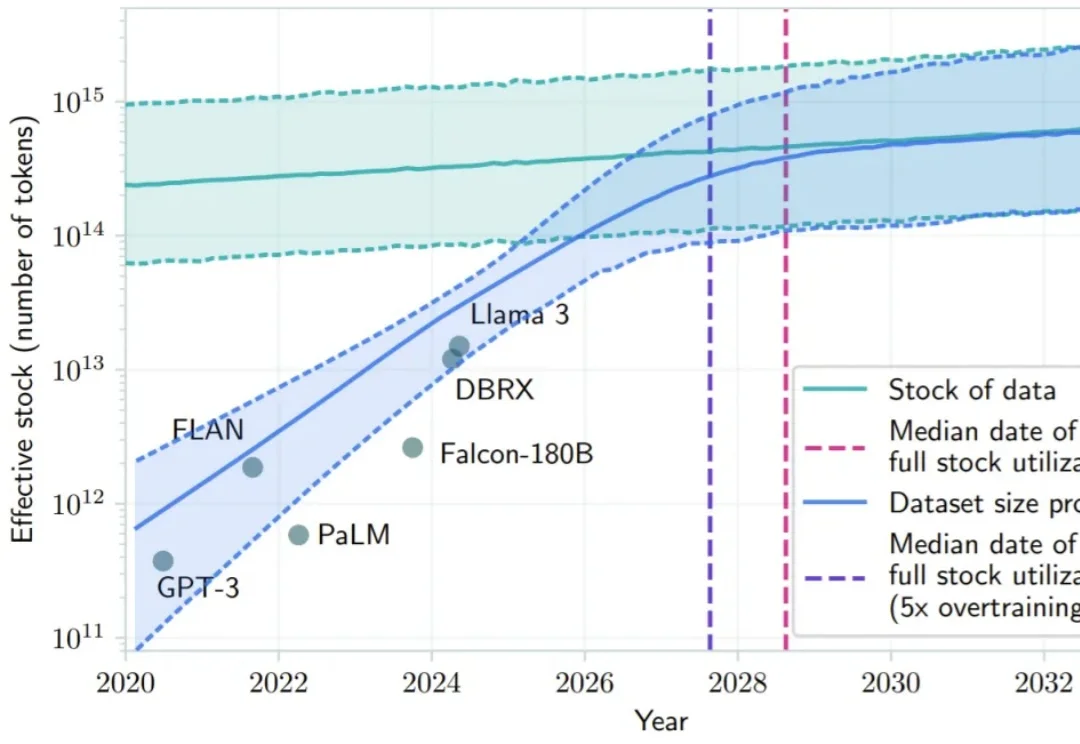
2026年,大模型训练的下半场属于「强化学习云」
2026年,大模型训练的下半场属于「强化学习云」2024 年底,硅谷和北京的茶水间里都在讨论同一个令人不安的话题:Scaling Law 似乎正在撞墙。
来自主题: AI技术研报
9809 点击 2026-01-12 15:13
 搜索
搜索
2024 年底,硅谷和北京的茶水间里都在讨论同一个令人不安的话题:Scaling Law 似乎正在撞墙。
