
jina-embeddings-v5-omni 发布!全模态向量小模型
jina-embeddings-v5-omni 发布!全模态向量小模型jina-embeddings-v5-omni正式发布,我们把 v5-text 向量模型的能力延伸到图像、音频和视频。文本侧不变,v5-omni 产出的文本向量与 v5-text逐字节一致,无需重建任何已有索引。
来自主题: AI资讯
9484 点击 2026-05-14 20:31
 搜索
搜索
jina-embeddings-v5-omni正式发布,我们把 v5-text 向量模型的能力延伸到图像、音频和视频。文本侧不变,v5-omni 产出的文本向量与 v5-text逐字节一致,无需重建任何已有索引。
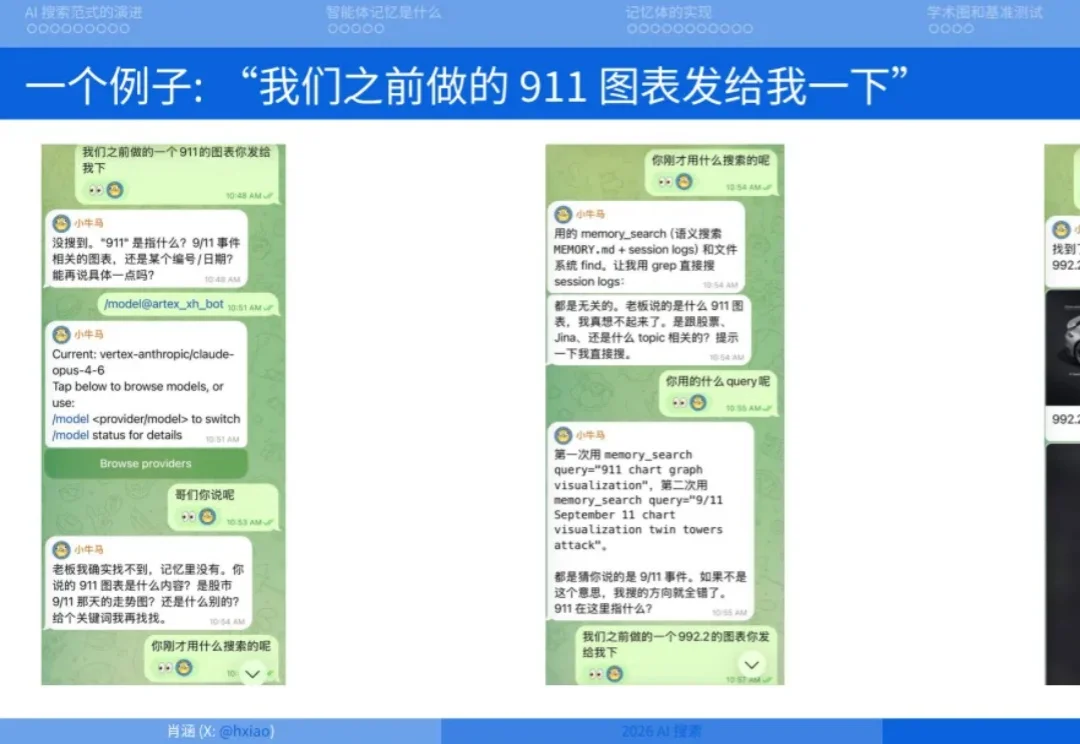
4 月 18 日,Elastic 中国 AI 搜索技术大会在北京召开。以下内容整理自 Elastic 全球副总裁肖涵,原 Jina AI 创始人兼 CEO 在会上的演讲。肖涵讲述了 AI 搜索的发展历程以及为什么说在 2026 年做 AI 搜索基本就是在做智能体记忆 (Agent Memory)。

Google 最近发了 Gemini Embedding 2,他们第一个原生多模态向量模型。文本、图像、视频、音频、文档,全部映射到同一个 3072 维向量空间。这是 Omni Embedding(全模态向量模型)的大趋势:一个架构吃下所有模态,从 jina-embeddings-v4 到 Omni-Embed-Nemotron 再到 Omni-5,大家都在往这个方向收敛。
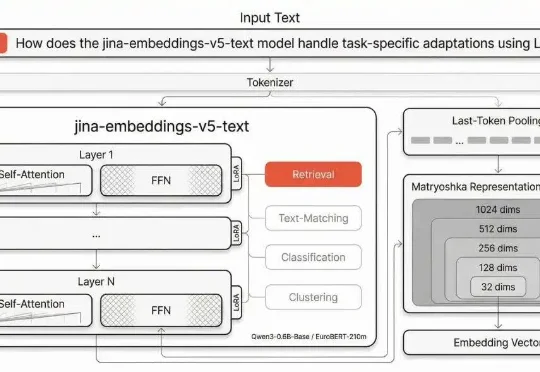
jina-embeddings-v5-text 岁在丙午,开年即战。Jina AI 的五代目向量模型春节期间正式发布。1B 参数内世界第一,全面刷新向量模型的性能天花板!

今天我们正式发布 Jina-VLM,这是一款 2.4B 参数量的视觉语言模型(VLM),在同等规模下达到了多语言视觉问答(Multilingual VQA)任务上的 SOTA 基准。Jina-VLM 对硬件需求较低,可在普通消费级显卡或 Macbook 上流畅运行。

纽约时间 2025 年 10 月 9 日早上 9 点,Elastic (NYSE: ESTC) 在其官网宣布完成了对 Jina AI 的收购。ina AI 原 CEO 肖涵将在 Elastic 担任 VP of AI,负责 AI 方向的战略和研发。由肖涵带领的核心Jina团队将继续在向量模型、重排器、Reader 和小模型上推进搜索 AI 的发展。

我们正式推出第三代重排器 Jina Reranker v3。它在多项多语言检索基准上刷新了当前最佳表现(SOTA)。这是一款仅有 6 亿参数的多语言重排模型。我们为其设计了名为 “last but not late” (中文我们译作后发先至)的全新交互机制,使其能接受 Listwise 即列式输入,在一个上下文窗口内一次性完成对查询和所有文档的深度交互。
模型上下文协议 (MCP) 是连接 LLM/Agent 与外部工具的通信标准。它允许 LLM 动态发现并调用 API工具,将他们串成一个完整的工作流,从而实现自主规划、推理与执行。 上个月我们悄悄发布

几周前,我们发布了 jina-embeddings-v4 模型的 GGUF 版本,大幅降低了显存占用,提升了运行效率。不过,受限于 llama.cpp 上游版本的运行时,当时的 GGUF 模型只能当作文本向量模型使用而无法支持多模态向量的输出。

我们今天正式开源 jina-code-embeddings,一套全新的代码向量模型。包含 0.5B 和 1.5B 两种参数规模,并同步推出了 1-4 bit 的 GGUF 量化版本,方便在各类端侧硬件上部署。