
刷榜多元时序预测,性能波动0%!打破CI/CD二元对立 | ICLR'26
刷榜多元时序预测,性能波动0%!打破CI/CD二元对立 | ICLR'26ICLR'26新研究CPiRi打破时序预测僵局:用冻结底座提取时序特征,轻量模块专注学习通道间真实关系,不靠位置编码「背答案」。测试中通道乱序性能零波动,仅用25%数据即可泛化至全网络,真正实现鲁棒与精准双赢。
来自主题: AI技术研报
7802 点击 2026-03-26 10:50
 搜索
搜索
ICLR'26新研究CPiRi打破时序预测僵局:用冻结底座提取时序特征,轻量模块专注学习通道间真实关系,不靠位置编码「背答案」。测试中通道乱序性能零波动,仅用25%数据即可泛化至全网络,真正实现鲁棒与精准双赢。

你以为AI答错就一定是幻觉?不,它也可能是在故意骗你。
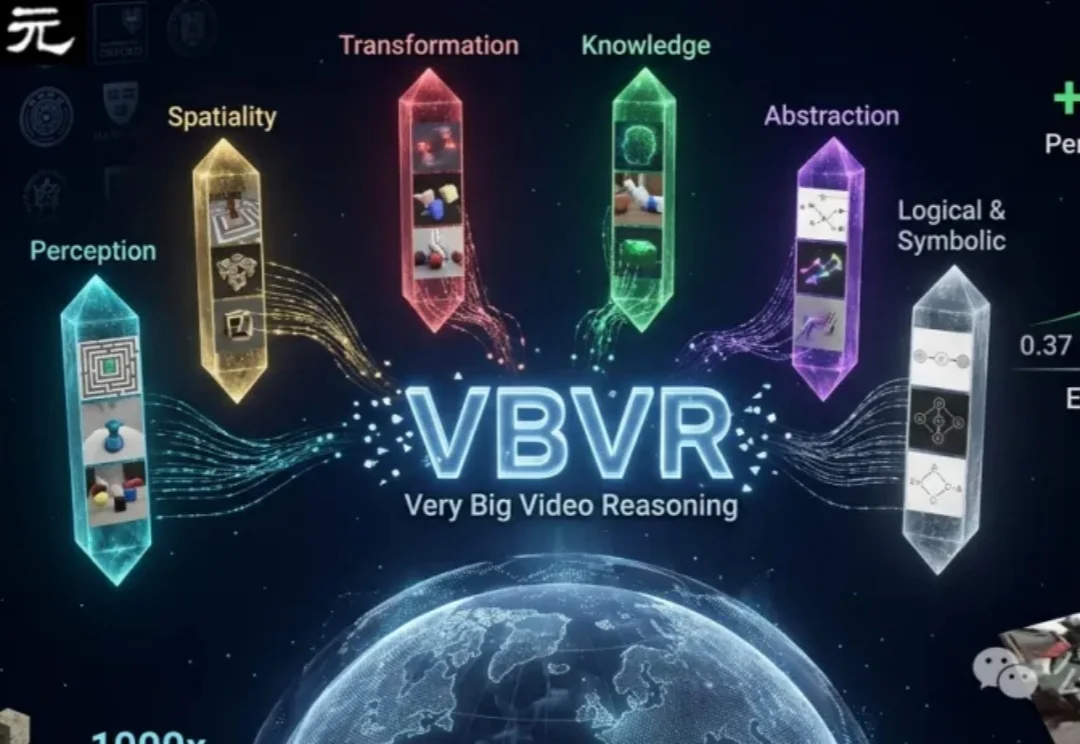
AI视频生成已能「画得像」,但不会「想得对」。VBVR推出百万级视频推理数据集,首次系统评测模型对空间、物理、逻辑和抽象的推理能力,发现顶尖模型通过率仅68%,暴露其缺乏真实认知,推动视频AI从「视觉模仿」迈向「智能推理」。