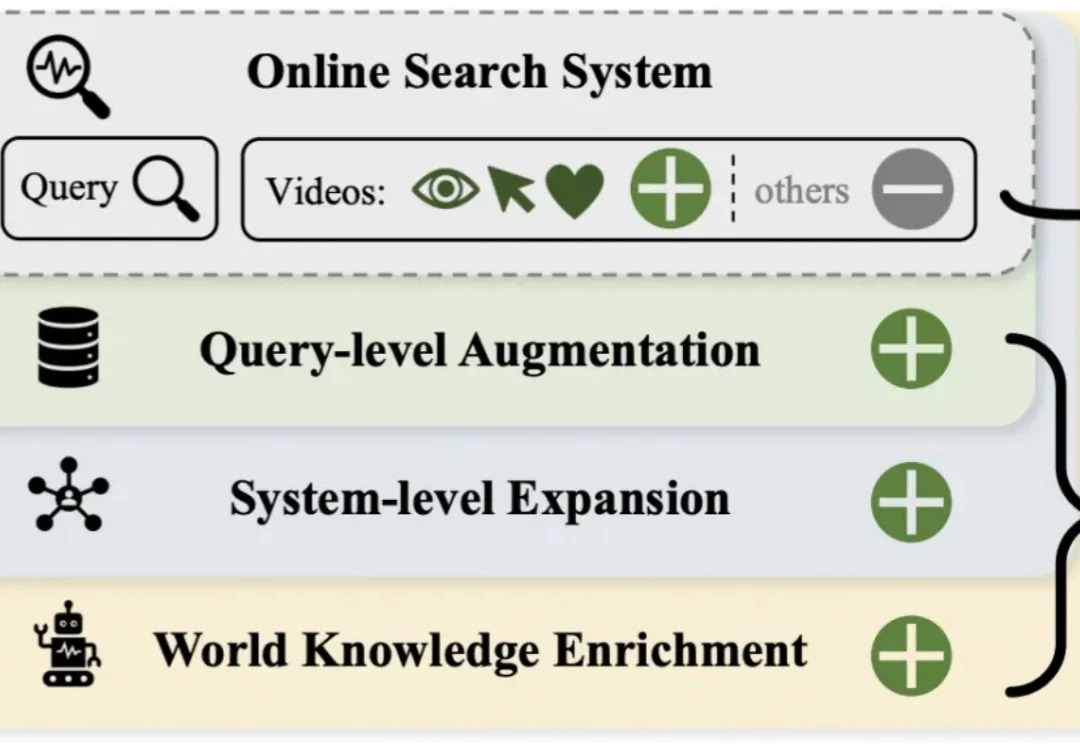
短视频搜索业务是向量检索在工业界最核心的应用场景之一。然而,当前业界普遍采用的「自强化」训练范式过度依赖历史点击数据,导致系统陷入信息茧房,难以召回潜在相关的新鲜内容。
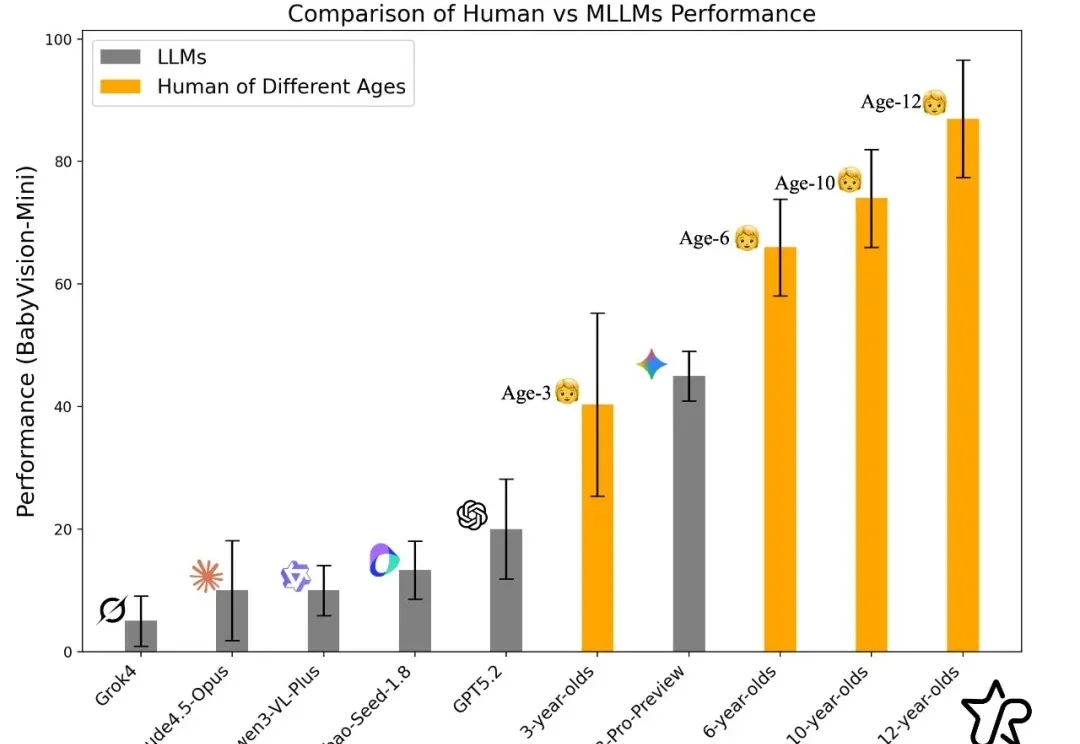
过去一年,大模型在语言与文本推理上突飞猛进:论文能写、难题能解、甚至在顶级学术 / 竞赛类题目上屡屡刷新上限。但一个更关键的问题是:当问题不再能 “用语言说清楚” 时,模型还能不能 “看懂”?
