
Agent 刚拿到自己的邮箱和钱包,人类的收件箱已经挤爆了
Agent 刚拿到自己的邮箱和钱包,人类的收件箱已经挤爆了Agent 正在逐渐获得「人权」。
来自主题: AI资讯
7216 点击 2026-06-30 10:45
 搜索
搜索
Agent 正在逐渐获得「人权」。
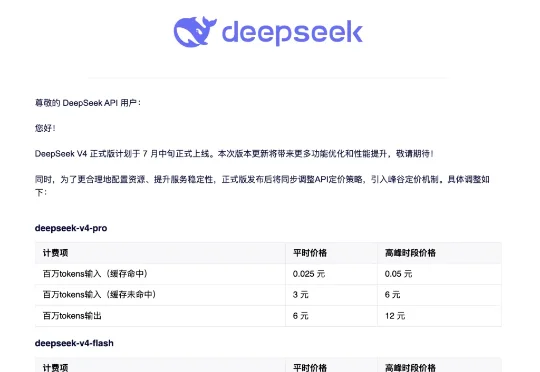
记者获悉,DeepSeek宣布价格调整,引入峰谷计费机制:以DeepSeek-v4-pro为例,其输入价格(缓存命中)平时为0.025元/百万tokens,高峰时期为0.05元/百万tokens;输入价格(缓存未命中)平时为3元/百万tokens,高峰时期为6元/百万tokens;输出价格平时为6元/百万tokens,高峰时期为12元/百万tokens。

Z Potentials独家获悉,柔性具身智能公司深圳擎羽科技有限公司(以下简称:擎羽科技)已完成 Pre-A 轮融资。本轮融资由顺为资本、五源资本联合投资,高鹄资本担任独家财务顾问。这也是继德迅投资、东方富海等一线机构相继出手后,擎羽科技在半年内完成的第三轮融资。

6月22日Claude全家桶集体宕机,只是冰山一角。当最强大模型被丢进真实机房直面「幽灵故障」,AISHPerf-智算运维智能体评测基准给出残酷答案:全军覆没,无一过50分。这道鸿沟,第一次被量化。
周末跟几个之前的老朋友吃饭。 大家也都不由自主的聊到了AI,然后也聊到了Vibe Coding。

2026年,具身智能迎来融资狂潮。

独家获悉,清华系初创公司「厘清智能」宣布完成数亿元种子轮融资,投资方阵容堪称豪华:由顺为资本、红杉中国、高瓴创投、峰瑞资本、星连资本、水木清华校友种子基金、SEE FUND等一线基金,与智元机器人、灵心巧手、世纪金源等产业资本共同投资。其中,顺为资本与红杉中国更是连续多轮追加投资。
Patronus AI 今天官方宣布公司完成由 Greenfield Partners 领投的 5000 万美元 B 轮融资,Lightspeed Venture Partners、Notable Capital、Datadog、三星、Gokul Rajaram、Factorial Capital 以及来自我们实验室和新实验室的众多人工智能领军人物也参与了本轮融资。

AI时代:认知>格局>技术>管理。

2026年6月23日,字节跳动CEO梁汝波罕见地出现在火山引擎FORCE原动力大会的视频画面中。他没有选择现场登台,但视频透露了一个关键:“攀登AI高峰是字节当下最重要的事情”。紧接着,他补了一句更关键的判词:过去几年,字节一直在“聚焦收缩业务宽度”,把精力重点放到AI,在AI领域聚焦到提升模型能力。
德塔智能试图为双足人形机器人构建能够理解空间、协调全身并完成真实任务的基础模型。 原生人形机器人基础模型公司德塔智能(Delta Intelligence)近日已连续完成种子+轮、天使轮及天使+轮融资。

就在今天凌晨,哈佛博士Douglas Yao在X宣布,研发了一款针对阿尔茨海默病的新药PAC-832,引发了数百人的围观。这是世界上第一个选择性GalR1拮抗剂,创始人表示全程使用了机器人自动化技术和AI大模型。
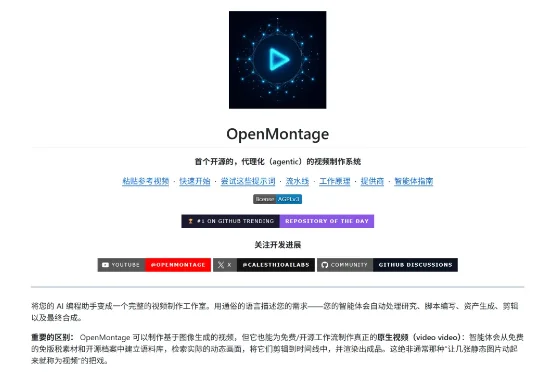
没错,我说的就是从6月下半旬开始在Github上爆火的OpenMontage。这是一个专门用来给AI视频生成准备的Harness工具,你把你的提示词给它,它就能自动帮你完善成专业的AI视频生成提示词,并且还配有剪辑、配音等等一系列后期工作。

