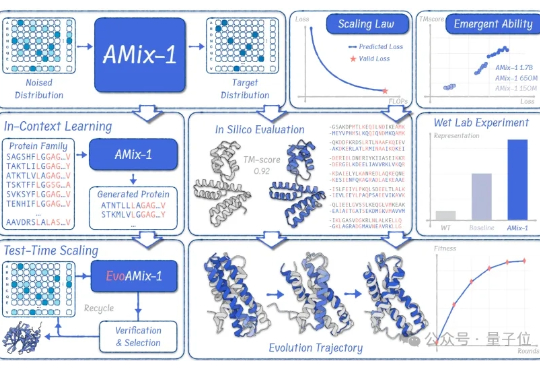
蛋白质基座的GPT时代来了?!
蛋白质基座的GPT时代来了?!蛋白质模型的GPT时刻来了! 清华大学智能产业研究院(AIR)周浩副教授课题组联合上海人工智能实验室发布了AMix-1: 首次以Scaling Law、Emergent Ability、In-Context Learning和Test-time Scaling的系统化方法论来构建蛋白质基座模型。
来自主题: AI技术研报
8294 点击 2025-08-10 16:00
 搜索
搜索
蛋白质模型的GPT时刻来了! 清华大学智能产业研究院(AIR)周浩副教授课题组联合上海人工智能实验室发布了AMix-1: 首次以Scaling Law、Emergent Ability、In-Context Learning和Test-time Scaling的系统化方法论来构建蛋白质基座模型。
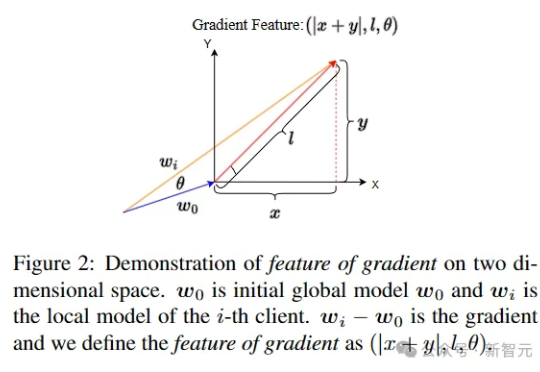
华南理工大学计算机学院AI安全团队长期深耕于人工智能安全,近期联合约翰霍普金斯大学和加州大学圣地亚戈分校聚焦于联邦学习中防范恶意投毒攻击,产出工作连续发表于AI顶刊TPAMI 2025和网络安全顶刊TIFS 2025。
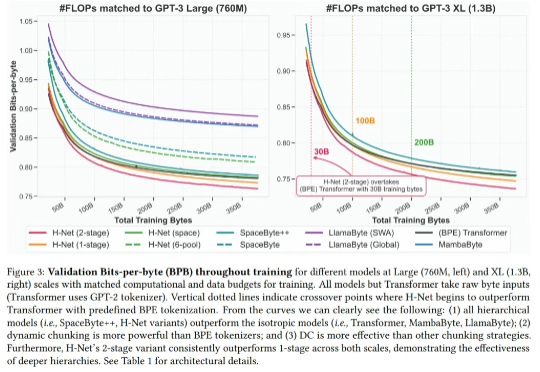
最近,Mamba 作者之一 Albert Gu 又发新研究,他参与的一篇论文《 Dynamic Chunking for End-to-End Hierarchical Sequence Modeling 》提出了一个分层网络 H-Net,其用模型内部的动态分块过程取代 tokenization,从而自动发现和操作有意义的数据单元。
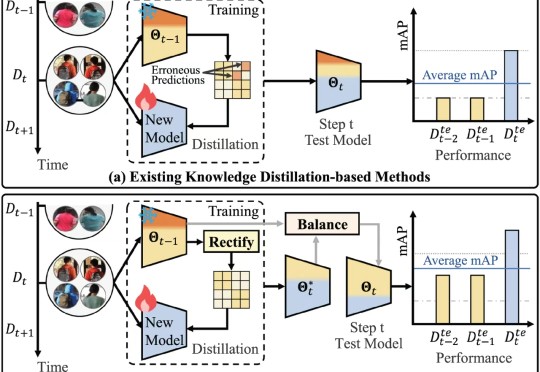
近日,北京大学王选计算机研究所周嘉欢团队在人工智能重要国际期刊 IEEE TPAMI 发布了一项最新的研究成果:LSTKC++ 。
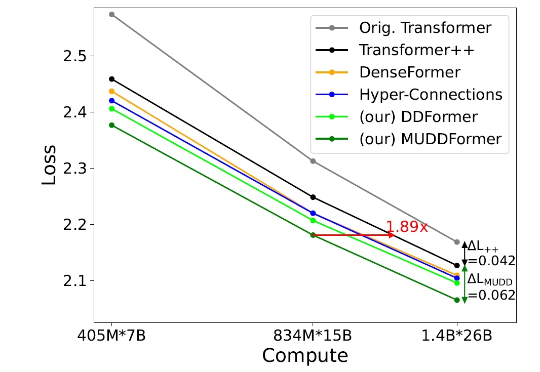
但在当今的深度 Transformer LLMs 中仍有其局限性,限制了信息在跨层间的高效传递。 彩云科技与北京邮电大学近期联合提出了一个简单有效的残差连接替代:多路动态稠密连接(MUltiway Dynamic Dense (MUDD) connection),大幅度提高了 Transformer 跨层信息传递的效率。
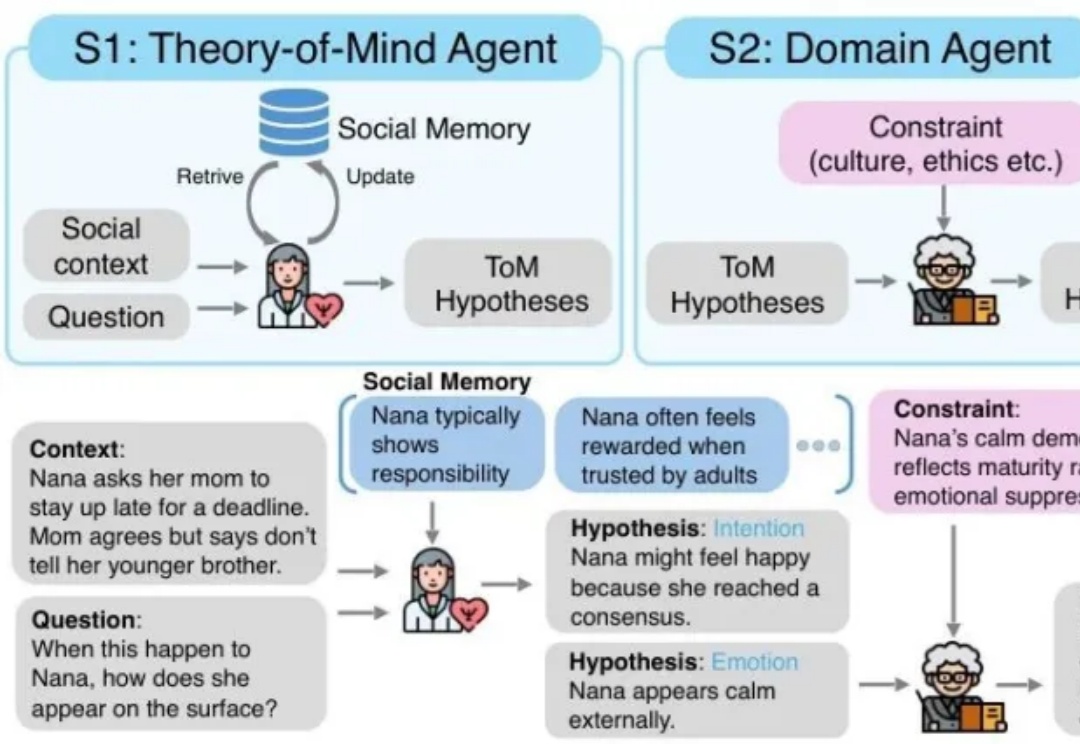
MetaMind是一个多智能体框架,专门解决大语言模型在社交认知方面的根本缺陷。传统的 LLM 常常难以应对现实世界中人际沟通中固有的模糊性和间接性,无法理解未说出口的意图、隐含的情绪或文化敏感线索。MetaMind首次使LLMs在关键心理理论(ToM)任务上达到人类水平表现。

