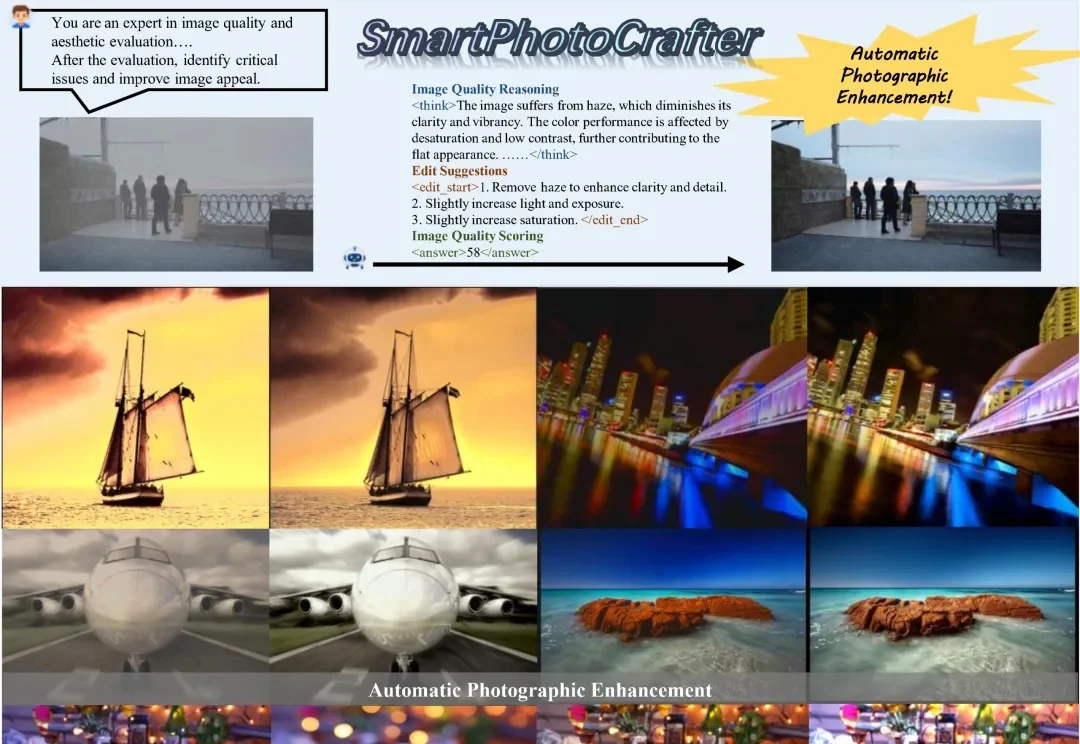
三步训练法+强化学习,vivo新框架把AI修图从“概率生成”训练成了“有审美的修图师”
三步训练法+强化学习,vivo新框架把AI修图从“概率生成”训练成了“有审美的修图师”在日常摄影中,后期处理往往是决定照片最终观感的重要一步。
来自主题: AI技术研报
9402 点击 2026-07-30 10:29
 搜索
搜索
在日常摄影中,后期处理往往是决定照片最终观感的重要一步。

大规模视频扩散模型,画面越来越真,却总在“物理定律”上栽跟头。

WAIC 2026 期间,我们和另外几家媒体(机器之心是其中唯一的专业媒体)共同对来到中国的强化学习奠基人、2024 年图灵奖得主 Richard Sutton 做了一场群访。
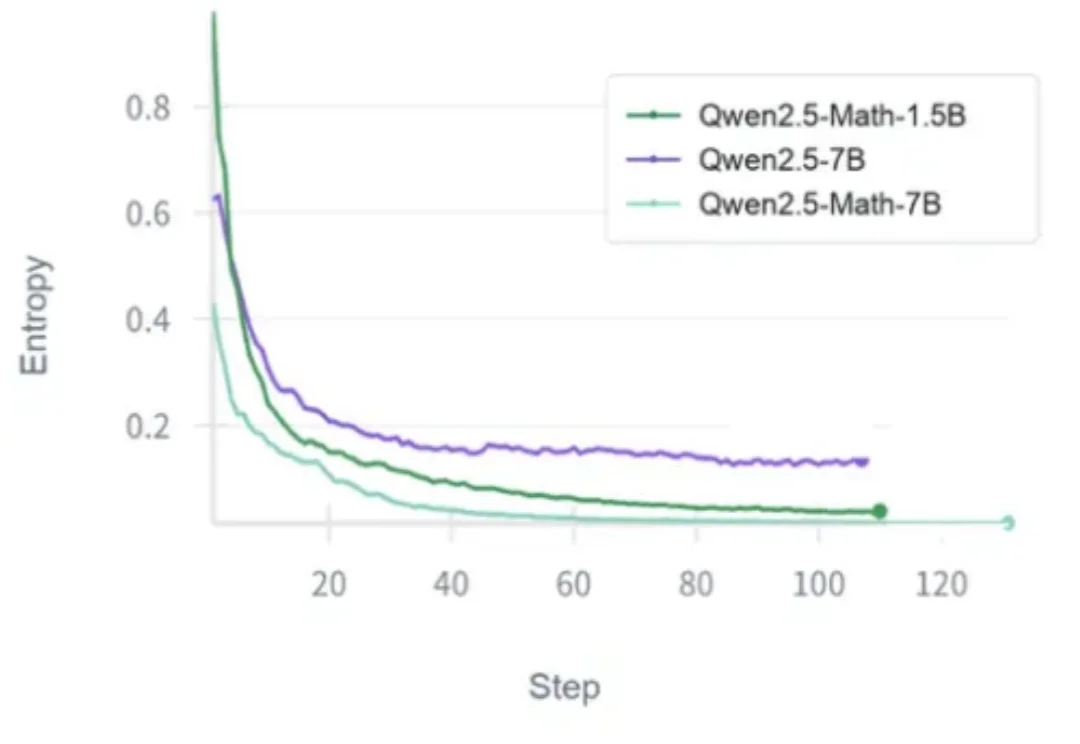
基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards,RLVR)正在成为大模型后训练的关键技术。数学题能判对错,代码能跑测试,可验证奖励让大模型可以通过强化学习持续提升推理能力。

