
技多不压身,那龙虾的 Skill 是越多越好吗?
技多不压身,那龙虾的 Skill 是越多越好吗?安装完 OpenClaw 的那个晚上,我做的第一件事是这样的: 打开 ClawHub,看到几万个 Skill 整整齐齐排列在那里,于是我一个接一个地给我的小龙虾装...
来自主题: AI技术研报
10871 点击 2026-03-24 10:44
 搜索
搜索
安装完 OpenClaw 的那个晚上,我做的第一件事是这样的: 打开 ClawHub,看到几万个 Skill 整整齐齐排列在那里,于是我一个接一个地给我的小龙虾装...

您用OpenClaw或CC时有没有这样的感受?Skill越装越多,Agent解决问题的能力却没有越变越强。
AI最强幻觉,原来不是不会,而是太会「装会」。 「你是专家」这句咒语,可能骗了整个AI圈一年。
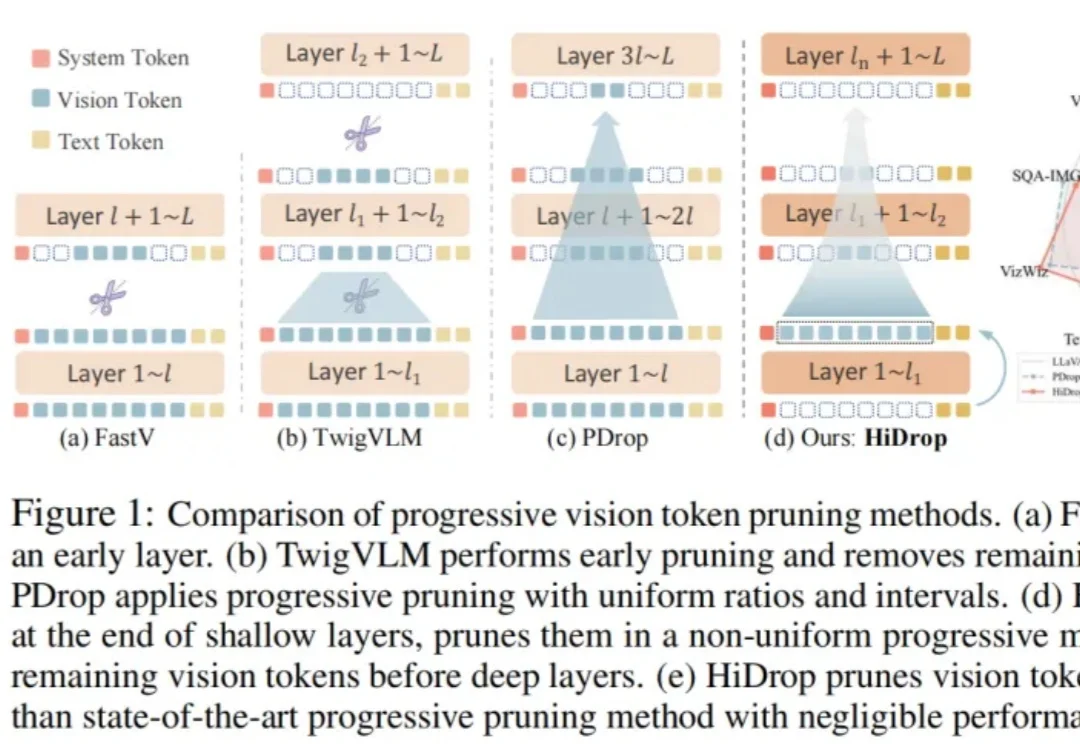
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。
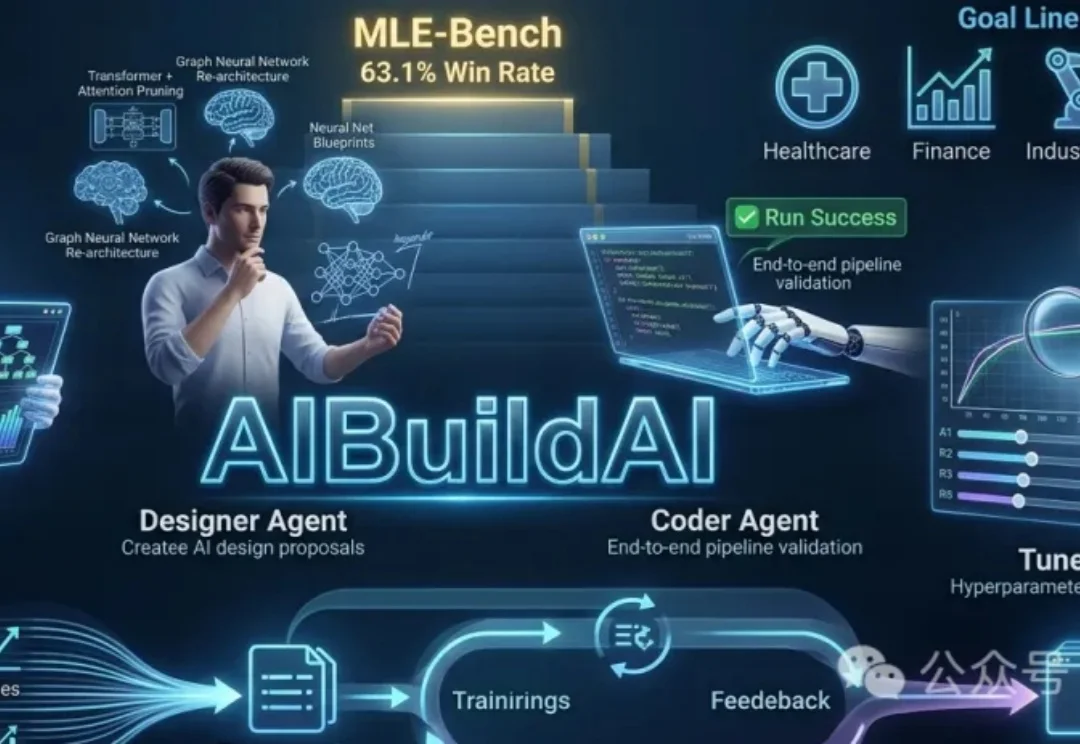
UCSD团队推出AIBuildAI智能体,无需编程,仅用自然语言描述任务,即可自动设计、编码、训练、调参并优化AI模型,分工协作,端到端完成AI开发。在OpenAI MLE-Bench测试中,AIBuildAI以63.1%的获奖率位居第一,性能媲美人类专家,推动AI开发迈向全自动化新时代。