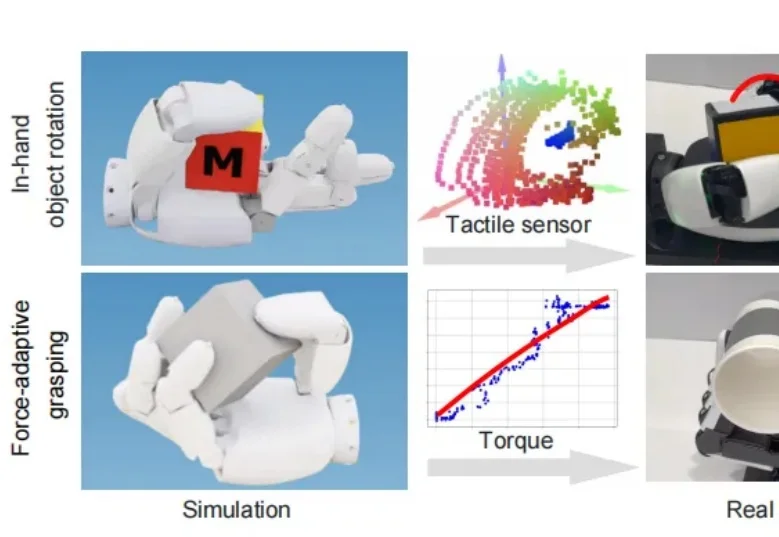
实现具备人类水平的灵巧操作能力,是机器人学领域长期以来的核心挑战之一。尽管多指灵巧手在硬件上具备了类似人类的潜力,但由于接触丰富的物理特性和非理想的驱动机制,训练能够直接部署在真实硬件上的控制策略仍然非常困难。
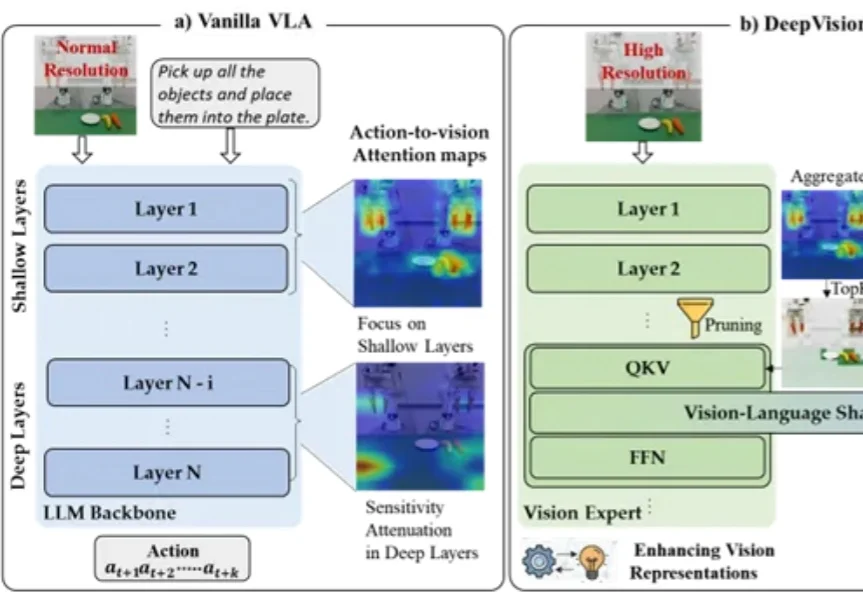
“把水果放进盘子里”——机器人看懂了指令,开始执行,却在最后关头抓偏了。

在大模型后训练阶段,监督微调(SFT)和强化学习(RL)是两根不可或缺的支柱。SFT 利用高质量的离线(Off-policy)数据快速注入知识,但受限于静态数据分布,泛化能力往往容易触及天花板并带来灾难性遗忘;RL 则允许模型在探索中不断自我迭代,产生与当前策略同分布(On-policy)的数据,上限极高,但往往伴随着训练极度不稳定、计算资源消耗巨大的痛点。
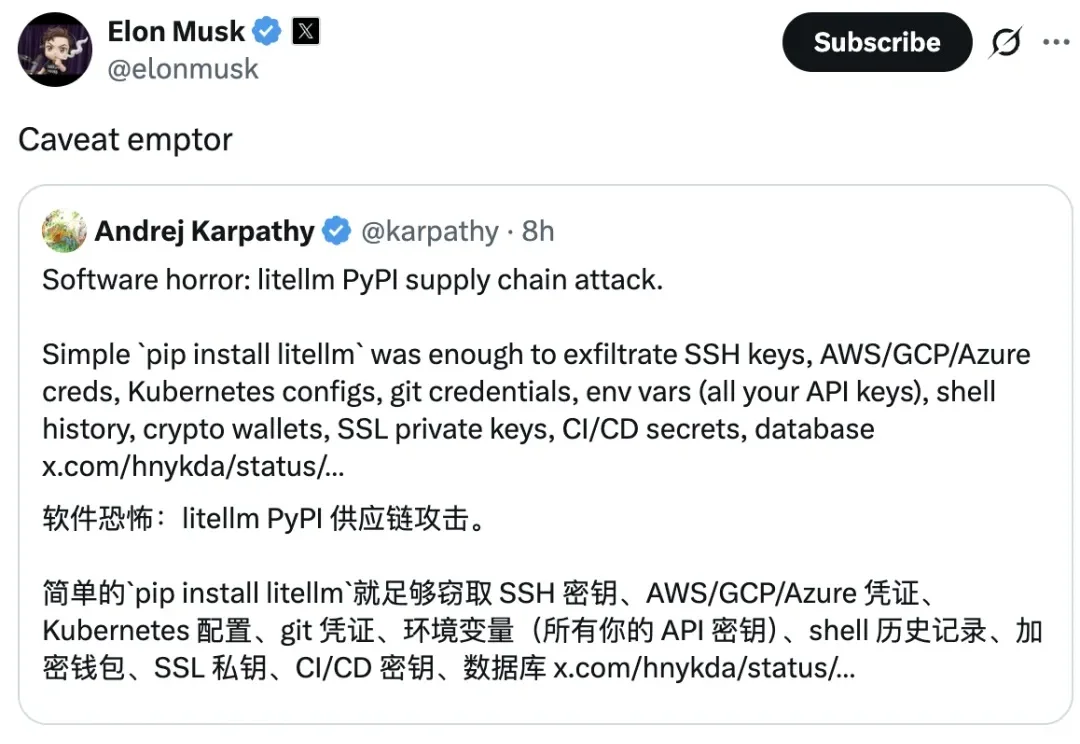
这是一件极其严肃的软件安全事件。
大模型开发者常面临一个两难选择:要速度,还是省显存?

