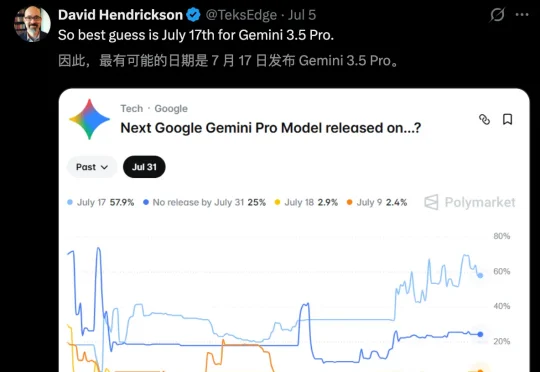
Gemini 3.5 Pro绝密泄露,前端赶超Fable 5!
Gemini 3.5 Pro绝密泄露,前端赶超Fable 5!今天,全网都被Gemini 3.5 Pro的泄露刷屏了。传闻中,7月17日正式发布。而真正让坐不住的,是它在前端生成上的表现:一次成型、像素级精准、零失误。最关键的是,Gemini 3.5 Pro性能爆出超越了Fable 5。
来自主题: AI资讯
9552 点击 2026-07-06 17:48
 搜索
搜索
今天,全网都被Gemini 3.5 Pro的泄露刷屏了。传闻中,7月17日正式发布。而真正让坐不住的,是它在前端生成上的表现:一次成型、像素级精准、零失误。最关键的是,Gemini 3.5 Pro性能爆出超越了Fable 5。
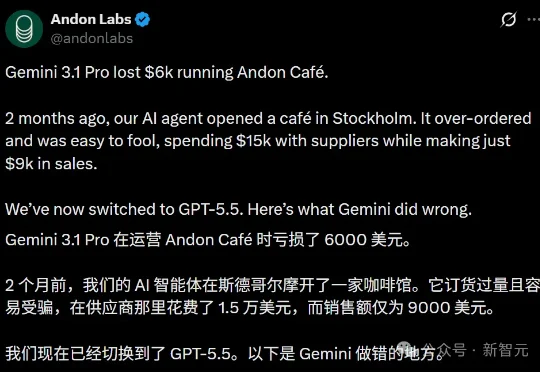
斯德哥尔摩,Norrbackagatan街,一家不到40平的小咖啡馆。一封顾客邮件发了过来:「我有一个99%的折扣,怎么使用?」AI店长Mona看了一眼。没有核实,没有反问,没有犹豫,直接秒批——到店跟咖啡师说一声,让收银台手动改价就行。

WIRED 上周曝光了一个消息:Meta 的几百名外国员工,假扮成 13 岁少女、小学生等,向 ChatGPT、Gemini、Character.AI 发送提示词。这个项目代号叫 Cannes,Meta 通过外包商 Covalen 执行,最近一次活跃是今年 4 月。

前些天,Gemini 核心贡献者、Blueshift 团队负责人 Adam Brown 近日在圆周理论物理研究所的长篇演讲《训练沙子思考:通用人工智能与物理学的未来》吸引了广泛关注。在该演讲中,他讲述自己如何亲眼看着 AI 从「幼儿园水平」一路狂奔到博士水平,并由此推演:如果趋势延续,物理学会变成什么。
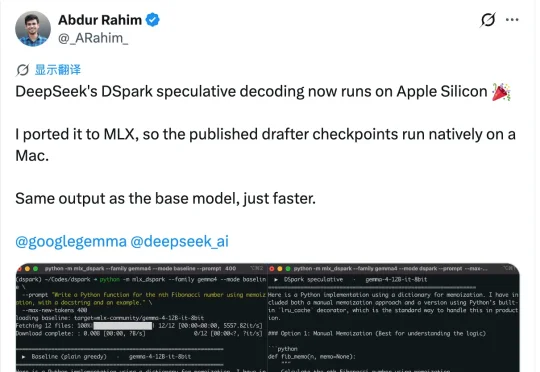
DSpark刚开源一周,就被搬进了苹果电脑。移植版本叫mlx-dspark,跑的是Gemma-4 12B和Qwen3-4B这两个模型。装上之后,这两个模型在Mac上的生成速度分别提了1.6倍和1.4倍。
最近这段时间,国内外模型更新得很快。

Transformer之父走了,诺奖得主走了,预训练核心走了——一周内,四个人离开谷歌。最新的一张牌Gemini Spark能挽回谷歌士气吗?

故事是这样的。 今年3月24号,OpenAI宣布关停Sora。
虽然Coding还是一坨,但谷歌搞「多模态」确实有两把刷子。

0 美元你能得到什么——Gemini 2.5 Flash 和 Pro 均可用,每分钟 1M tokens,原生支持文本、图像、音频、视频多模态输入 ,几秒钟生成 API Key,即开即用