事情开始变得有趣起来了。
想象一下,一群 AI 程序在一台虚拟计算机里相互猎杀,目标只有一个:生存。
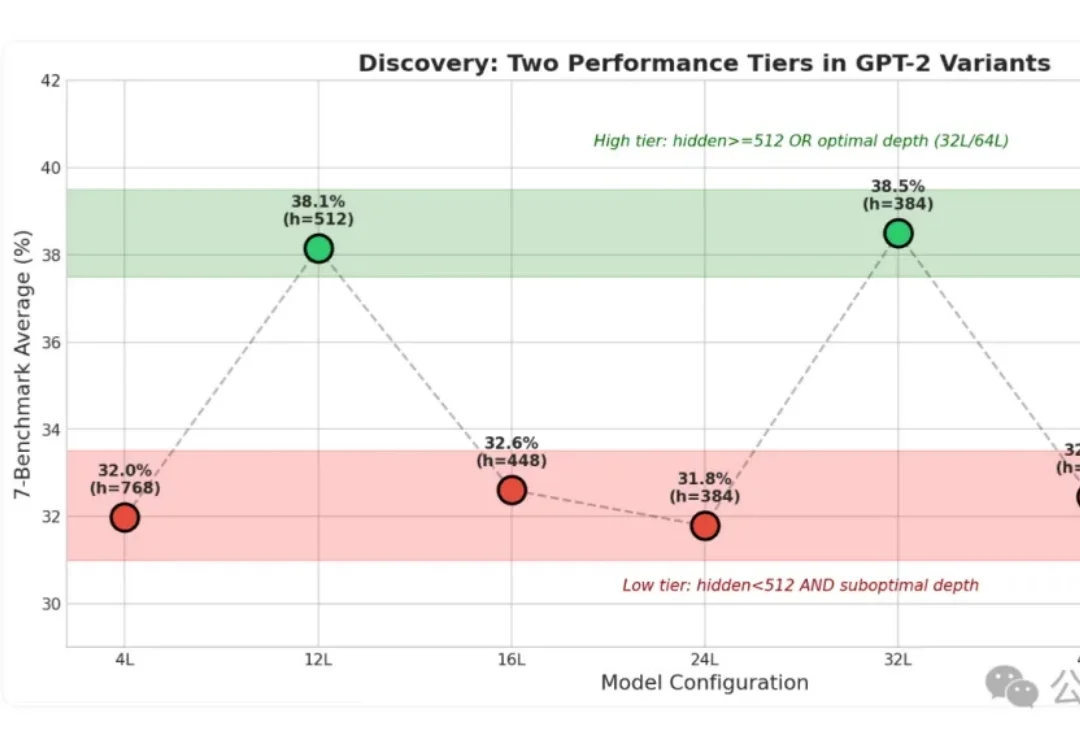
小模型身上的“秘密”这下算是被扒光了!