到2025年末,AI编程已经全面从辅助工具Copilot,转向以AI为主、人类监督的Agent时代。
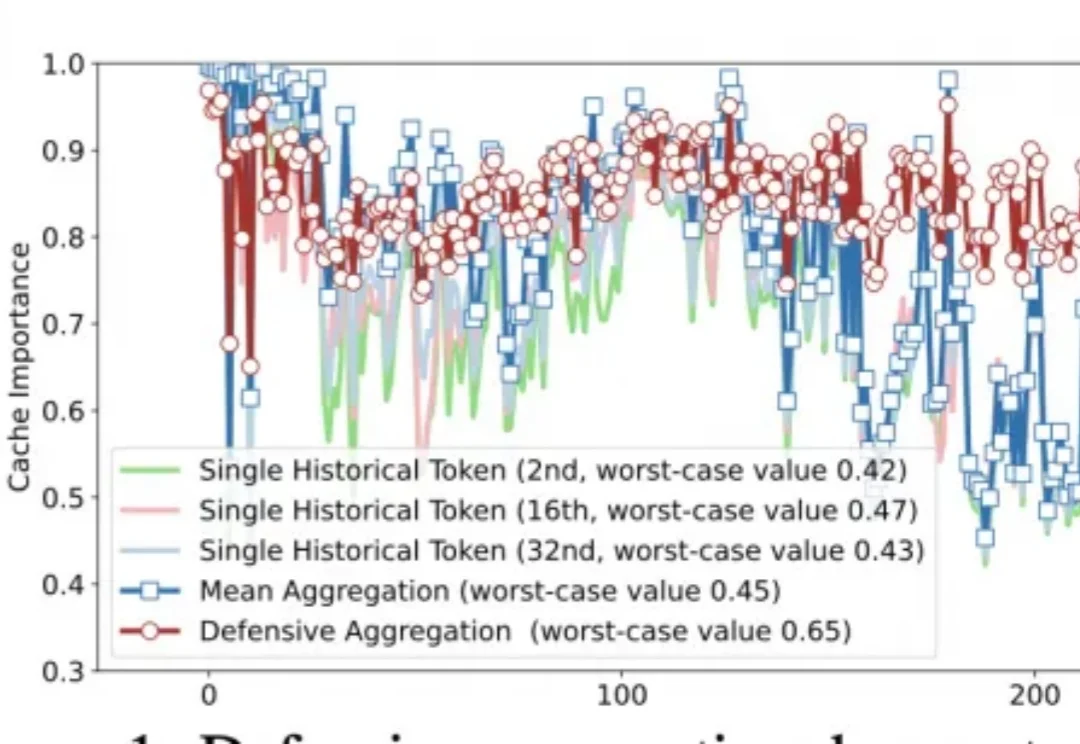
随着大模型长上下文能力快速增长,海量 KV Cache 存储需求急剧增加,各类 KV Cache 压缩方法如雨后春笋般涌现。然而,这些方案在真实场景中的工程落地却常常陷入困境。
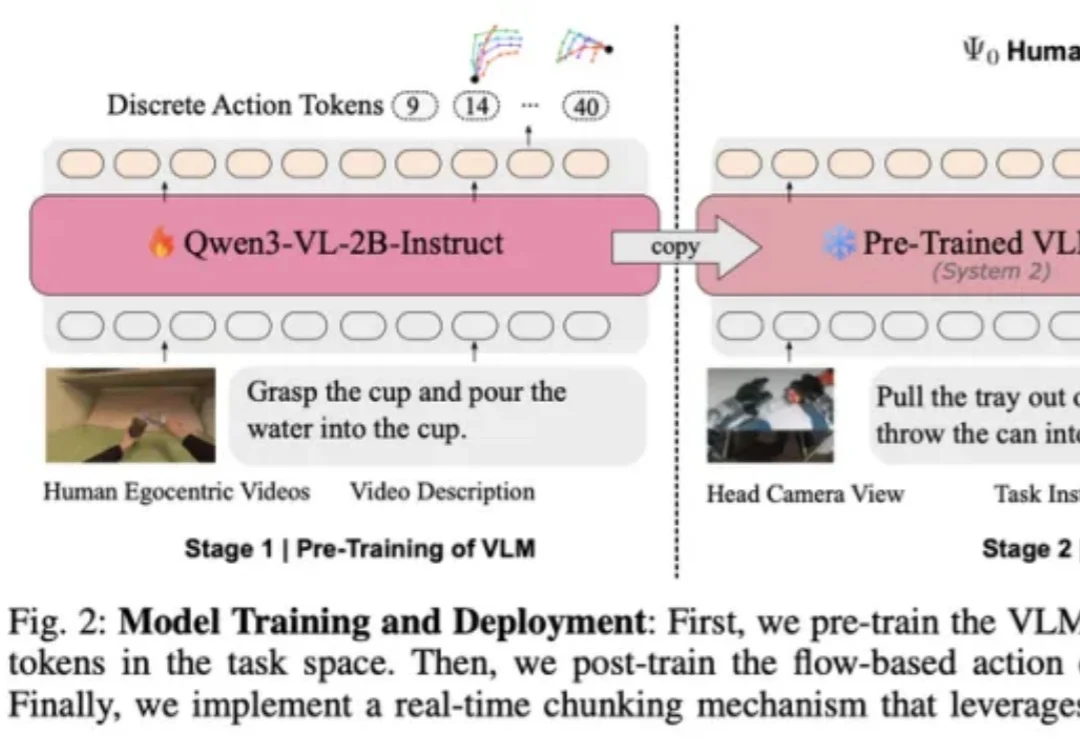
人形机器人在春晚舞台上大放异彩!然而,人们在看惯了机器人跳舞、后空翻,乃至武术表演之后,不禁开始思考:机器人何时才能真正走进大众生活,解决日常生活中的琐碎任务,从而解放人类的双手?