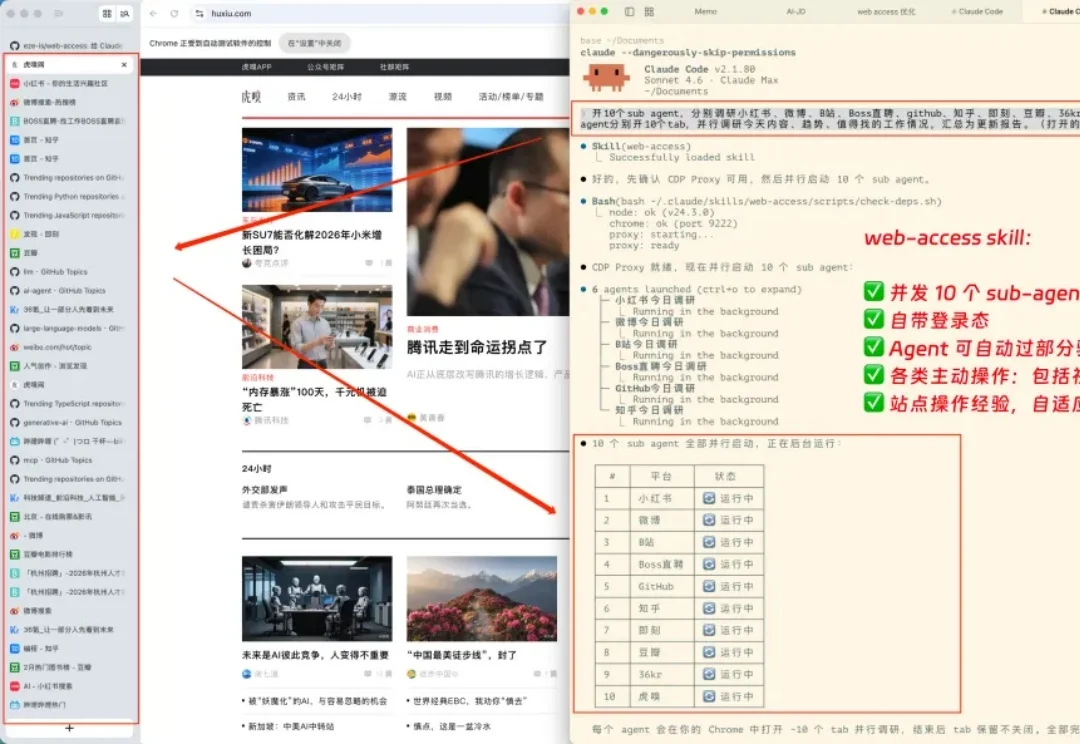
这个 Skill,能让你的 Agent 联网能力提升到最离谱的一集。
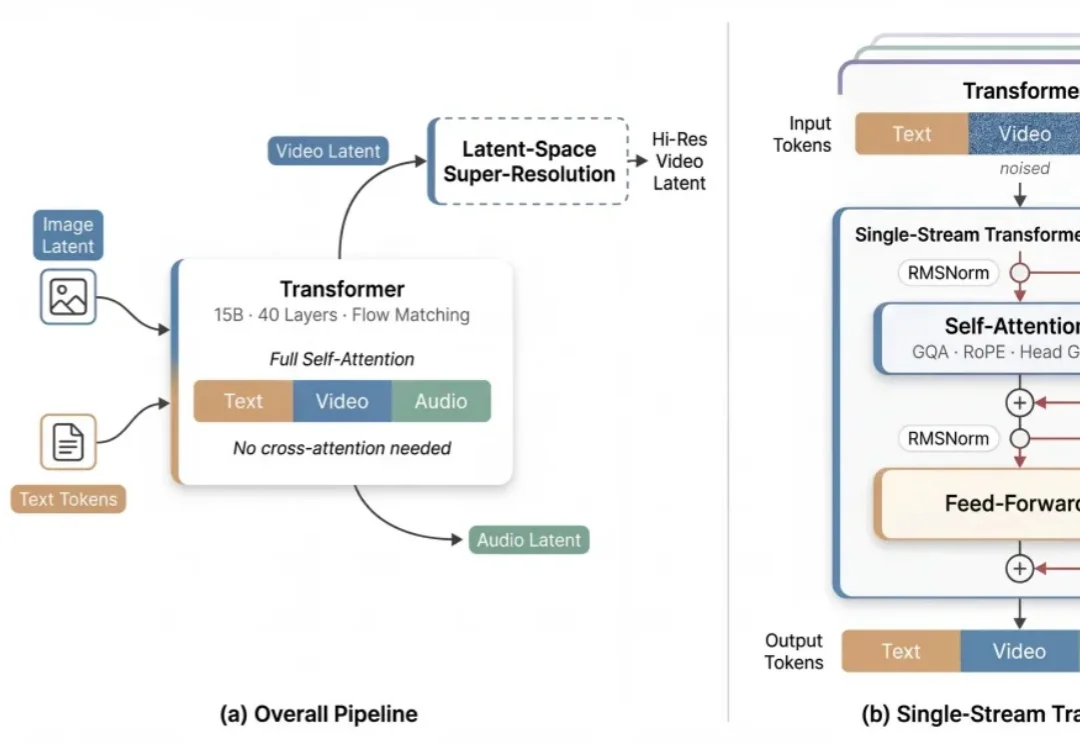
开源多模态生成领域,迎来架构级的底层突破。
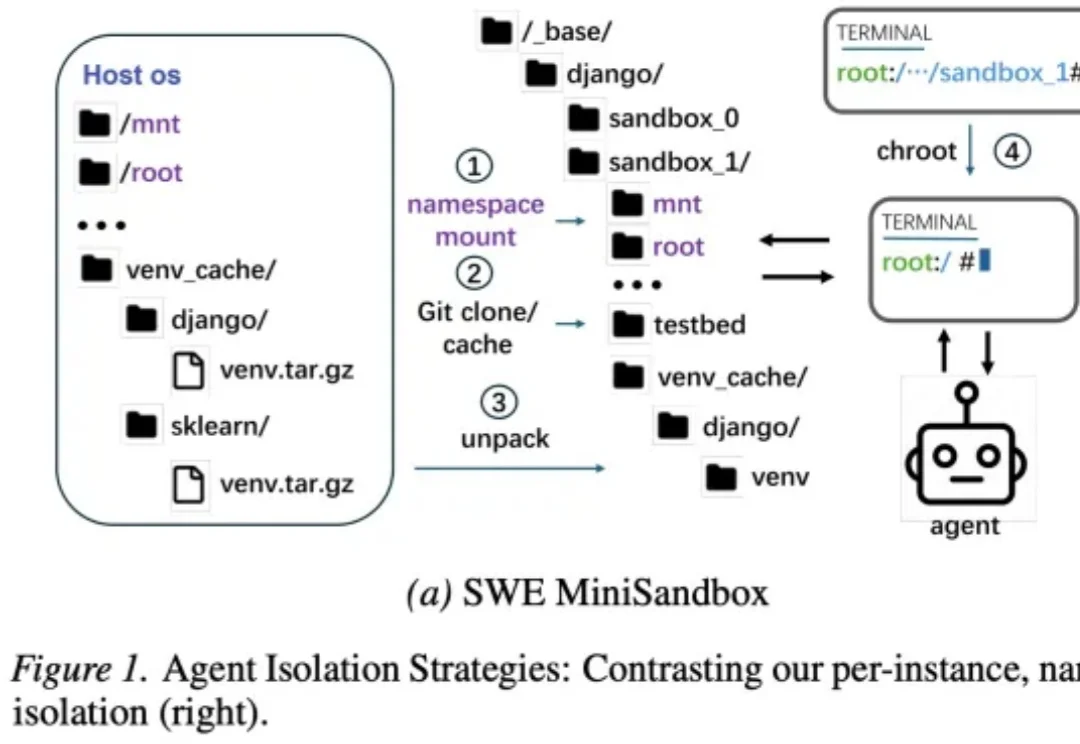
AI 编程这么火,想训练个 SWE Agent 却没有资源怎么办?

苦于AI单字拼凑没行气,或是排版秒变“鬼画符”?
AI 驱动的自动化科研正从概念走向真实系统。近期受到广泛关注的 FARS,以及 Karpathy 开源的 autoresearch,都在不同程度上展示了 AI Scientist 自动进行 AI 领域研究的可行性。

在 AIGC 领域,基于参考图像的图像修复(Reference-based Inpainting)一直是一项备受关注的核心任务,它旨在利用参考图像引导修复过程,生成视觉一致的内容。这一技术在广告营销和电商领域有着巨大的应用潜力,例如让 AI 自动生成 “真人手持或穿戴商品” 的展示图。

一张蓝锥嘴雀的图片,你能认出它是“鸟”,但能认出它是“鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀”吗?