大模型能写代码、解奥数,却连幼儿园小班都考不过?简单的连线找垃圾桶、数积木,人类一眼即知,AI却因为无法用语言「描述」视觉信息而集体翻车。大模型到底「懂不懂」,这个评测基准给出答案。

Deepmind推出的SIMA 2,让智能体能在虚拟环境(商业游戏)中,边聊天边进行复杂的多模态推理。作为具身通用智能的原型,SIMA 2已从静态数据集迈向无限程序化生成的训练场。

GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。
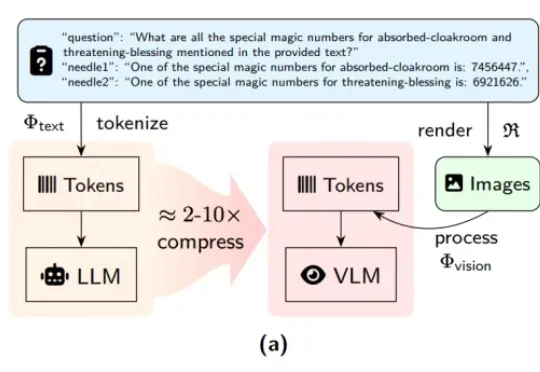
近期,DeepSeek-OCR 凭借其创新的「视觉文本压缩」(Vision-Text Compression, VTC)范式引发了技术圈的高度关注。为了解答这一疑问,来自中科院自动化所、中国科学院香港创新研究院等机构的研究团队推出了首个专门针对视觉 - 文本压缩范式的基准测试 ——VTCBench。
SmartSnap的核心思想是将GUI智能体从“被动的执行者”转变为“主动的自证者”。简单来说,智能体在完成任务的同时,还会主动收集、筛选并提交一份“证据快照集”。
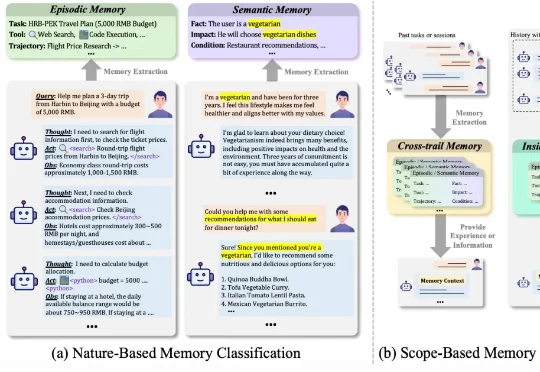
哈工大、鹏城实验室、新加坡国立、复旦、北大联合发布了一篇重磅综述《AI Meets Brain: A Unified Survey on Memory System from Cognitive Neuroscience to Autonomous Agents》,首次打破认知神经科学与人工智能之间的学科壁垒,系统性地将人脑记忆机制与 Agents 记忆统一审视,