年近 70 岁的图灵奖得主、强化学习之父理查德・萨顿(Richard Sutton),宣布创业了。本周一,Richard Sutton 宣布与 Khurram Javed 共同创立新公司 Oak Lab,要打破当前深度学习方式,用全新的理念构建 AGI。
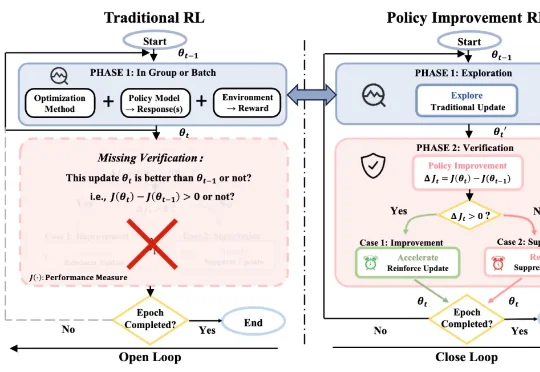
来自北航、北大、美团的研究团队提出了Policy Improvement Reinforcement Learning, PIRL,以及对应的落地算法 PIPO。这项工作关注的是大模型 RL 后训练中一个非常基础、但长期被默认跳过的问题:一次更新在当前数据上看起来优化了学习信号,是否就真的说明模型策略变强了?

ICML 2026大奖公布来了!ICML年度杰出论文奖和时间检验奖,正式公布。其中杰出论文共有9篇入围,含7篇研究论文及2篇立场论文,最终优胜奖3名和荣誉提名6名;ICML时间检验奖花落强化学习领域,DeepMind经典巨作再封神。

做大模型RL微调,你是不是也踩过这些坑?
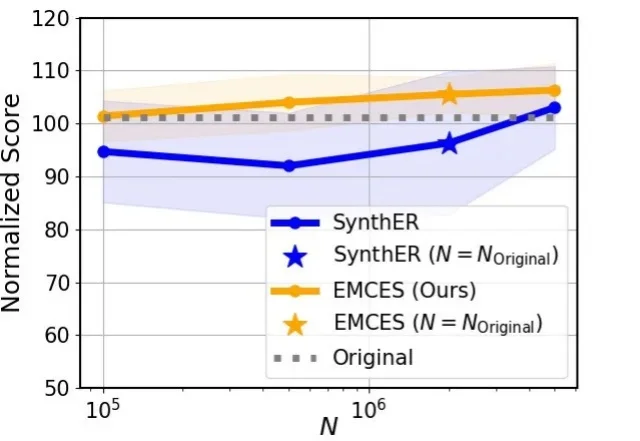
近年来,强化学习在游戏智能体、具身智能、大语言模型等领域取得了显著进展。然而,在真实世界中,强化学习仍面临一个核心难题:高质量样本的获取不仅成本高昂,还可能带来多种风险。因此,样本增强成为缓解强化学习中样本获取成本高、风险大等问题的重要途径之一。

公司由姚颂联合正大集团、清华青年学者于超共同发起,定位为物理智能系统公司,通过世界动作模型(WAM)与强化学习技术,推动机器人在真实商业与工业场景中落地,最终成为一个可信赖的机器人服务提供商。目前已完成近亿美元天使轮系列融资,投资方包括正大集团、华勤技术、九安医疗等多家上市企业,多位国内与国际知名企业家,以及多家一线投资机构。