这两年,扩散语言模型(Diffusion LLM)一直是个很有讨论度的方向。

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大

一边的人,每次跟 Agent 说话都像重新 onboarding:得再讲一遍背景、偏好和上下文。另一边的人,Agent 已经知道自己是谁、该怎么说话、用户讨厌什么,也记得上次积累下来的东西。这条分界线,叫 workspace。

目前,该论文已录用至 CVPR 2026,相关数据集和模型训练训练和推理代码将逐步开源:究其原因,一个好故事并非一堆漂亮镜头的简单拼接,而是一个有结构、有逻辑的叙事整体。
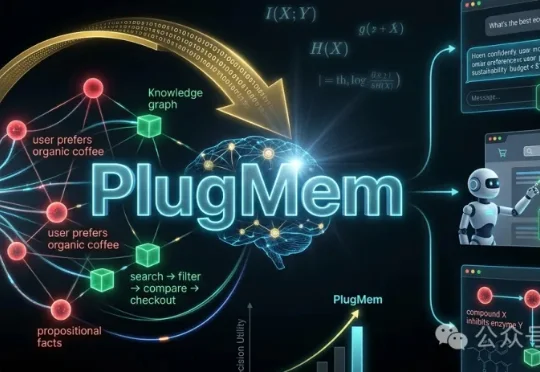
现在的AI agent往往把长交互历史直接存起来,但很难高效复用。最朴素的方法直接从「原始记忆」里检索,但常常把模型淹没在冗长、低价值的上下文里。PlugMem把经验转化为结构化、可复用的知识,并提出一个任务无关(task-agnostic)的统一记忆模块,在多种Agent基准上提升性能,同时消耗更少。

在此背景下,浙江大学研究团队提出了 EasySteer——一个基于 vLLM 构建的高性能、可扩展 LLM Steering 统一框架。该框架通过与 vLLM 推理引擎的深度集成,相比现有 Steering 框架实现了 10.8-22.3 倍的推理加速,同时提供更细粒度的干预控制,并为八大应用场景提供了预计算 Steering 向量与完整复现示例,方便研究者快速上手和对照复现。