几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。

论文将汇总人类从出生到死亡每个神经元的活动情况。利用更完善的“分子记录带”(molecular ticker tape)技术,神经元每发出一个电脉冲,都会在其蛋白链上加上一段荧光分子。通过对这些蛋白链进行测序,可以获得神经元整个生命周期内神经活动的完整历史记录。同时对每个神经元的mRNA进行测序,可以确定它属于10.4万个神经元类型中的哪一种。
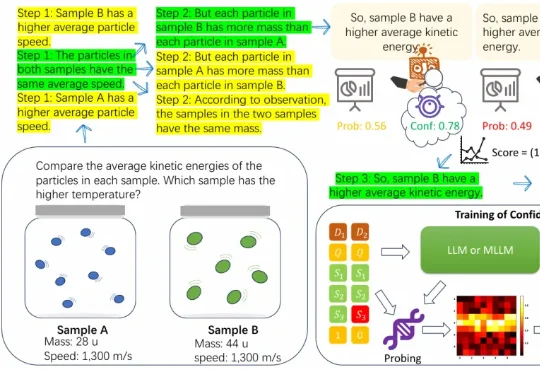
近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式
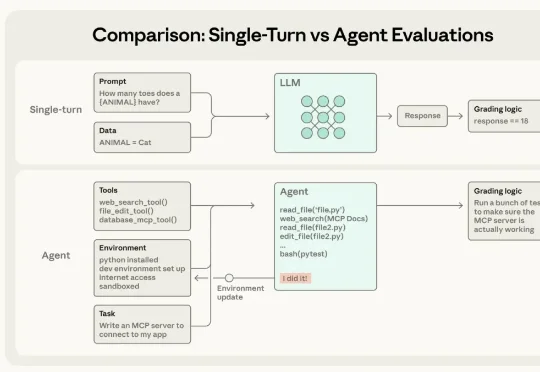
Agent 并不是一次性输出的系统。它们运行在多轮交互之中:调用工具、修改内部状态、根据中间结果不断调整策略。也正是这些让 Agent 变得有用的能力 ——自主性、智能性与灵活性 —— 同时也让它们变得更难以评估。
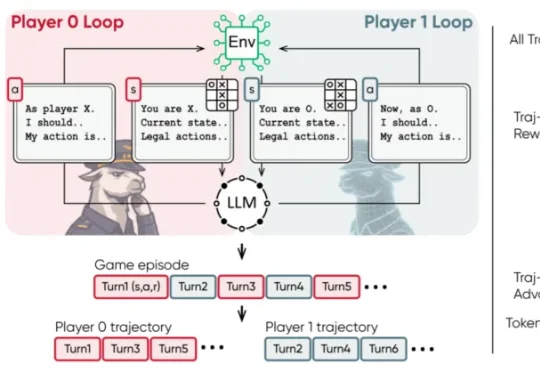
近日,清华大学等机构的研究团队提出了 MARSHAL 框架。该框架利用强化学习,让大模型在策略游戏中进行自博弈(Self-Play)。实验表明,这种多轮、多智能体训练不仅提升了模型在游戏中的博弈决策水
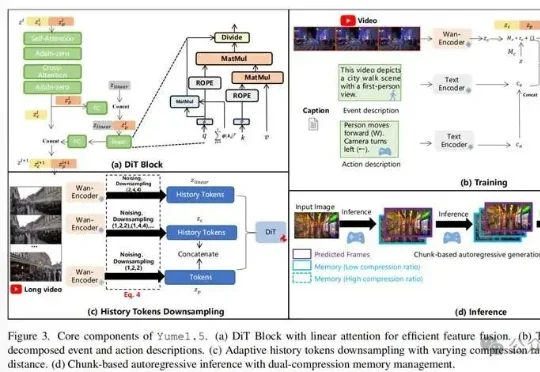
