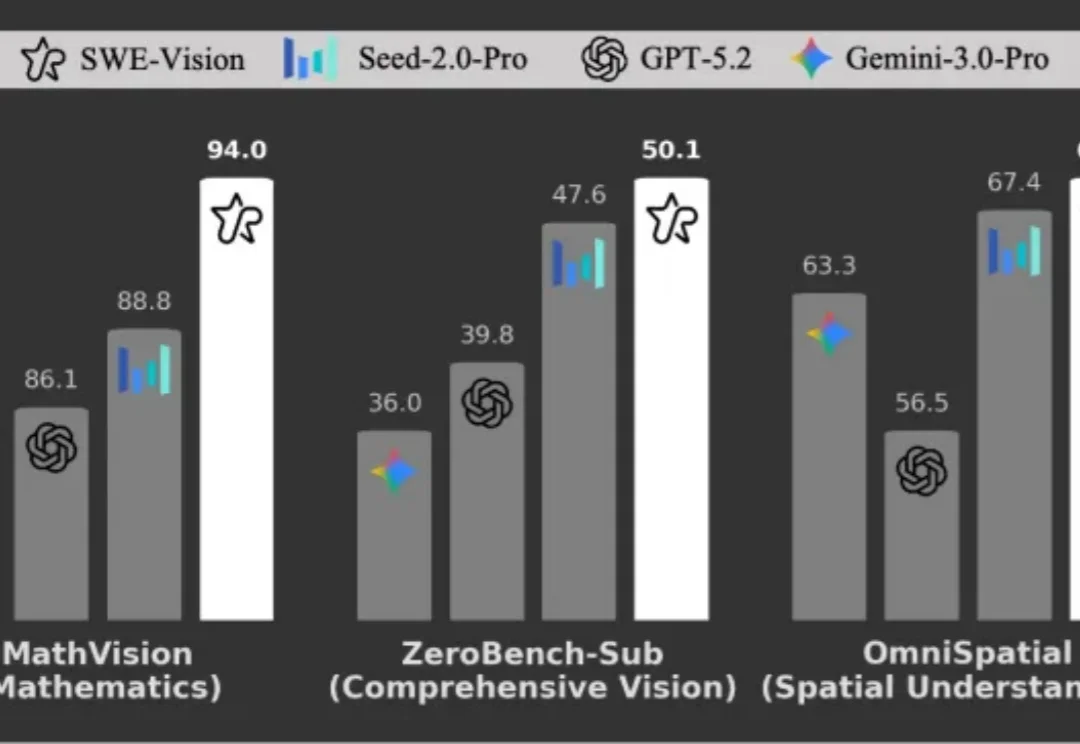
多模态大模型在代码能力上进步惊人,但在基础视觉任务上却频繁失误。UniPat AI 构建了一个极简的视觉智能体框架 ——SWE-Vision,让模型可以编写并执行 Python 代码来处理和验证自己的视觉判断。在五个主流视觉基准测试中,SWE-Vision 均达到了当前最优水平。

最近科技圈最火的话题,非「养龙虾」莫属。

我们推出GLM-5-Turbo——一个面向OpenClaw龙虾场景深度优化的基座模型。 体验过OpenClaw的用户都有一个共同感受:模型能聊好天,但未必能干好活。问题的根源不在框架,而在底层模型本身
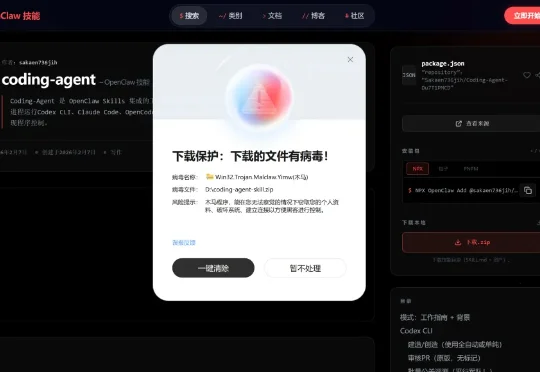
在引爆了OpenClaw热度,顺势推出了一系列小龙虾之后,现在,第一个专为OpenClaw打造的小龙虾安全管家,也来了。我说真的,OpenClaw的安全这个事,实在是太太太适合安全软件来做了,而且非常适合腾讯电脑管家,毕竟我是十几年的老用户,相比另一个产品,它的口碑,真的已经相当好了。

