
OpenAI突然开源新模型!99.9%的权重是0,新稀疏性方法代替MoE
OpenAI突然开源新模型!99.9%的权重是0,新稀疏性方法代替MoE破解AI胡说八道的关键,居然是给大模型砍断99.9%的连接线?
来自主题: AI技术研报
10334 点击 2025-12-15 12:20
 搜索
搜索
破解AI胡说八道的关键,居然是给大模型砍断99.9%的连接线?

如果说2023年是生成式AI的「出道年」,2024年是「炒作年」,那2025年,就是生成式AI真正走进普通人生活的「落地年」。

6位前DeepMind成员以元系统重塑大模型调用方式,该系统推出的Gemini 3 Pro优化技术在ARC-AGI-2上以54%的成绩夺得榜首,而成本仅为此前最优方法的一半。
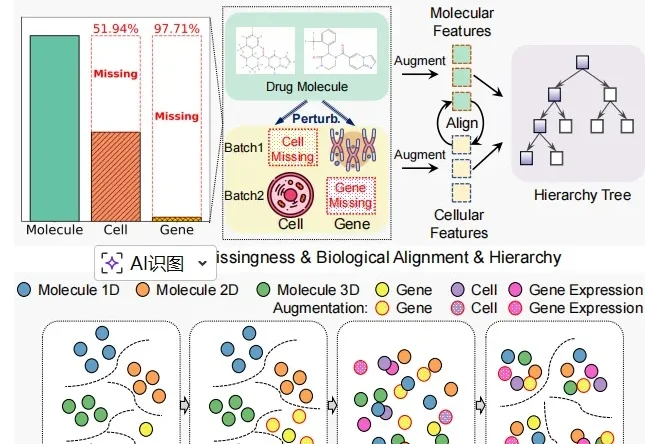
近日,中山大学博士生李孟燃和中国科学院香港创新研究院臧泽林博士及合作者打造出一种名为 CHMR 的 AI 系统,堪比一位拥有细胞之眼的 AI 化学家,能让药物研发变得更精准和更安全。

不仅能“听懂”物体的颜色纹理,还能“理解”深度图、人体姿态、运动轨迹……
邹忌曾经有一个问题:吾与徐公孰美?

在 Physical Intelligence 最新的成果 π0.6 论文里,他们介绍了 π0.6 迭代式强化学习的思路来源:

多语言大模型(MLLM)在面对多语言任务时,往往面临一个选择难题:是用原来的语言直接回答,还是翻译成高资源语言去推理?

在深入技术细节之前,我们先用一张漫画来直观理解 COIDO (Coupled Importance-Diversity Optimization) 解决的核心问题与方案:正如钟离在漫画中所言,面对海量视觉指令数据的选择任务,传统方法需要遍历全部数据才能进行筛选造成大量「磨损」(高昂计算成本)。同时在面对数据重要性和多样性问题时,传统方法往往顾此失彼。

昨天,苹果一篇新论文在 arXiv 上公开然后又匆匆撤稿。原因不明。论文中,苹果揭示了他们开发的一个基于 TPU 的可扩展 RL 框架 RLAX。是的,你没有看错,不是 GPU,也不是苹果自家的 M 系列芯片,而是谷歌的 TPU!还不止如此,这篇论文的研究中还用到了亚马逊的云和中国的 Qwen 模型。
想象一下,只需要一句话描述,AI 就能为你拍出一部完整的短剧?为了让这个想法变成现实,香港大学黄超教授团队开源了 ViMax 框架,并在 GitHub 获得 1.4k + 星标,专注于 Agentic Video Generation 的前沿探索。通过多智能体协作,ViMax 实现了真正的 "自编自导自演"—— 从创意构思到成片输出的完整自动化,把传统影视制作的每个环节都搬进了 AI 世界。
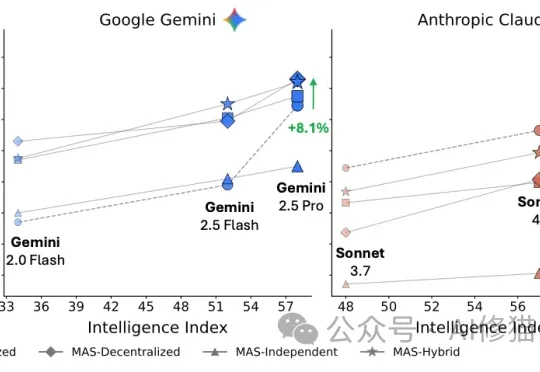
最近,来自Google Research、Google DeepMind和MIT的研究者们联合发表了一项重磅研究。结果显示:盲目增加智能体数量,在很多时候不仅没用,反而会让系统变笨、变慢、变贵。

扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临
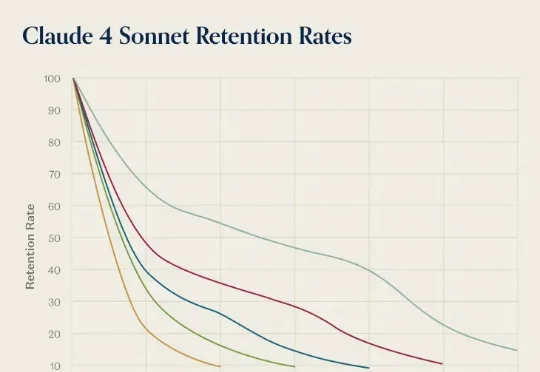
前几天,AI 推理服务供应商 OpenRouter 发布了一份报告《State of AI》,基于平台上 60 多家提供商的 300 多个模型,100 万亿个 token 的交互数据,对 LLM 的实际应用情况进行了分析。报告中,提到了一个「灰姑娘水晶鞋效应」,特别有意思。研究者在分析用户留用数据时发现一个现象:AI 模型发布第一个月进来的用户,往往比后来进来的用户留存率更高。
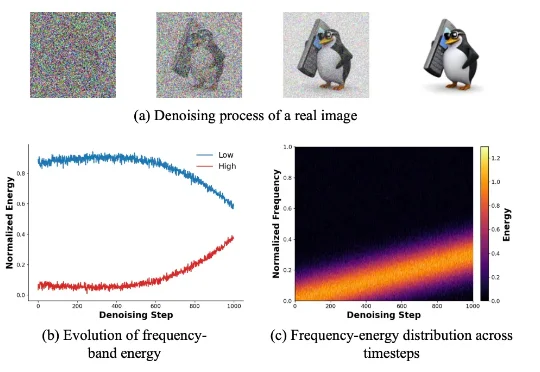
新加坡国立大学 LV Lab(颜水成团队) 联合电子科技大学、浙江大学等机构提出 FeRA (Frequency-Energy Constrained Routing) 框架:首次从频域能量的第一性原理出发,揭示了扩散去噪过程具有显著的「低频到高频」演变规律,并据此设计了动态路由机制。

智能体(Agent),即基于语言模型且具备推理、规划和行动能力的系统,正在成为现实世界 AI 应用的主导范式。

我们以为语言是语法、规则、结构。但最新的Nature研究却撕开了这层幻觉。GPT的层级结构与竟与人大脑里的「时间印记」一模一样。当浅层、中层、深层在脑中依次点亮,我们第一次看见:理解语言,也许从来不是解析,而是预测。

实现通用机器人的类人灵巧操作能力,是机器人学领域长期以来的核心挑战之一。近年来,视觉 - 语言 - 动作 (Vision-Language-Action,VLA) 模型在机器人技能学习方面展现出显著潜力,但其发展受制于一个根本性瓶颈:高质量操作数据的获取。
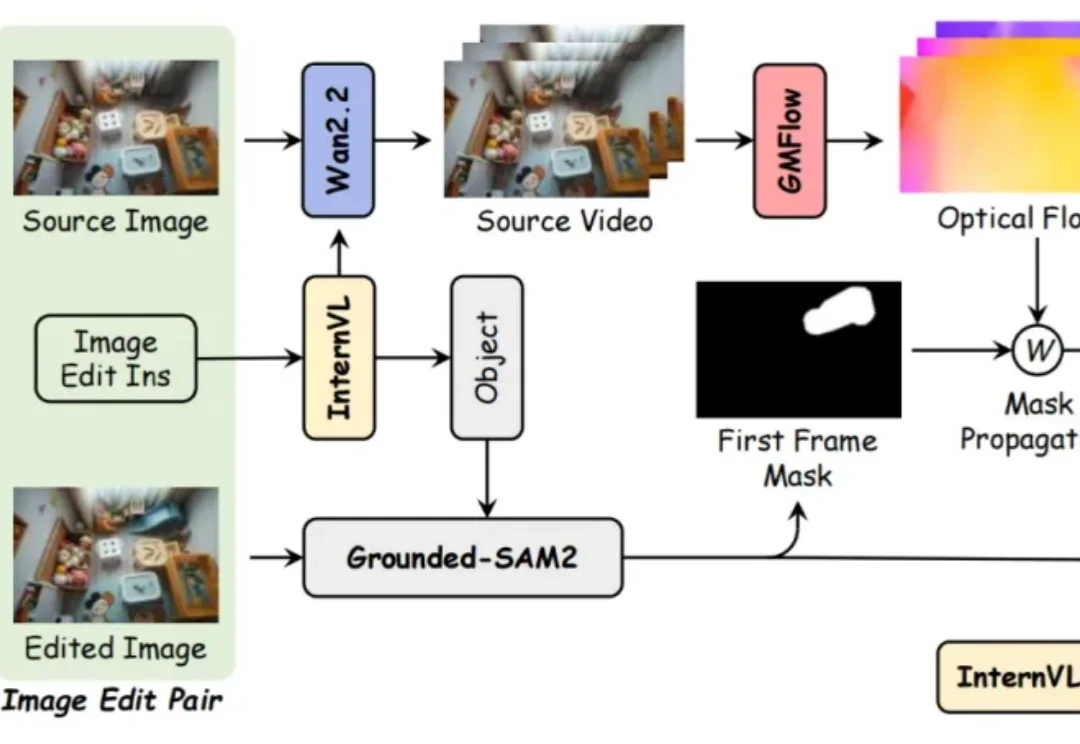
近年来,基于扩散的视频生成模型的最新进展极大地提高了视频编辑的真实感和可控性。然而,文字驱动的视频对象移除添加依然面临巨大挑战:

