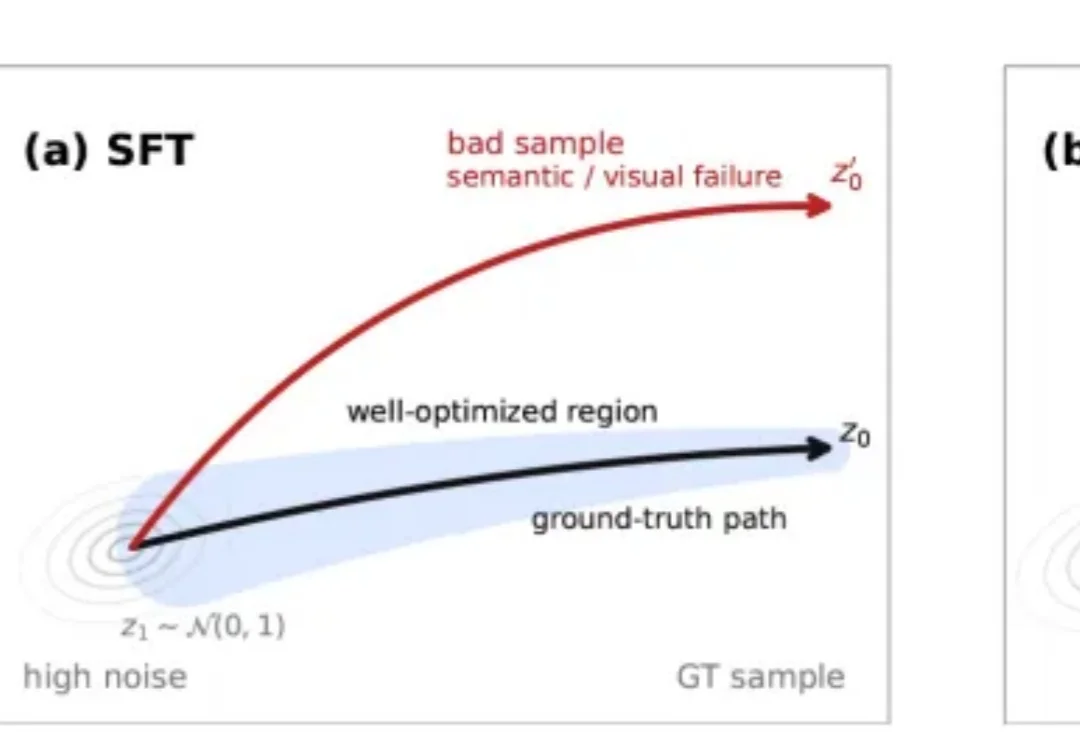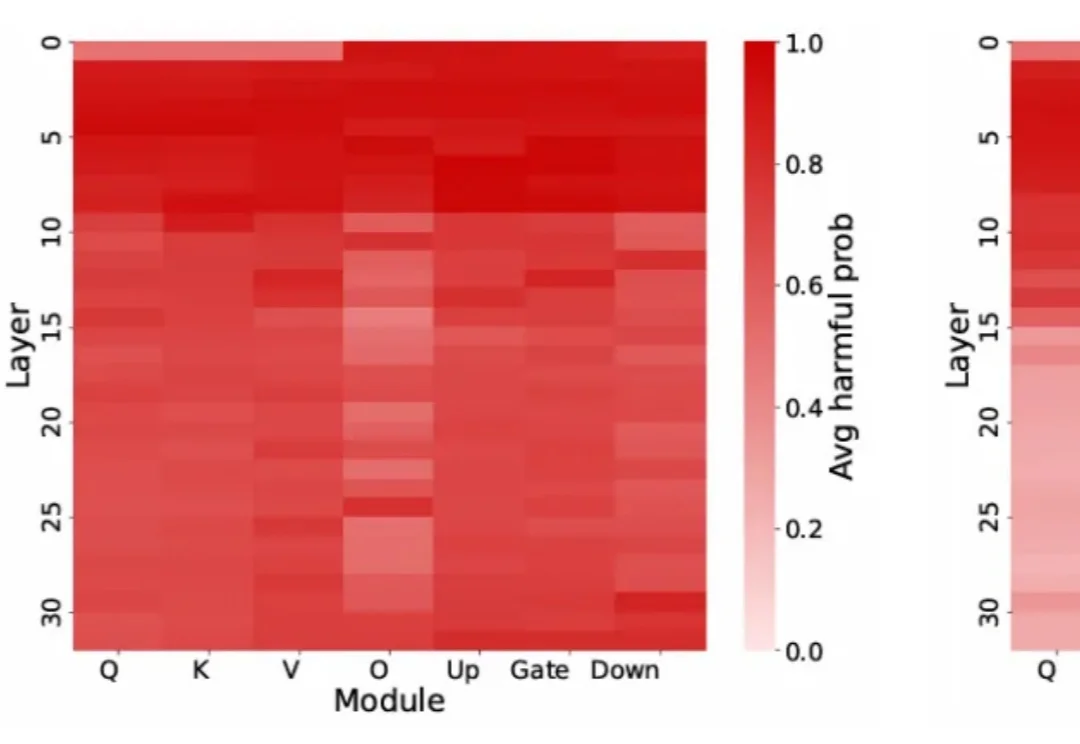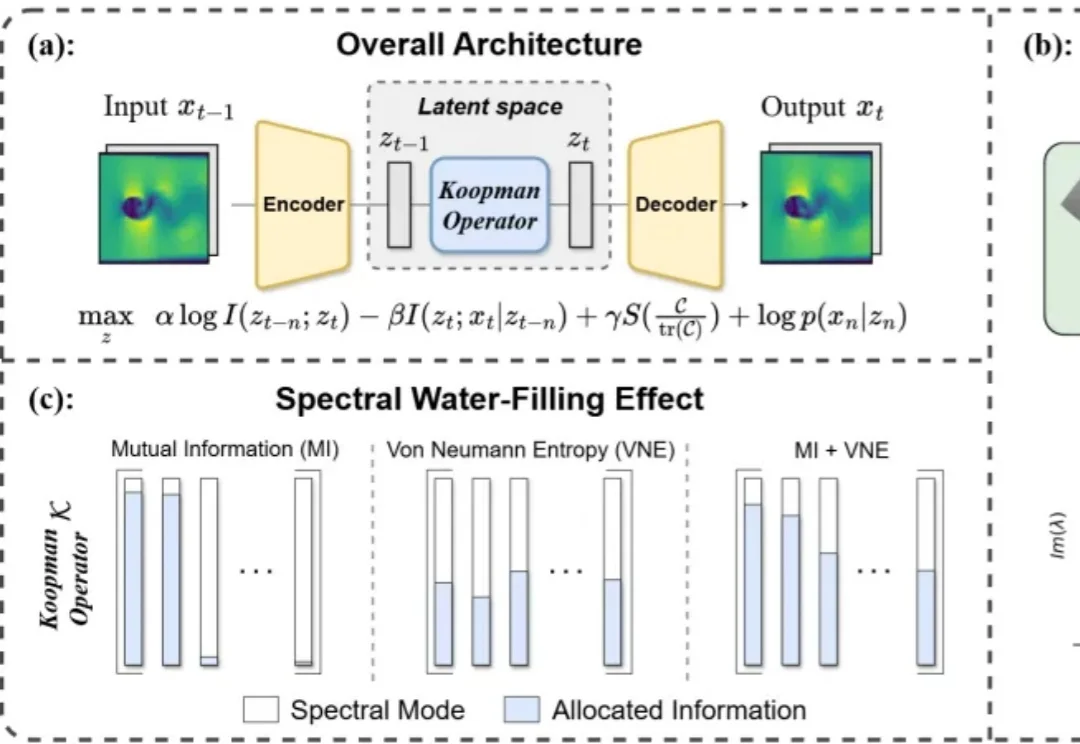
当AI写了80%的代码,谁来找bug?PlayerZero 给你答案
当AI写了80%的代码,谁来找bug?PlayerZero 给你答案PlayerZero 刚刚宣布完成了 1500 万美元的 A 轮融资,由 Foundation Capital 的 Ashu Garg 领投,他也是 Databricks 的早期支持者。这是继 Green Bay Ventures 领投的 500 万美元种子轮之后的又一轮融资。
来自主题: AI资讯
9703 点击 2026-04-26 10:39