OpenClaw-RL的核心价值在于:它能让您的OpenClaw🦞仅仅通过与你日常对话产生的自然反馈(如你的纠正、补充说明或环境报错),就能在后台实时自动更新权重,变得越来越符合您的个性化偏好,并在实际任务中不再犯同样的错误。
2026年开年以来,Harness工程一词热度渐高,OpenAI在2月发布的一篇详细的内部实验报告标题中使用了此词,ThoughtWorks 首席科学家 Martin Fowler 在 X上也表示Harness工程是AI赋能软件开发的关键部分。
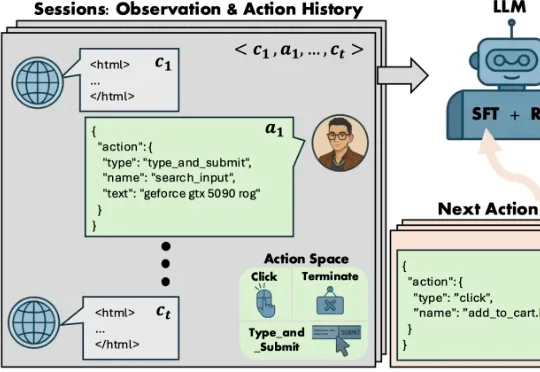
传统的 AI 购物助手更像是一个任务完成机器:接到指令,搜索,下单。他们或许能跑通流程,却完全无法理解用户为何在最后一刻因为一条关于 “夹耳朵” 的差评而放弃支付。简而言之,传统的电商 Agent 只是任务导向的(task-oriented),而不是模拟导向的(simulation-oriented)。为此,来自亚马逊(Amazon)的研究团队提出了名为 Shop-R1 的训练框架 。
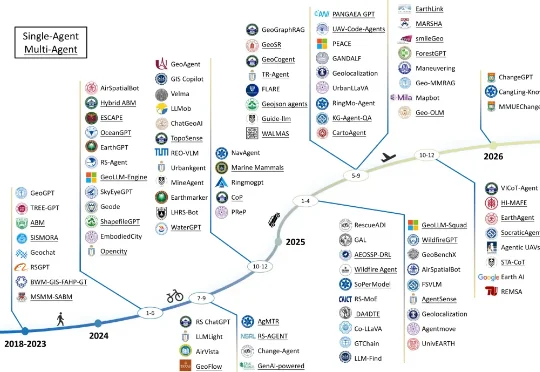