今日,半导体研究机构SemiAnalysis爆料,AI大牛、阿里云前副总裁、LeptonAI创始人兼CEO贾扬清已离开英伟达。SemiAnalysis猜测,贾扬清离开的原因可能是其联合打造的AI超级计算云服务DGX Lepton失败了,未达到英伟达创始人、CEO黄仁勋预期的成功。

一句话拍短剧!AI界「价格屠夫」Agnes AI,刚刚上线免费创作平台Pavo。Agent自动包揽从剧本到成片的全流程,带你零成本体验「一键成片」,彻底颠覆创作门槛!
这两年总有人来问我同一个问题。

国内具身智能赛道再次迎来重要时刻。

什么是DeepSeek开启融资的直接导火索?
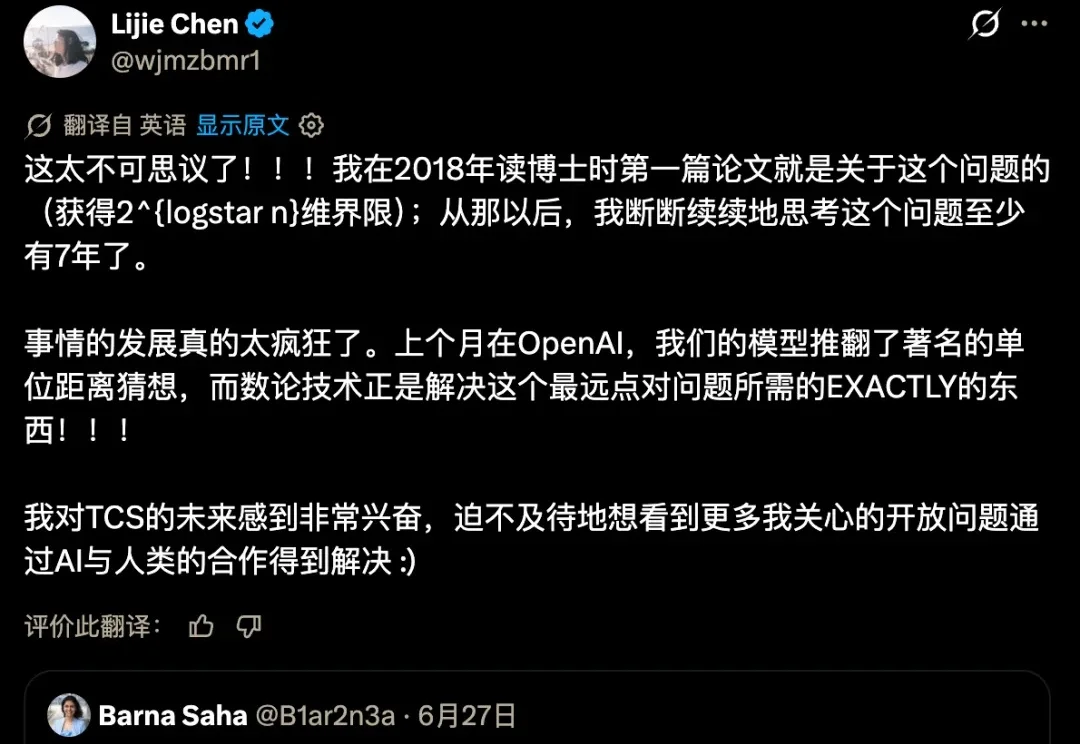
GPT-5.5 Pro 生成了一个数学证明,解决了计算几何中一个 陈立杰苦思 7 年未解的核心难题。关键技术来自 OpenAI 上月的另一项突破,而最初推进这个问题的陈立杰发现,钥匙竟是自己参与的工作。

中国空调,在欧洲被抢疯了。
这个周末,智谱没闲着。
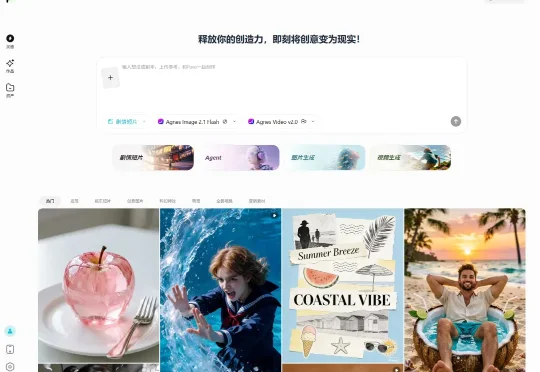
自从 6 月 1 日宣布全部旗下旗舰模型 API 免费之后,文本、图片、视频这三个模型我都一直在用,确实帮我省了很多钱,同时模型能力也不错。而最近,Agnes AI 又双叒叕搞了个新平台:Pavo。
最近另一个叫「马尾辫」的项目在 GitHub 上开始被疯狂下载,直接拿下了 GitHub 热门榜单连续三周的周榜第一。这个项目的介绍图也特别有意思,在项目描述里写着,你一定认识他,长长的马尾辫,椭圆形眼镜,在公司待的时间比版本控制系统的历史还长。你给他看五十行代码;他看了看,什么也没说,然后只用一行替换掉。