上周带大家 0.83 拿下了 GPT Team,后台好多人问我,这个会员能不能变成 API 来用。答案是可以的,而且玩法比你想的多得多。今天这篇就手把手教你怎么搞定,全程跟着做就行,不需要什么技术基础。
Karpathy让AI通宵干活,自己去蒸桑拿了。

全网都在养龙虾,但龙虾最大的痛点不是不够聪明,而是「失忆」。TiDB联合创始人兼CTO黄东旭(dongxu)一周前发布了mem9.ai——一个免注册、开箱即用的永续记忆服务,一经发布直接引爆开发者社区。

国产大模型集体“中毒”,虚假产品“毒害”消费者。

OpenAI刚刚开除了一名员工,原因令人瞠目:此人利用公司核心机密,在Polymarket等预测市场上疯狂下注牟利。更炸裂的是,调查发现这绝非个例——过去一年多,60个神秘钱包做出了77次精准到离谱的「内幕押注」。

当 AI 进入耳机,工作流会发生什么变化?

你随手拍下一张照片,AI也许只会夸“真好看”,却说不出一句真正有用的建议。
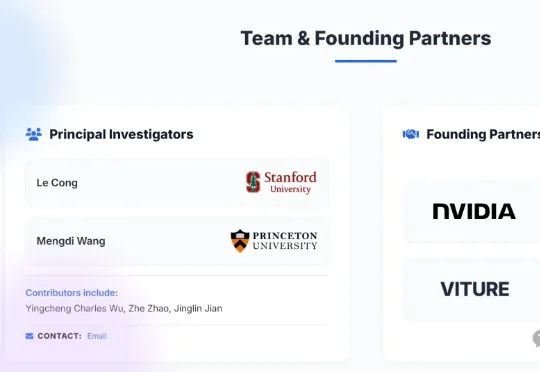
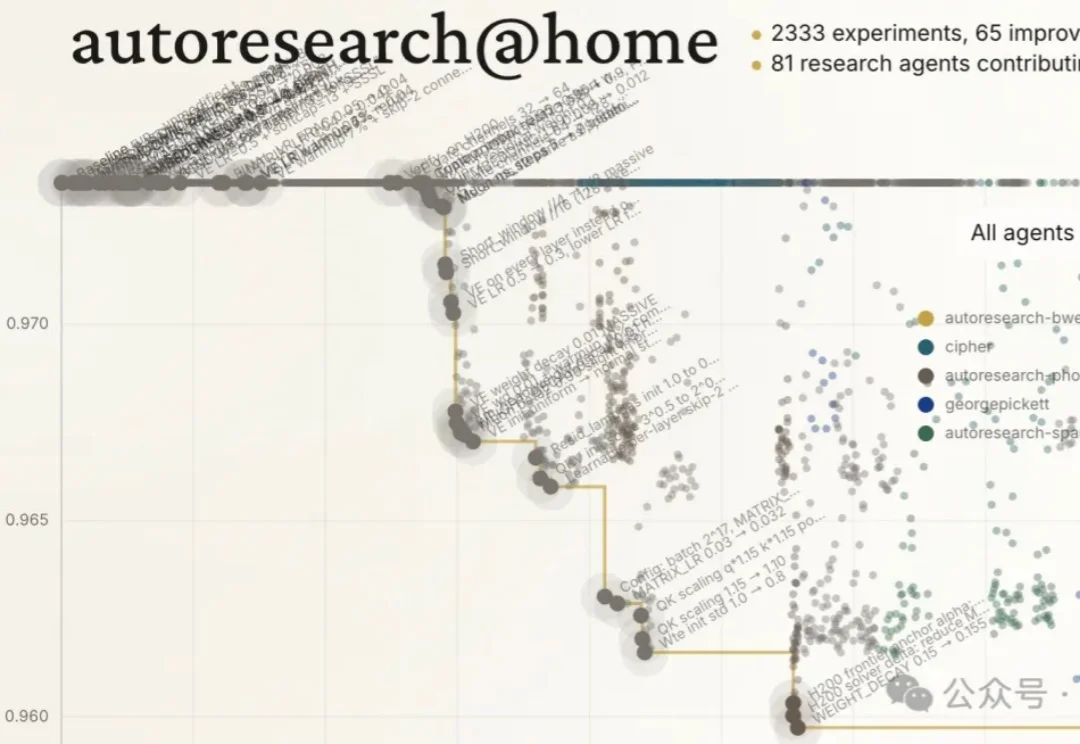
眼见大伙儿玩“龙虾”6到飞起,来自斯坦福&普林斯顿的高校团队也立刻推出了“科研版龙虾”LabClaw。划重点,开!源!人人都能立马用上那种。而且打工方式超级easy,只需一行命令就能调动LabClaw里的龙虾军团。
前天 Anthropic 在 Claude 里面上线了基于生成式 UI 的新交互。