如今,一场由 AI 智能体驱动的变革正在发生。近日,来自香港科技大学、西北工业大学、清华大学等多家高校及研究机构的学者联合发布了遥感 AI 智能体领域系统综述。全文逾万字,首次为「遥感智能体」给出了严格定义,系统梳理了其架构、应用、数据集与未来方向。
养了这么久龙虾,是时候开始构建自己的 Skills 了。这时候,一篇来自 Anthropic 团队的 Skills 秘籍在外网广为流传,为想要构建 Skills 的开发者和智能体用户提供了绝佳的参考资料。
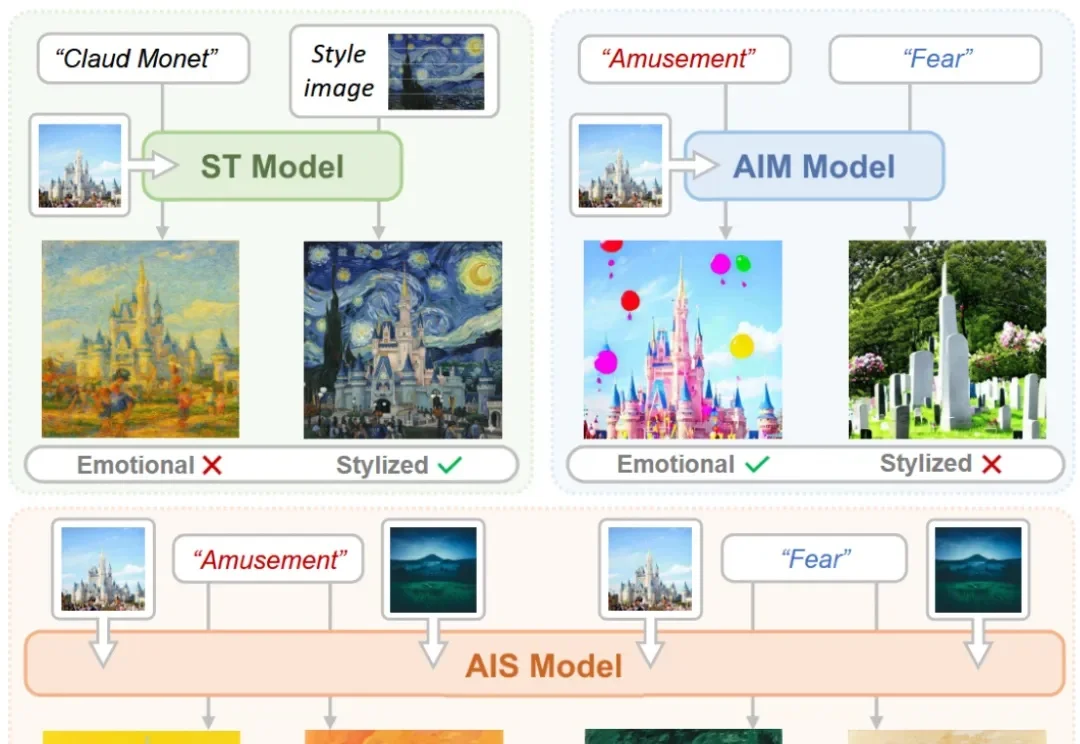
EmoStyle 由深圳大学可视计算研究中心黄惠教授课题组独立完成,第一作者为杨景媛助理教授,第二作者为研二硕士生柏梓桓。深圳大学可视计算研究中心(VCC)以计算机图形学、计算机视觉、人机交互、机器学习、具身智能、可视化和可视分析为学科基础,致力前沿探索与跨学科创新。
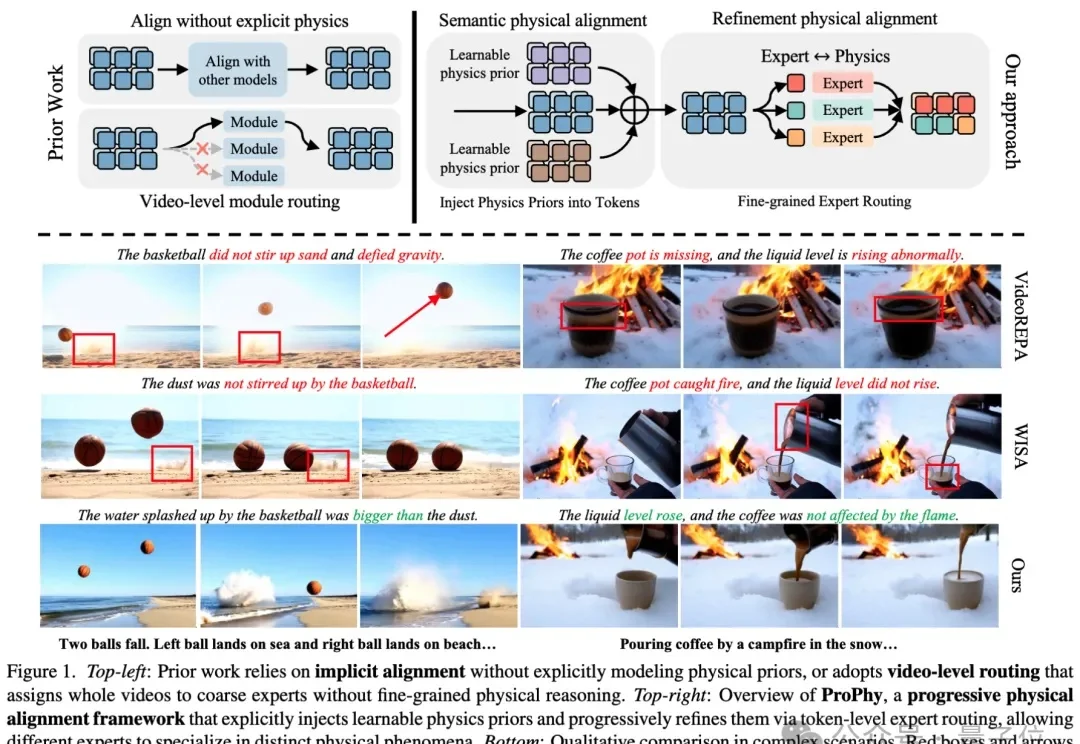
当人们谈到“世界模型”(World Models)时,很多人会首先想到近年来迅速发展的生成式视频模型。
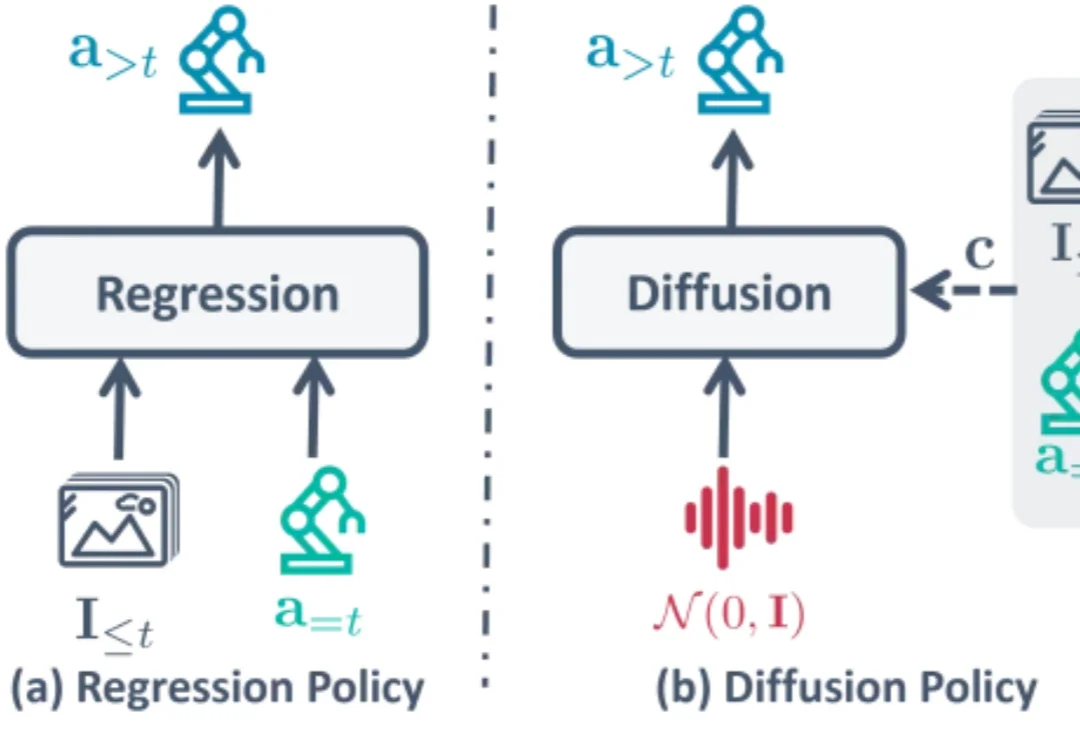
在机器人领域,扩散策略(Diffusion Policy)已经成为了标准模仿学习策略和 VLA 动作生成范式,但其「从随机噪声中迭代解噪」的机制带来了不容忽视的推理延迟。如果机器人不再从随机高斯噪声开始「盲猜」,是否可以基于「刚刚做了什么」来预测「下一步做什么」呢?