上海AI Lab联合多家机构开源的Yume1.5,针对这一核心难题提出了时空信道联合建模(TSCM),在长视频生成中实现了近似恒定计算成本的全局记忆访问。

CaveAgent的核心思想很简单:与其让LLM费力地去“读”数据的文本快照,不如给它一个如果不手动重启、变量就永远“活着”的 Jupyter Kernel。这项由香港科技大学(HKUST)领衔的研究,为我们展示了一种“Code as Action, State as Memory”的全新可能性。它解决了所有开发过复杂Agent的工程师最头疼的多轮对话中的“失忆”与“漂移”问题。
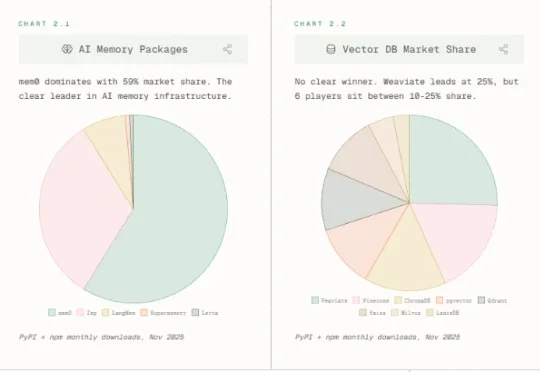
想知道硅谷的程序员怎么使用AI编程,被2000家公司使用的AI代码审查智能体Greptile基于每月用AI审核的的十亿行代码,发布了AI编程年度报告,揭示了使用AI编程后带来的生产率提升,但对此程序员们却无法感同身受。

借鉴人类联想记忆,嵌套学习让AI在运行中构建抽象结构,超越Transformer的局限。谷歌团队强调:优化器与架构互为上下文,协同进化才能实现真正持续学习。这篇论文或成经典,开启AI从被动训练到主动进化的大门。

针对端到端全模态大模型(OmniLLMs)在跨模态对齐和细粒度理解上的痛点,浙江大学、西湖大学、蚂蚁集团联合提出 OmniAgent。这是一种基于「音频引导」的主动感知 Agent,通过「思考 - 行动 - 观察 - 反思」闭环,实现了从被动响应到主动探询的范式转变。

最近一年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。

