
告别多奖励跷跷板:Flow-OPD将多教师OPD带入图像生成
告别多奖励跷跷板:Flow-OPD将多教师OPD带入图像生成今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。
来自主题: AI技术研报
7304 点击 2026-05-26 10:07
 搜索
搜索
今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。
5 月 22 日,Tri Dao 在社交媒体上转发了 Han Guo 的一条推文。他还写道:「经过一些数学重写,结果发现 Transformer 的所有内容都是一系列 GEMM + epilogue(矩阵乘法加尾声)。给定一些优化的原语,LLM(以及新手)就可以为所有 Transformer 操作编写光速内核!」

“这是我见过最激烈的竞争之一,甚至可能是资本主义历史上最激烈的竞争。”这是谷歌 DeepMind CEO Demis Hassabis 在访谈中对这场 AI 竞赛的评论。著名科技作家 Sebastian Mallaby 甚至直接将 AI 类比为现代的曼哈顿计划。

姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。
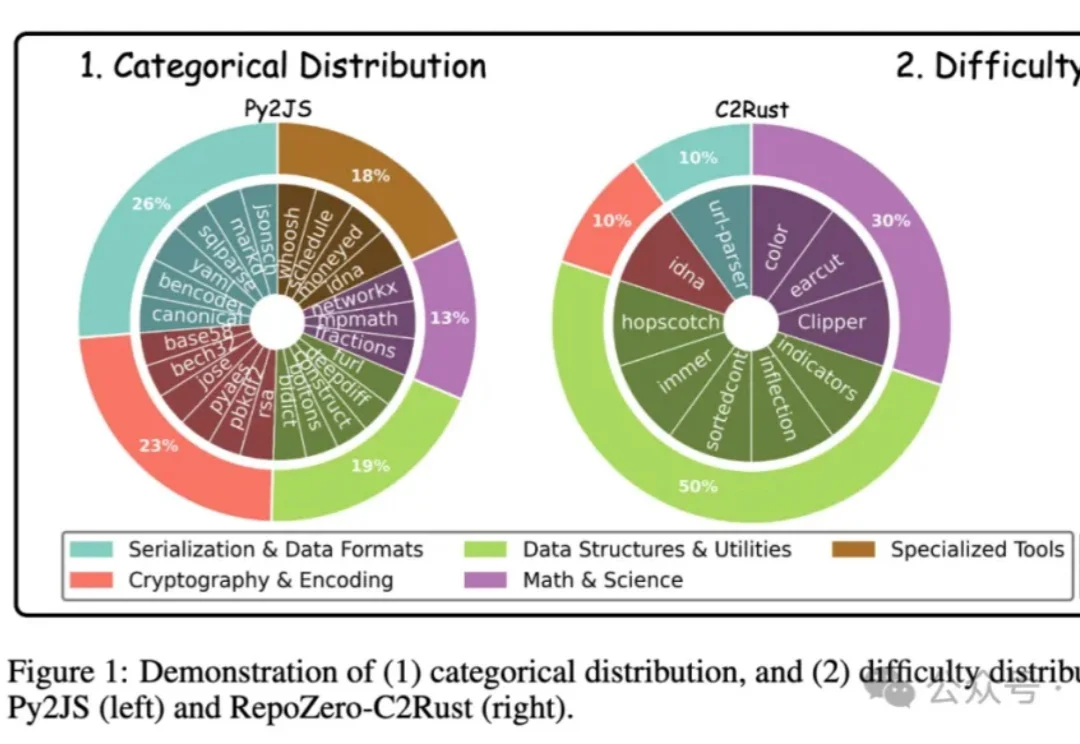