AI Agent世界的npm来了!

Transformer不保?今天,CMU普林斯顿原班人马杀回,新一代开源架构Mamba-3震撼降临。15亿参数战力爆表,性能比Transformer飙升4%。
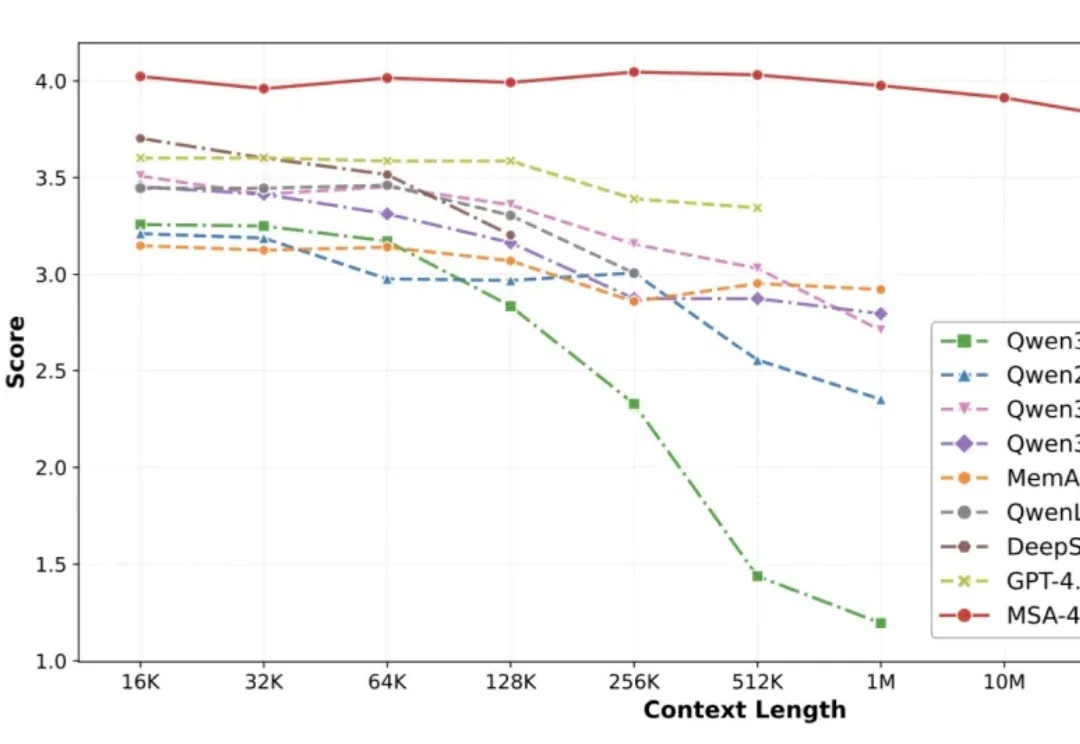
人的智能能力主要由推理能力和长期记忆能力构成。近年来,大模型的推理能力一直处于快速发展过程,但大模型的长期记忆能力一直受限于上下文长度,无法取得突破。在历史上,曾经有多种路线进行尝试,但都无法突破扩展性(Scalability)、精度(Precision)和效率(Efficiency)的不可能三角。

MLRA通过拆分KV缓存为四个并行分支,显著降低显存占用并实现4路张量并行。推理速度比MLA最高快2.8倍,支持百万级上下文,且模型质量更优。无需牺牲性能,即可高效扩展长文本处理能力。