在沙特阿拉伯哈撒地区,一间看似普通的诊所正悄然掀起一场医疗革命:患者缓缓步入诊室,迎接他们的并非传统印象里身着白大褂、神情专注的医生,而是一位 “AI 医生”。
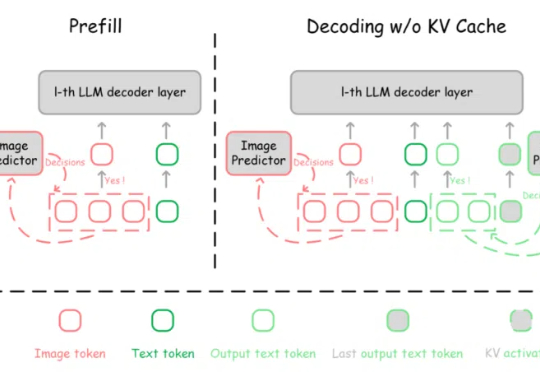
多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。

消费级AI机器人公司「X-ORIGIN-AI」(玄源科技)宣布完成近亿元Pre-A轮融资,本轮由东方富海领投,金鼎资本与联想之星跟投,仁辰资本担任财务顾问。本轮融资距离X-ORIGIN-AI的天使轮融资仅有不到一季度时间,此前的数千万元天使轮由阿尔法公社领投,多名产业投资人跟投。

近日,北京字跳网络技术有限公司登记“即梦AI/Dreamina AI”作品著作权,作品类别为美术。即梦AI作为一款面向创意爱好者的AI表达平台,功能丰富。然而,在我国现行法律框架下,AI生成内容的著作权归属尚无明确界定,引发广泛讨论。