养了这么久的虾,你应该能发现,skills有多重要了。

近期,围绕「世界模型」这一方向,有两项工作受到较多关注。

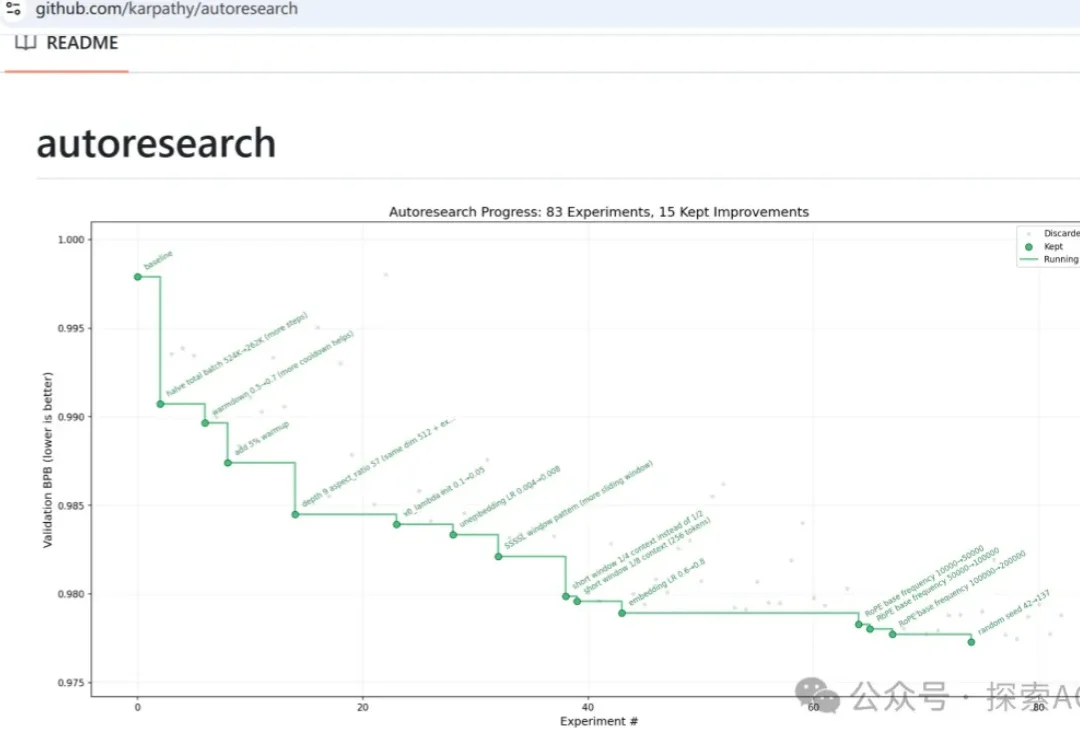
LeCun世界模型最新进展,开源了一套极简训练方案,单GPU就能跑。
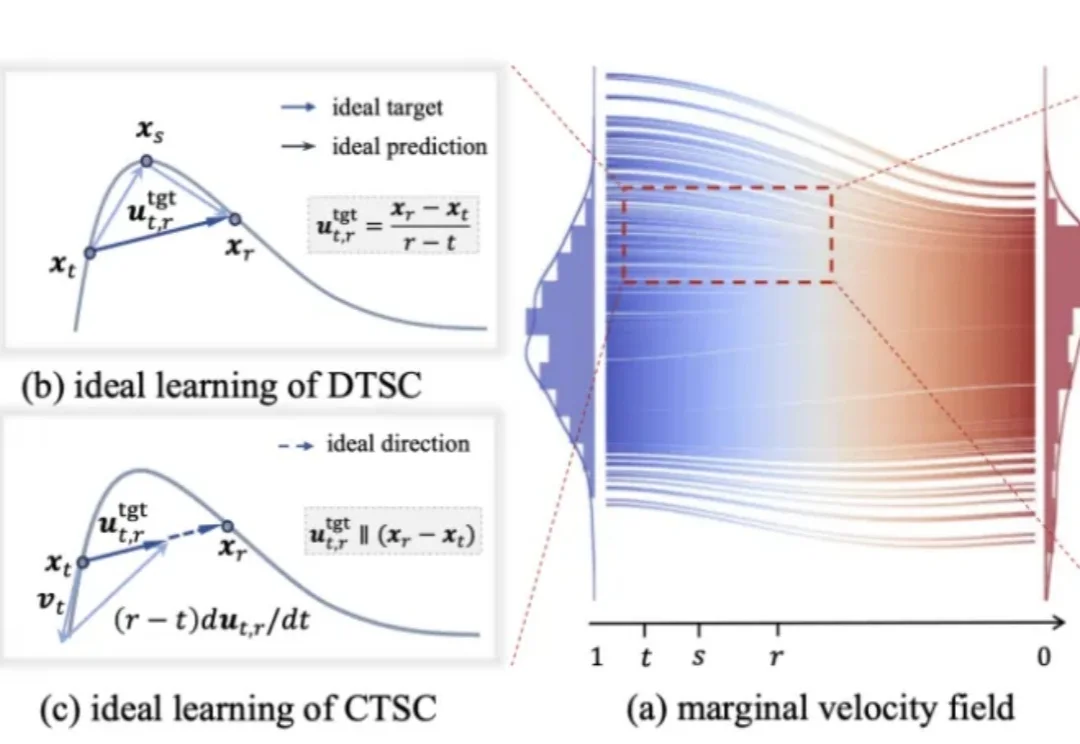
近期,基于捷径化概率流路径(shortcut probability flow trajectory)并从头训练的一步扩散生成模型,展现出强大的实证有效性。然而,这类方法的提出通常建立在较为复杂的理论推导之上,并且往往与具体实现细节高度耦合。这带来一个直接的问题:究竟哪些设计是方法成立的本质要素,哪些又只是可以灵活替换的实现组件。
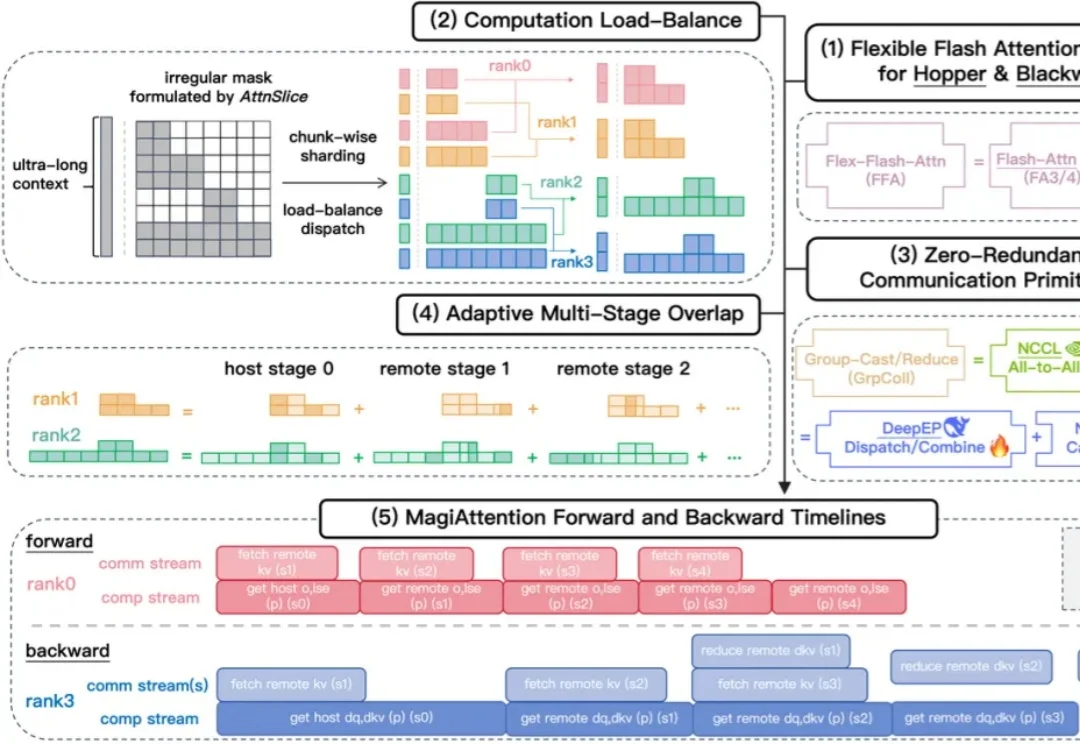
2025 年 4 月,Sand.ai 开源了 MagiAttention v1.0.0,定义了下一代分布式 Attention 的全新设计和系统框架。历经一年的深耕,今天 Sand.ai 正式发布:MagiAttention v1.1.0,以更成熟的原生算子组件,重新定义 Hopper 与 Blackwell 两代架构分布式 Attention 的性能上限。

我们在很多地方都看到了一个词,叫「压缩即智能」

UIUC研究团队打造ResearchArcade,将ArXiv论文、OpenReview评审、图表代码等碎片数据连接成动态知识图谱。模型可直接学习引用关系、修改轨迹与审稿互动,让AI更好辅助科研写作、修订与预测,为下一代科研智能体奠定统一数据基础。
在自动驾驶、具身智能、AR/VR应用中做3D重建,大家都想解决一个终极问题: 模型能不能像人一样,一边往前看,一边持续构建三维世界?

近年来,随着 Sora、Seedance 等文本到视频(T2V)扩散模型的飞速发展,AI 视频生成在视觉保真度与动态表现上已取得突破性进展。特别是近期备受瞩目的 Seedance 2.0,展现出了极其强大的多镜头叙事与复杂分镜控制能力。

AI终于有了「永久记忆」!今天,超级记忆系统ASMR重磅登场,在业界公认最难AI记忆考试中,刷爆SOTA拿下99%成绩。全网直呼太疯狂。

安装完 OpenClaw 的那个晚上,我做的第一件事是这样的: 打开 ClawHub,看到几万个 Skill 整整齐齐排列在那里,于是我一个接一个地给我的小龙虾装...