不久前,NeurIPS 2025 顺利举办,作为人工智能学术界的顶级会议之一,其中不乏学术界大佬的工作和演讲。

觉得大模型消耗的算力过大,英伟达推出的8B模型Orchestrator化身「拼好模」,通过组合工具降本增效,使用30%的预算,在HLE上拿下37.1%的成绩。

白铂 博士,华为 2012 实验室理论研究部主任 信息论首席科学家

随着基础模型的日益成熟,AI领域的研发重心正从“训练更强的模型”转移到“构建更强的系统”。在这个新阶段,适配(Adaptation) 成为了连接通用智能与垂直应用的关键纽带。

近日,Waymo 发布了一篇深度博客,详细介绍了该公司的 AI 战略以及以 Waymo 基础模型为核心的整体 AI 方法。

2025 年 12 月,由 阿里巴巴 联合 中国科学技术大学、浙江大学等机构共同研发的实时虚拟人项目 LiveAvatar 正式对外开源。该项目聚焦长期困扰虚拟人行业的两大技术瓶颈——“实时响应能力”与“长时稳定生成能力”,首次在同一系统中实现了二者的工程级统一。
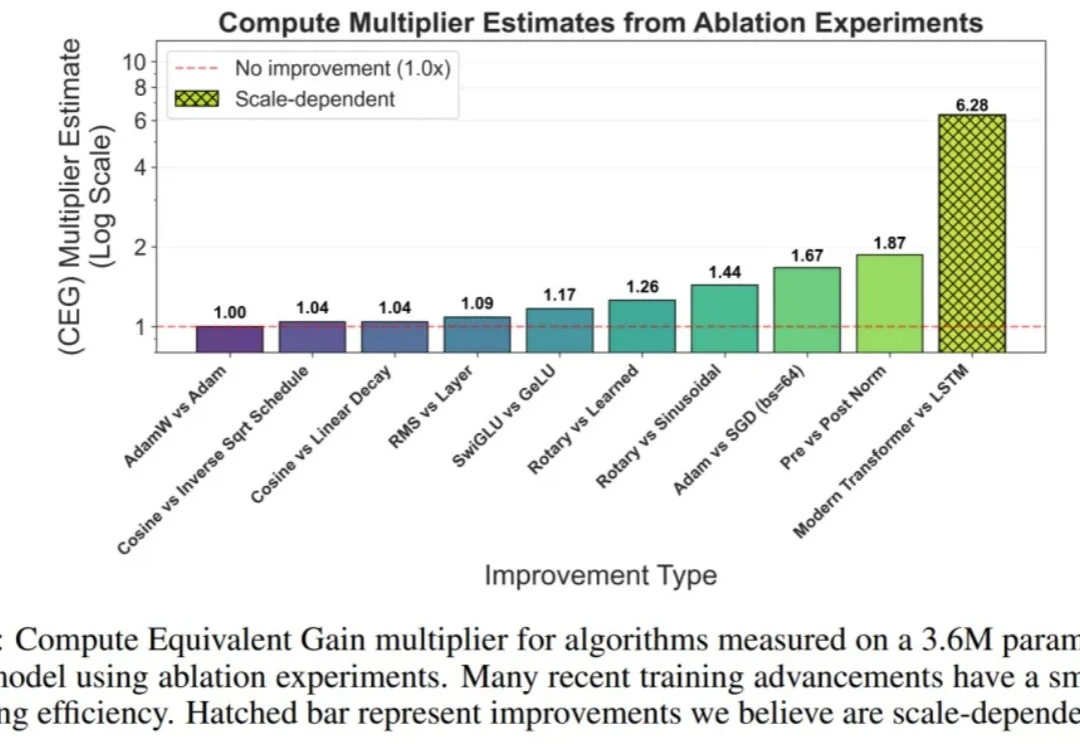
在过去十年中,AI 的进步主要由两股紧密相关的力量推动:迅速增长的计算预算,以及算法创新。
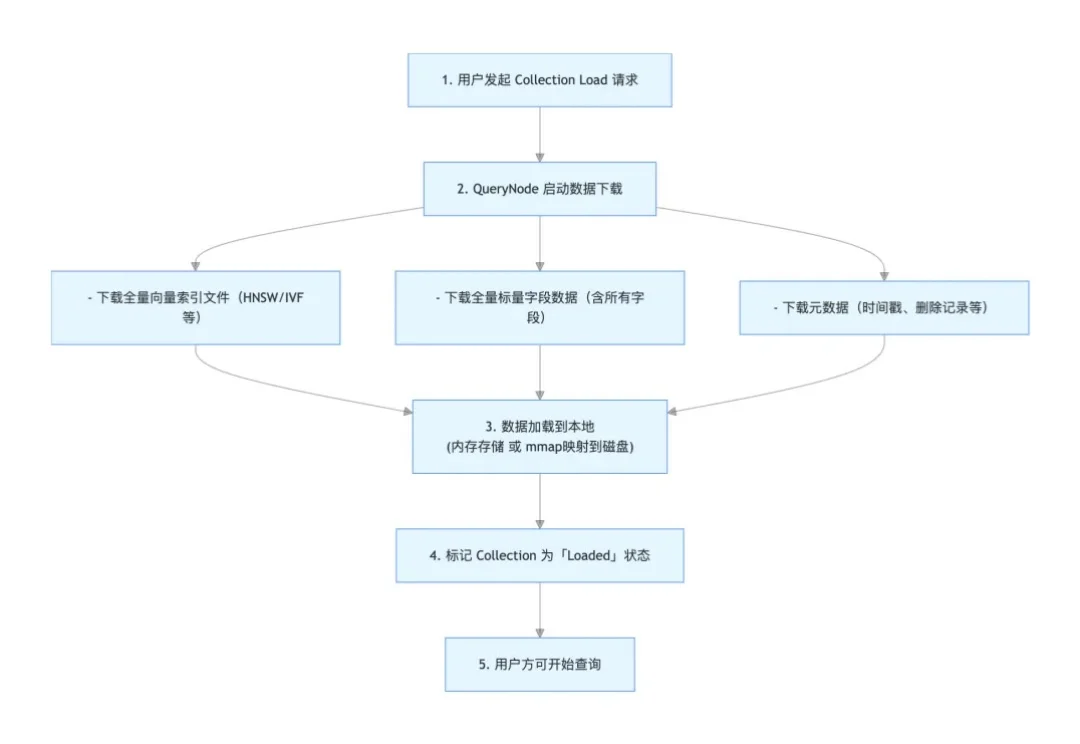
本文为Milvus Week系列第7篇,该系列旨在把Zilliz团队过去半年多积累的先进的技术实践和创新整理成多篇干货深度文章发布。