在上期内容发布后 有很多小伙伴都反馈很好用 NotebookLM改不了细节?提示词 V2.0 生成既有质感,又能随意修改文字的完美 PPT
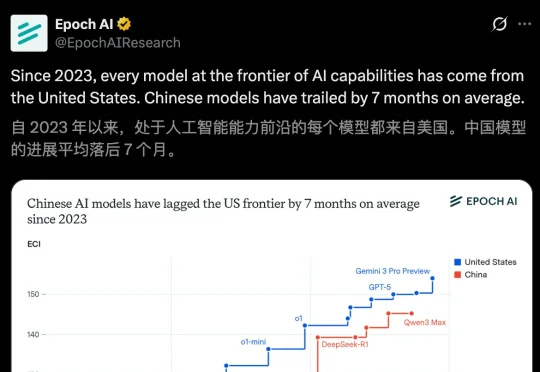
一张来自Epoch AI图表给出了一个冷静却尖锐的结论:中国AI平均落后7个月。一张图揭示真相:自2023年以来,前沿AI全部来自美国!最近,Epoch AI一份报告指出,中国AI模型的进展平均落后于美国7个月——最小差距为4个月,最大差距为14个月。
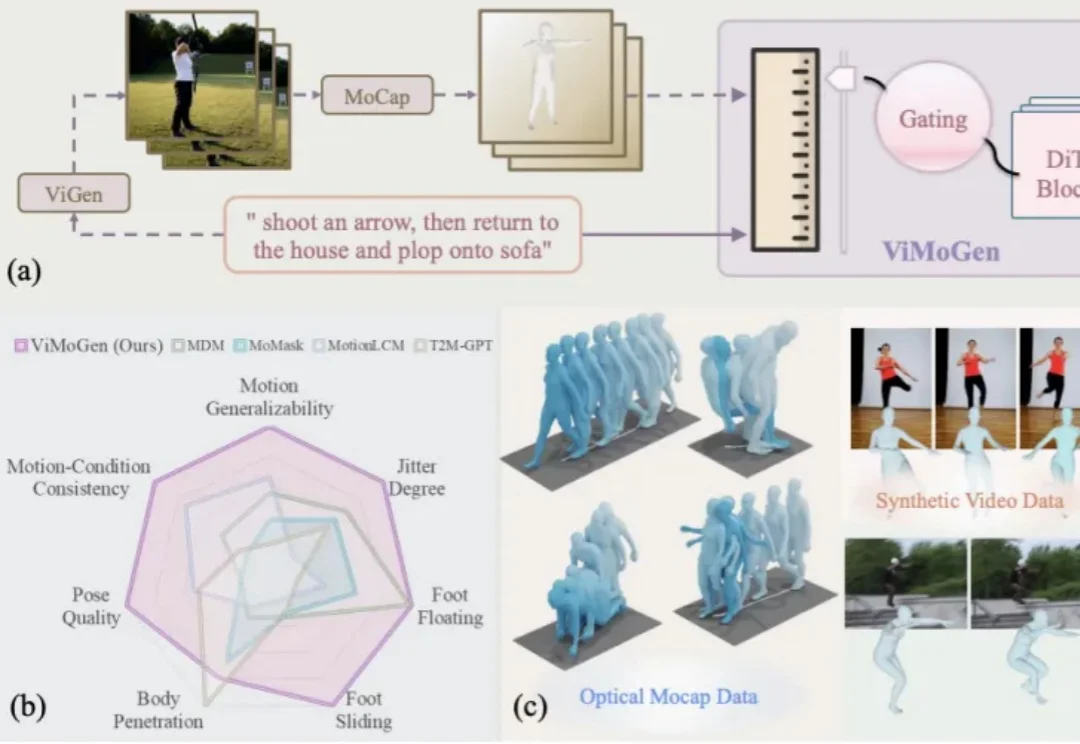
随着 AIGC(Artificial Intelligence Generated Content) 的爆发,我们已经习惯了像 Sora 或 Wan 这样的视频生成模型能够理解「一只宇航员在火星后空翻」这样天马行空的指令。然而,3D 人体动作生成(3D MoGen)领域却稍显滞后。
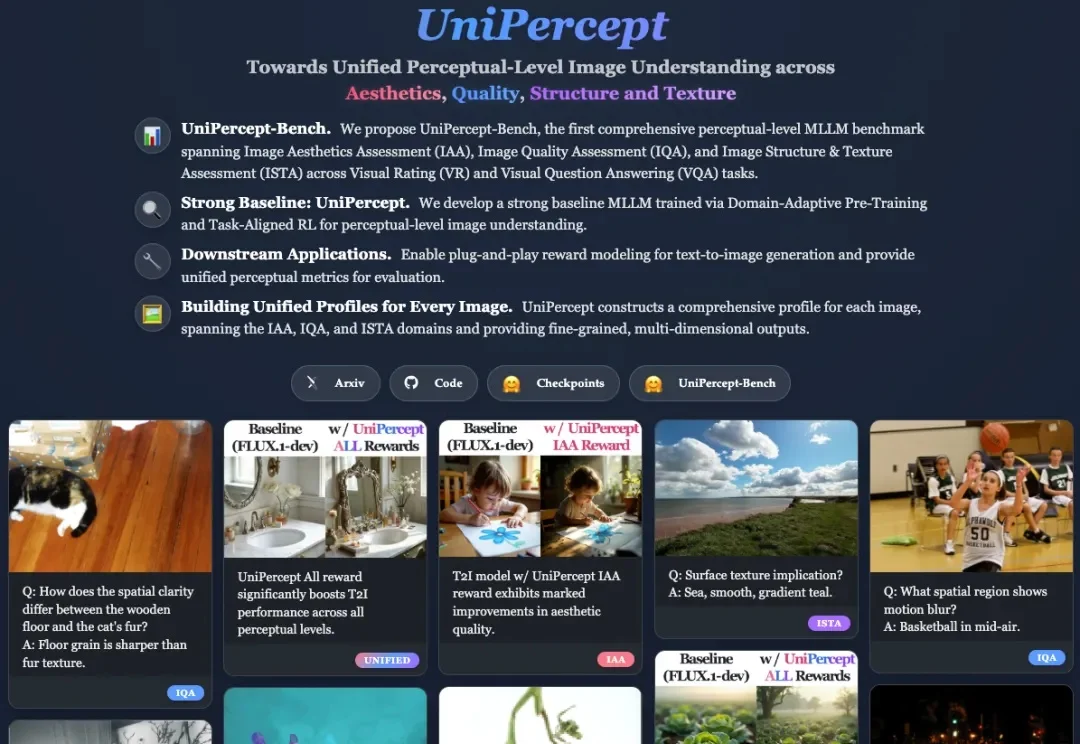
尽管多模态大语言模型(MLLMs)在识别「图中有什么」这一语义层面上取得了巨大进步,但在理解「图像看起来怎么样」这一感知层面上仍显乏力。
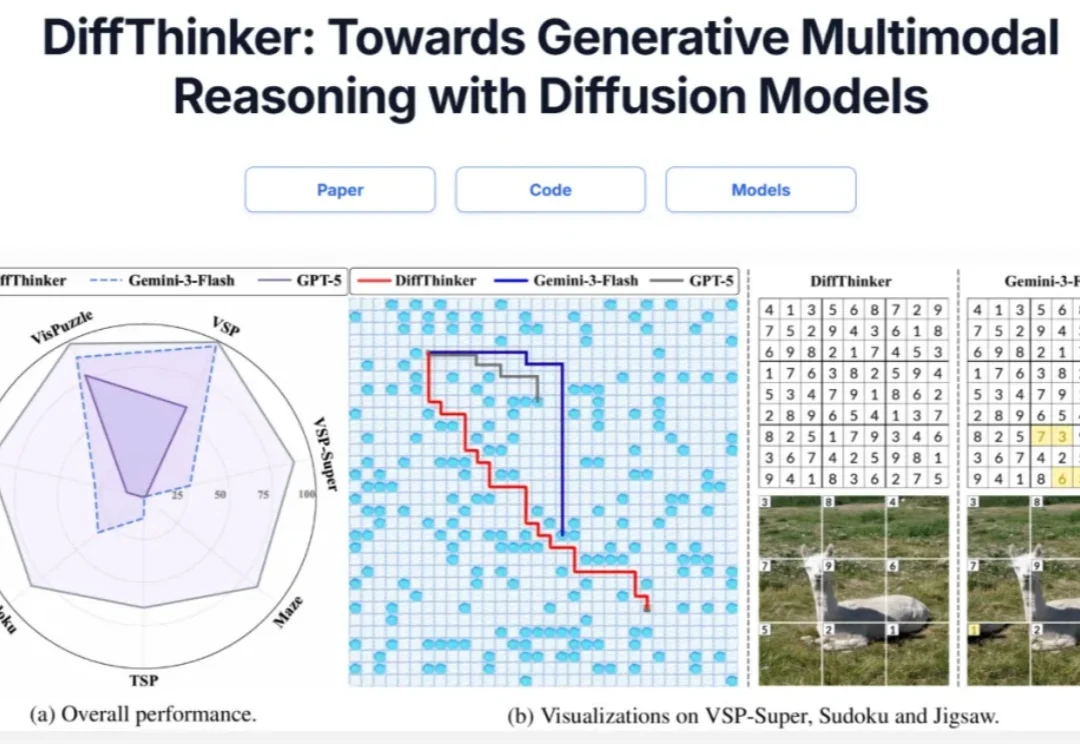
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。
两天前,DeepSeek悄无声息地把R1的论文更新了,从原来22页「膨胀」到86页。DeepSeek向世界证明:开源不仅能追平闭源,还能教闭源做事!