您用OpenClaw或CC时有没有这样的感受?Skill越装越多,Agent解决问题的能力却没有越变越强。
AI最强幻觉,原来不是不会,而是太会「装会」。 「你是专家」这句咒语,可能骗了整个AI圈一年。
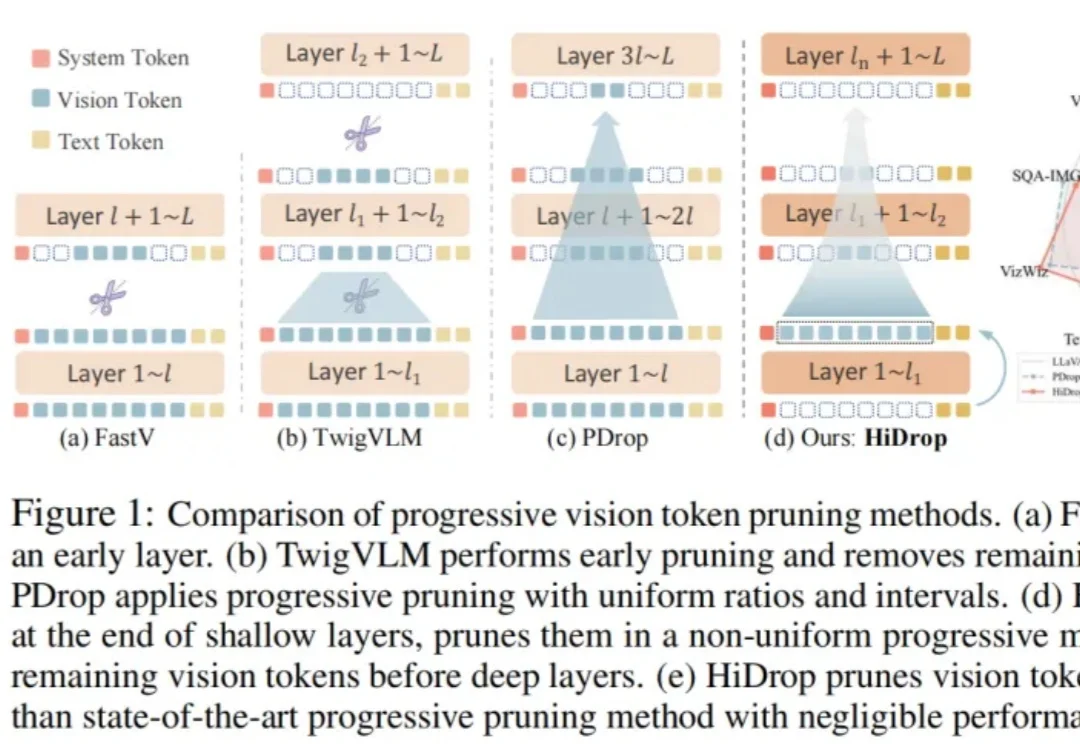
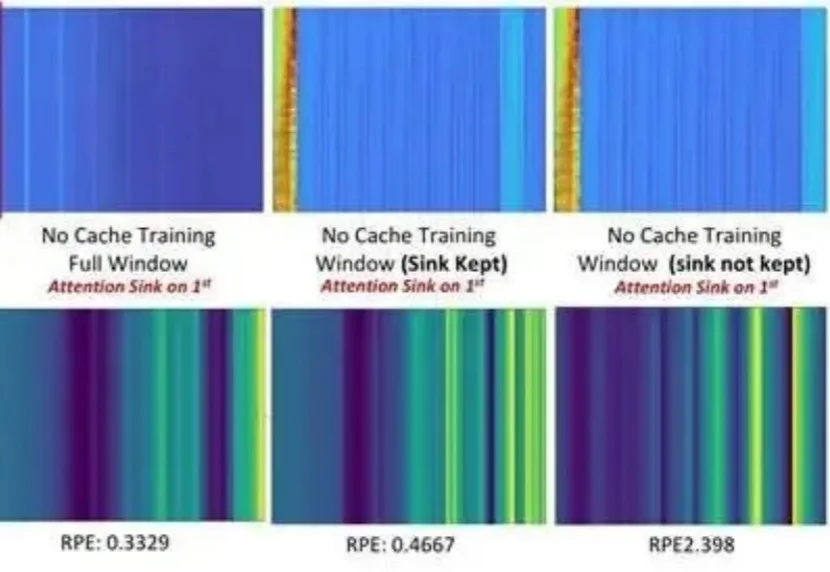
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。