投稿来自北京大学与百度联合团队,他们提出了首个面向“从零生成完整代码仓库”的评测基准 RepoZero,通过跨语言复现任务与自验证框架 ACE,推动代码补全更近一步迈向自动化软件工程。
5 月 19 日,Andrej Karpathy 在 X 上宣布加入 Anthropic。个人近况:我已加入 Anthropic。我认为未来几年在 LLMs 前沿的工作将具有特别重要的塑造性。我非常激动能加入这里的团队并重回研发。我仍然对教育充满热情,并计划适时恢复我在这方面的工作
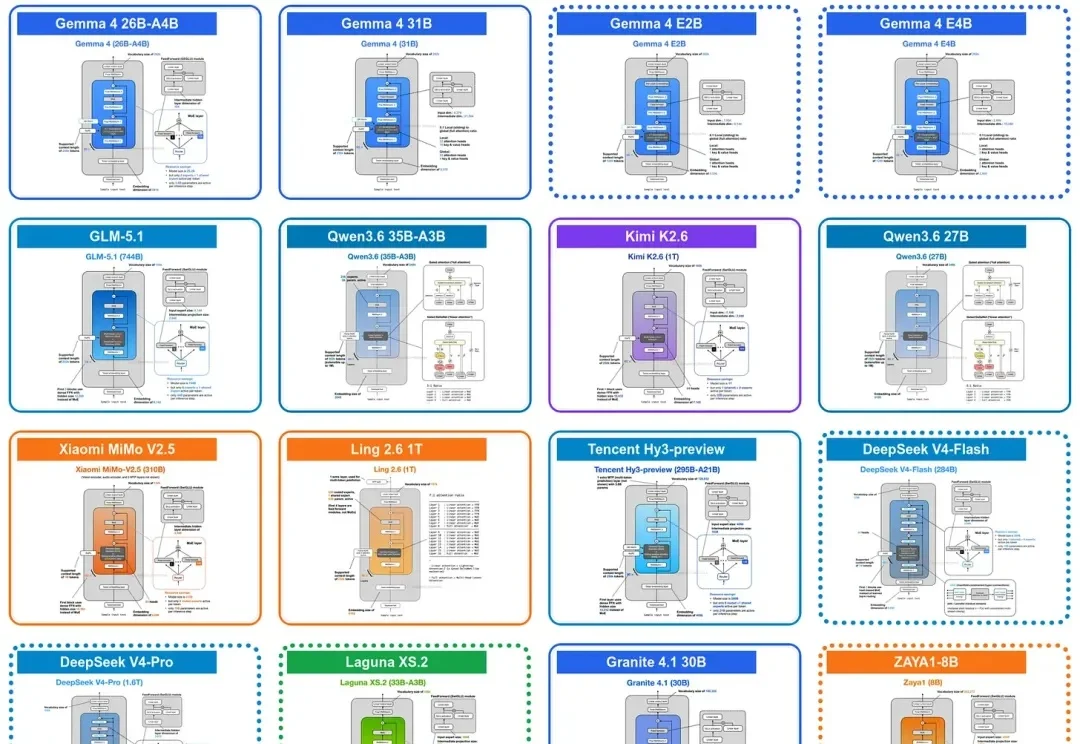
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。

Lecun这次是真跟Hinton爆了……
近期,LLM 已经在 IMO 上取得了很好的成绩,在一些研究级数学上(如短程证明、组合构造)也有所进展。但如果真正让 LLM 去处理提出数十年的数学猜想,结果会是如何?
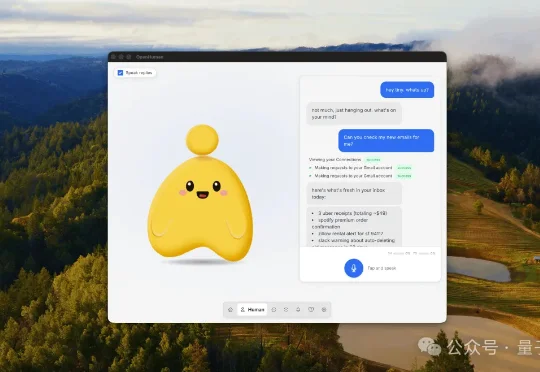
虾在前,马当道,居然还有新物种能在Agent赛道突出重围。OpenHuman连续霸榜GitHub Trending第一,狂揽9k+ Star,一天就涨千星。和虾马不一样,Human不用你花心思养,还能反过来主动了解你。