刚刚,《2025年度AI十大趋势报告》在MEET2026智能未来大会上正式发布。
“真的受够了 Windows 11 中各种莫名其妙的 AI 功能。”
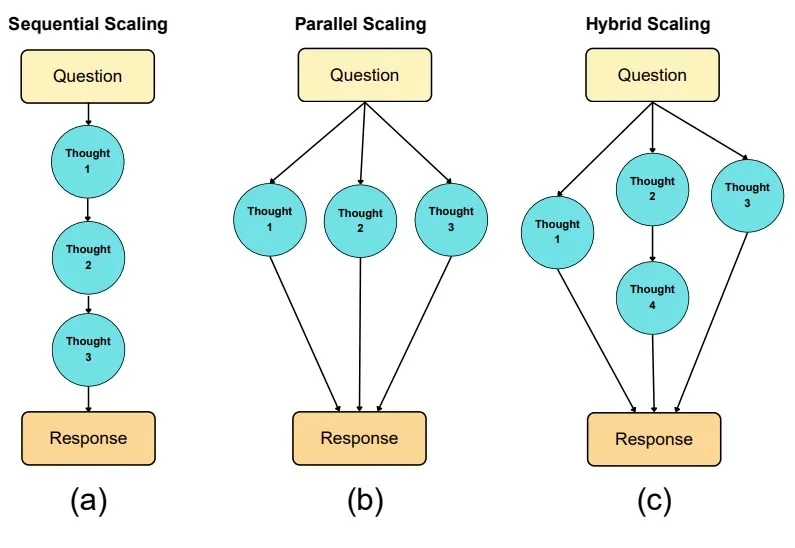
如果说大模型的预训练(Pre-training)是一场拼算力、拼数据的「军备竞赛」,那么测试时扩展(Test-time scaling, TTS)更像是一场在推理阶段进行的「即时战略游戏」。