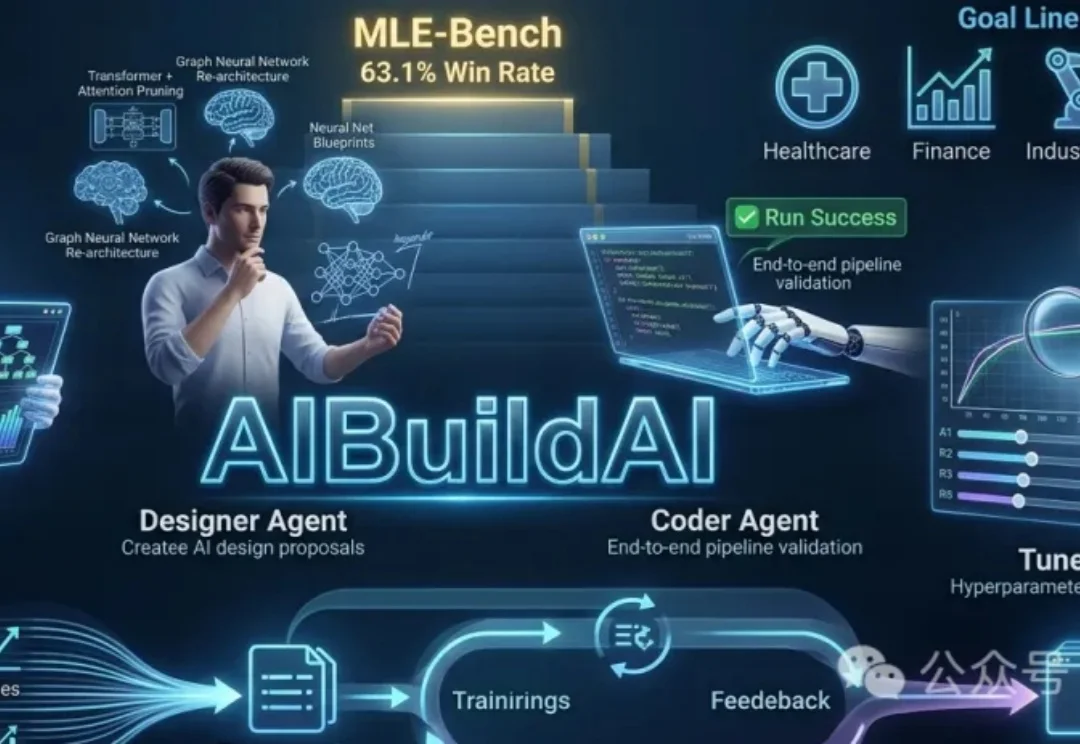
UCSD团队推出AIBuildAI智能体,无需编程,仅用自然语言描述任务,即可自动设计、编码、训练、调参并优化AI模型,分工协作,端到端完成AI开发。在OpenAI MLE-Bench测试中,AIBuildAI以63.1%的获奖率位居第一,性能媲美人类专家,推动AI开发迈向全自动化新时代。