最近,这个AI穿越Vlog刷爆全网!第一视角空降古罗马、泰坦尼克号,逼真到窒息。历史次元壁被打破的那一瞬间,很多「亲历现场」的观众,开始落泪了。

什么是AI原生支付?随着全世界个体token的消耗量猛增,越来越多的大玩家和初创公司开始瞄准AI支付机制和基础设施的问题。

2026年6月,全球AI算力产业最焦虑的事情,不是英伟达Rubin能不能按时出货,也不是台积电CoWoS产能够不够——而是一台大多数人根本没听说过的机器:日本丰田工业的喷气织布机。
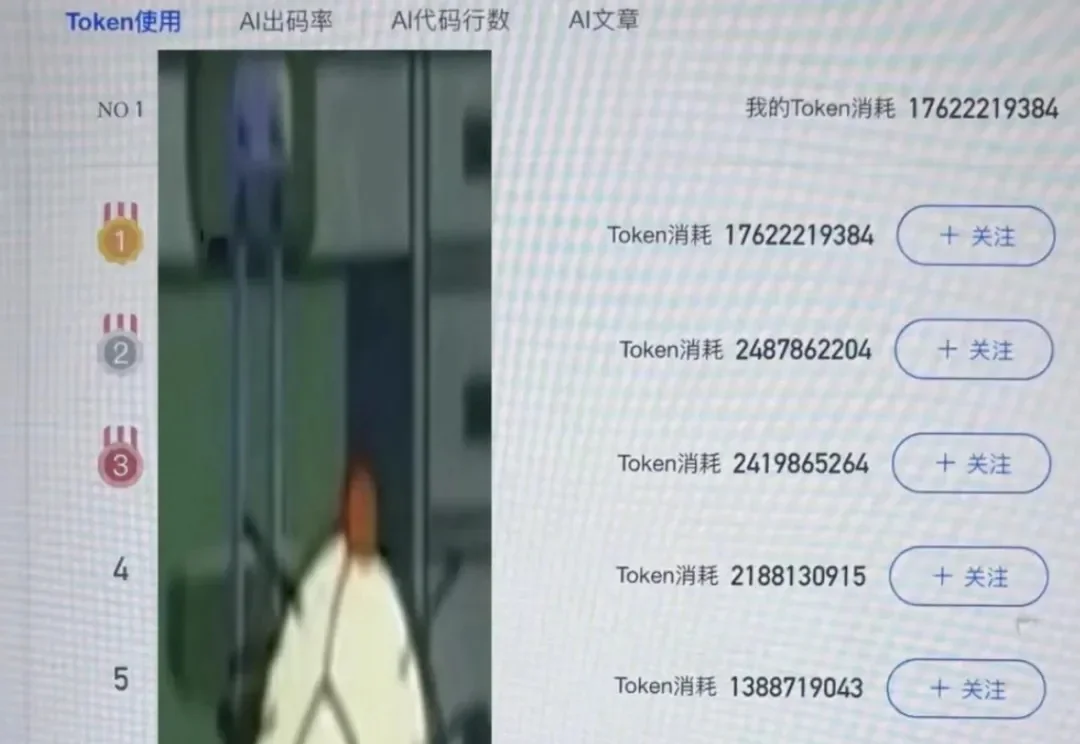
不用够token会被骂,AI生成率必须大于80%,谁在强制打工人用AI?

《读佳》获知,高德在内测一款Vibe Coding产品“袋马”(“代码”的谐音梗),主打自然语言驱动的零门槛应用构建能力,聚焦小程序与iOS原生应用场景,可快速生成可直接上线、真机可用的应用产品。截至目前,高德官方尚未对外披露该产品的正式上线时间、行业合作模式及商业化细则,相关产品动态仍处于内测阶段。

最后一个GPT-4走了。4个半月,OpenAI清空整个GPT-4家族,GPT-4.5是其中最后一个退场的。没有告别,只有一行更新日志——一个模型的退役,正在变成AI圈的日常。
独家获悉,被称为“最像特斯拉”的具身智能公司智平方近日已完成新一轮融资,总额近50亿元人民币,估值突破200亿。据了解,本轮投资方阵容横跨国家队、大湾区产业资本、保险公司、头部券商及多家特斯拉供应链企业。公开数据显示,智平方此轮融资是迄今国内具身智能赛道单次披露金额最大的融资之一。