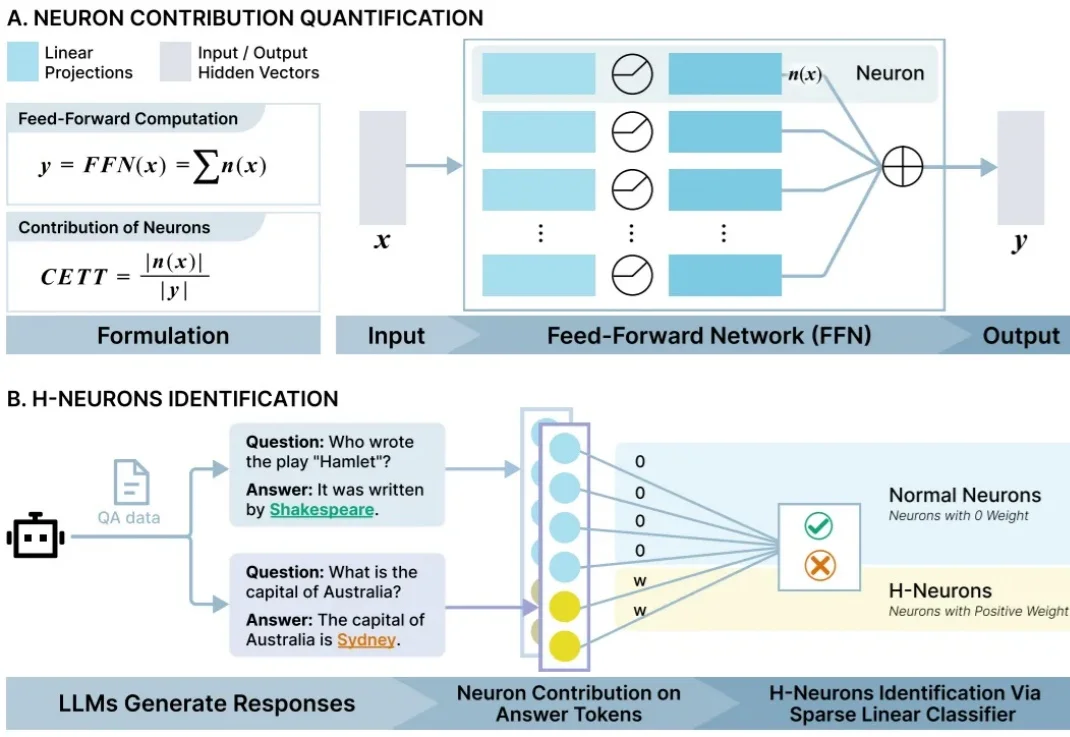
近日,清华大学团队从 AI 里找到了与幻觉产生高度关联的少数“脑细胞”,并给它们起了一个名字 H-神经元(幻觉神经元)。他们发现拨动这些小开关能显著调节 AI 的行为倾向——例如影响它是否会盲目听从错误指令、甚至是否会产生有害回答。