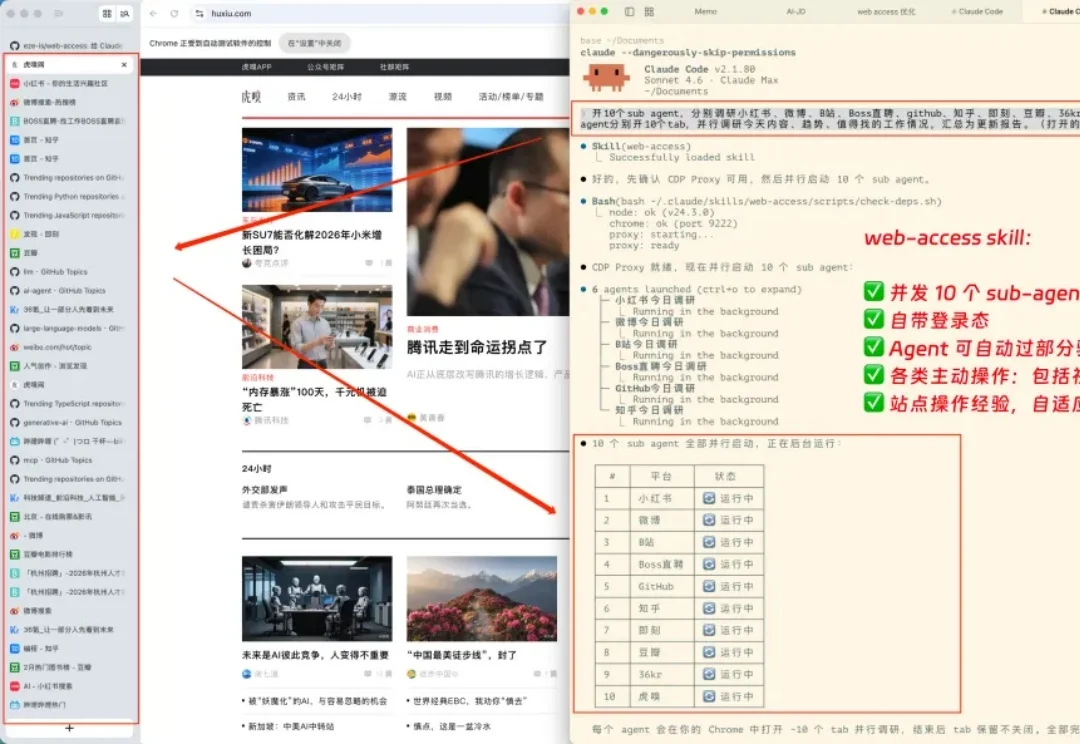
这个 Skill,能让你的 Agent 联网能力提升到最离谱的一集。
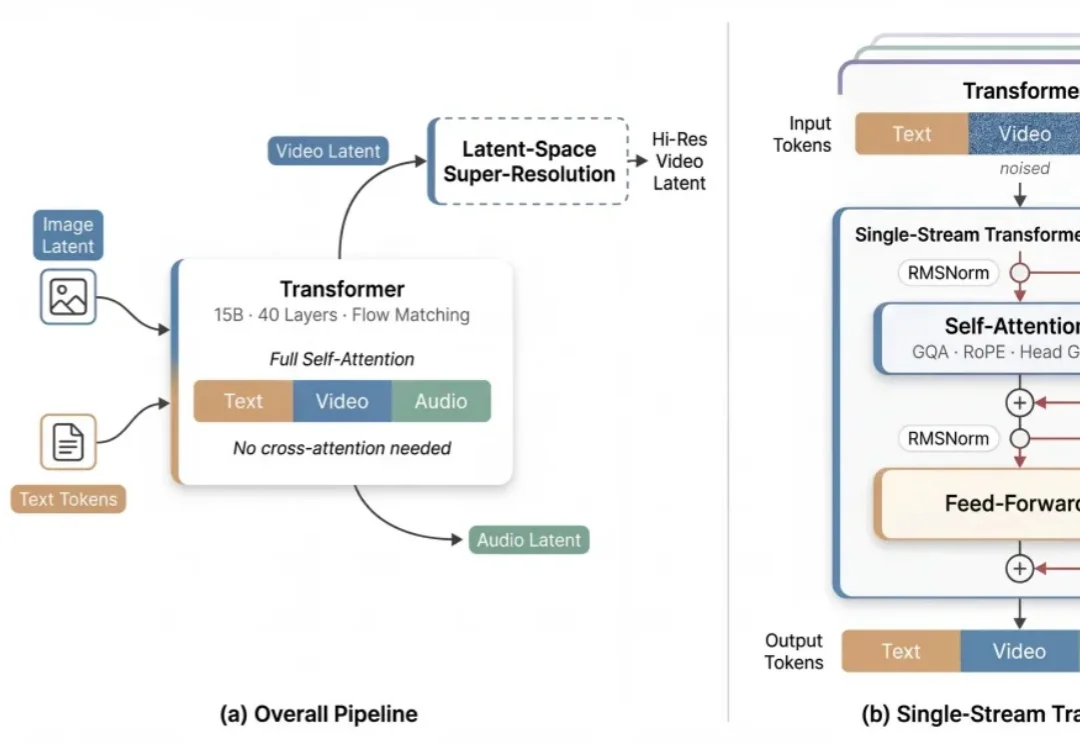
开源多模态生成领域,迎来架构级的底层突破。
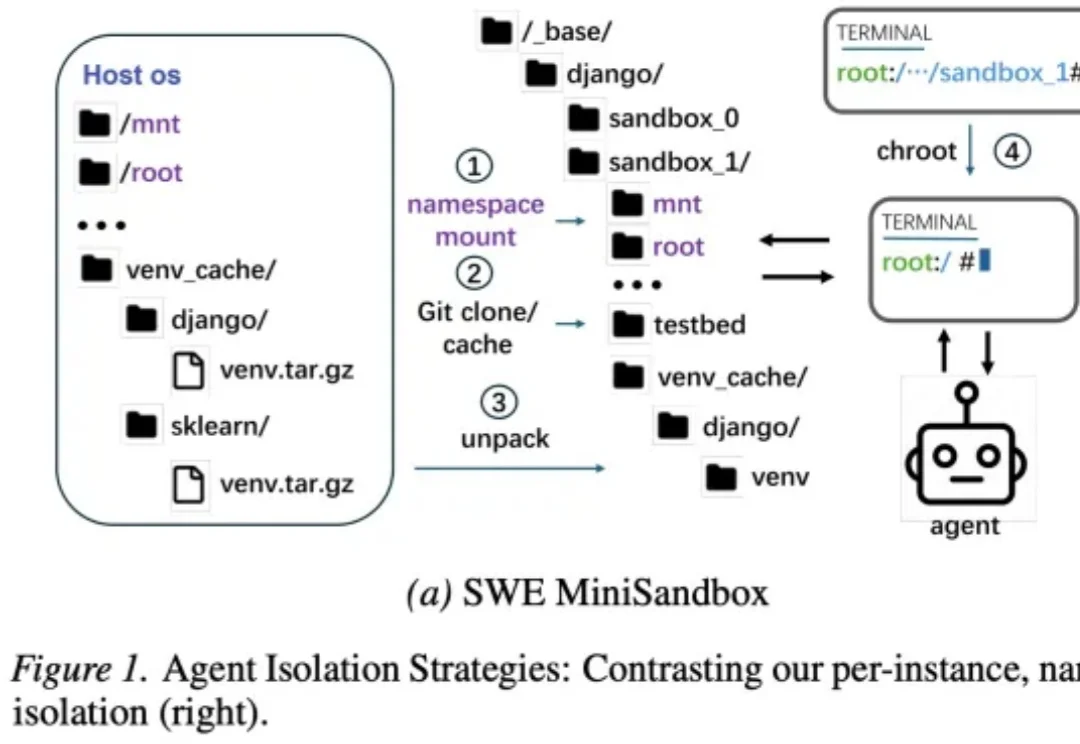
AI 编程这么火,想训练个 SWE Agent 却没有资源怎么办?

苦于AI单字拼凑没行气,或是排版秒变“鬼画符”?