
CVPR 2026 | 从「单帧」到「分镜」:STAGE重新定义AI电影叙事
CVPR 2026 | 从「单帧」到「分镜」:STAGE重新定义AI电影叙事目前,该论文已录用至 CVPR 2026,相关数据集和模型训练训练和推理代码将逐步开源:究其原因,一个好故事并非一堆漂亮镜头的简单拼接,而是一个有结构、有逻辑的叙事整体。
来自主题: AI技术研报
8449 点击 2026-03-22 09:39
 搜索
搜索
目前,该论文已录用至 CVPR 2026,相关数据集和模型训练训练和推理代码将逐步开源:究其原因,一个好故事并非一堆漂亮镜头的简单拼接,而是一个有结构、有逻辑的叙事整体。

在此背景下,浙江大学研究团队提出了 EasySteer——一个基于 vLLM 构建的高性能、可扩展 LLM Steering 统一框架。该框架通过与 vLLM 推理引擎的深度集成,相比现有 Steering 框架实现了 10.8-22.3 倍的推理加速,同时提供更细粒度的干预控制,并为八大应用场景提供了预计算 Steering 向量与完整复现示例,方便研究者快速上手和对照复现。

最新消息显示,正筹备年底前IPO的OpenAI计划在今年实现日均新增约12名员工的招聘速度,在年底前将员工人数从目前约4500人提升至8000人,几乎实现翻倍。

3 月 20 日,知名 AI 代码编辑器 Cursor 高调发布了所谓的编程模型 Composer 2,结果被网友质疑「套壳」 Kimi K2.5。而从官方口径来看, Composer 2 的性能简直是降维打击:全基准大幅领先前代,首次引入持续预训练,叠加大规模强化学习,能解决需要数百个操作的高难度编程任务。

AI科技评论独家获悉,原华为云中国区副总裁、现华为云新加坡总经理胡维琦将加入 MiniMax,知情人士透露,该项人事变动在 2026 年春节前已达成意向,目前胡维琦正处于入职前的最后准备阶段。

Soul AI 团队(Soul AI Lab) 发布了新的开源模型 SoulX-LiveAct,技术报告中具体提到,该工作能够在 2 张 H100/H200 条件下,达到 20 FPS 的实时流式推理能力,且支持输入图像、音频和指令驱动,即可生成表情生动、情绪可控、拥有丰富全身动作的实时数字人视频。

OpenFinClaw 团队把试图填补这层能力断层的系统,称为“金融龙虾”——一只可以 7×24 小时持续运行、替用户完成分析、建模、执行与风控的 AI 基金经理。但在产品定位上,它更接近一个工具提供商,而不是资产管理方:用户资金仍在自己的账户中,系统只负责提供策略生成、执行与风控能力,把原本属于机构的整套工作流,以工具的形式交付给个人。

ACE 的起点,并不是把音乐生成做成一个更轻的娱乐玩具,而是从专业创作工作流里切进去。ACE Studio 2.0 于 2025 年 12 月正式发布,产品形态也从 AI vocal workstation 进一步扩展为 all in one AI music studio,开始把 AI 歌声、乐器、生成、编辑与 DAW 协同整合成一个AI 音乐创作系统。
2026年开年以来,Harness工程一词热度渐高,OpenAI在2月发布的一篇详细的内部实验报告标题中使用了此词,ThoughtWorks 首席科学家 Martin Fowler 在 X上也表示Harness工程是AI赋能软件开发的关键部分。
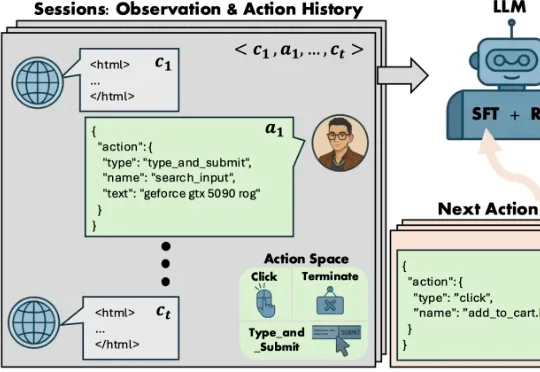
传统的 AI 购物助手更像是一个任务完成机器:接到指令,搜索,下单。他们或许能跑通流程,却完全无法理解用户为何在最后一刻因为一条关于 “夹耳朵” 的差评而放弃支付。简而言之,传统的电商 Agent 只是任务导向的(task-oriented),而不是模拟导向的(simulation-oriented)。为此,来自亚马逊(Amazon)的研究团队提出了名为 Shop-R1 的训练框架 。