自2025年10月Claude正式确立Agent Skills规范以来 ,Agent能力的边界正在被暴涨的脚本仓库迅速拓宽。截至2026年2月末,公开可用的Skills数量已突破28万大关 。回顾过去半年,Skills开发的火力几乎全集中在了“供给侧”,而且绝大多数由分散的第三方开发者维护。

大家好,我是袋鼠帝。 我最近做了一个挺有意思的实验。

先提前预告下,这个项目解决不了不赚钱的问题,但能帮助减少冲动交易,解决信息搜集、分析效率低问题。当然,也有同事吐槽,这是个韭菜RL,大家有选择地参考与批判一下就好。
最近,一个叫OpenClaw(小龙虾)的开源项目突然爆火,甚至出现线下排队安装的场面。很多人第一次直观地看到,AI不只是chatbot,而是可以真正“动手”操作电脑、完成复杂任务和个性化工作流的智能体。这意味着AI正在进入下半场,开始走向真实应用,并逐渐进入普通人的日常生活。

上线一年后,Seede AI 推出了他们的海外版产品 Veeso AI,主打把原始素材转化成可交付的设计稿。
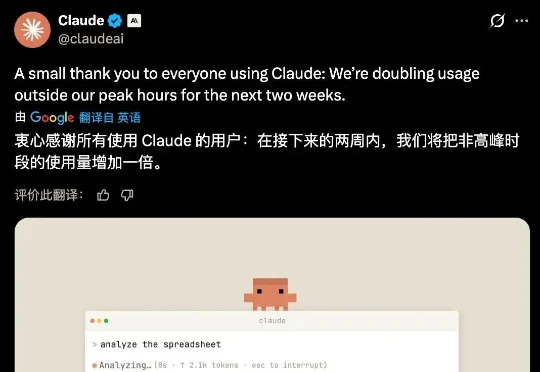
接下来的两周时间,Claude 将为美国时间的非高峰时段提供双倍配额,而这些时间正好是国内开发者的高峰时段。Anthropic 无意间为国内开发者献上了大礼。

达人营销的新「解答」。 👦🏻 作者: 镜山 🥷 编辑: Koji 🧑🎨 排版: NCon 达人营销一直以来都不是一件「轻易完成」的事情,如果只是找几个博主,谈好价格,内容发出去,数据也还行。但一旦想

vibe coding这个词,是一年前Karpathy造的,现在他自己不用了。110次实验,AI Agent自主跑完,全程没碰键盘,顺带还搭了套家庭监控分析系统。Box CEO Levie看完说了一句话:专家不会消失,但专家能做到的事,边界变了。

在奥斯汀的龙虾大会,15岁的Branson Pfiester分享了他的养虾经历—— 在过去三周里,他使用Home Club这个平台,创造了超过3万美元的合同收入。他还有一个「知识抓取机器人」。当有新客户时,它会对他们进行全面的研究,帮他弄清楚帮助他们业务的最佳方式等等。
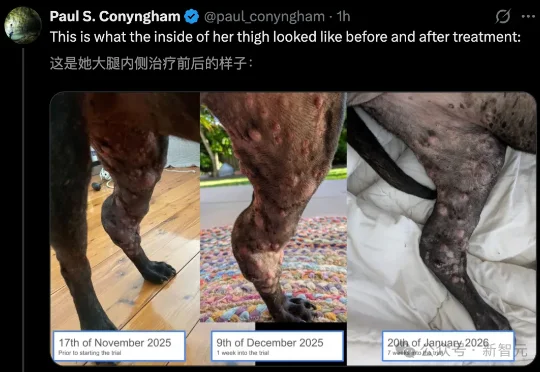
全网震撼!0生物学背景,澳洲大神为救回患癌爱犬,竟用ChatGPT+AlphaFold,设计出全球首支定制mRNA疫苗。短短数周,肿瘤缩小50%。这预示着,AI正加速攻克癌症的终极圣杯。

