
NeRF之父斩获「青年图灵奖」!重写3D世界的人赢了
NeRF之父斩获「青年图灵奖」!重写3D世界的人赢了计算机界「青年图灵奖」出炉了!今天,2025 ACM Grace Hopper大奖正式揭晓,一锤砸中了两位灵魂人物——获奖理由只有一个词:NeRF(神经辐射场)。
来自主题: AI资讯
9275 点击 2026-06-06 09:50
 搜索
搜索
计算机界「青年图灵奖」出炉了!今天,2025 ACM Grace Hopper大奖正式揭晓,一锤砸中了两位灵魂人物——获奖理由只有一个词:NeRF(神经辐射场)。

最近,谷歌联合ResNet作者何恺明、谢赛宁、NeRF先驱Jonathan T. Barron、 3D图形学名家Thomas Funkhouser,正式发布了Vision Banana。它向世界宣告:视觉AI终于不再需要那些臃肿的任务头了,理解,本质上只是生成过程中的一次「对齐」。

在 3D 视觉领域,如何从二维图像快速、精准地恢复三维世界,一直是计算机视觉与计算机图形学最核心的问题之一。从早期的 Structure-from-Motion (SfM) 到 Neural Radiance Fields (NeRF),再到 3D Gaussian Splatting (3DGS),技术的演进让我们离实时、通用的 3D 理解越来越近。

生成式 AI 正在重写 3D 内容的生产流程:从“DCC 工具 + 外包”的线性供给,演进到“资产规模化生成 + 管线可用”的指数供给模式。过去五年,技术范式经历了从实时体积渲染,NeRF,到Score Distillation,3D扩散的快速迭代;需求侧则由游戏与影视,向3D 打印、电商样机、数字人、教育培训、以及AR/VR等长尾场景外溢。
近年来,NeRF、SDF 与 3D Gaussian Splatting 等方法大放异彩,让 AI 能从图像中恢复出三维世界。但随着相关技术路线的发展与完善,瓶颈问题也随之浮现:
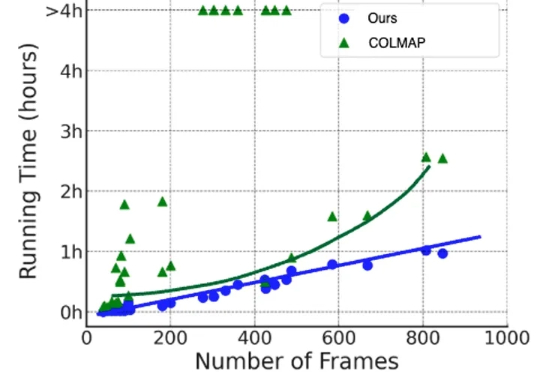
在三维重建、NeRF 训练、视频生成等任务中,相机参数是不可或缺的先验信息。传统的 SfM/SLAM 方法(如 COLMAP)在静态场景下表现优异,但在存在人车运动、物体遮挡的动态场景中往往力不从心,并且依赖额外的运动掩码、深度或点云信息,使用门槛较高,而且效率低下。

只需一段视频,就可以直接生成可用的4D网格动画?!来自KAUST的研究团队提出全新方法V2M4,能够实现从单目视频直接生成高质量、显式的4D网格动画资源。
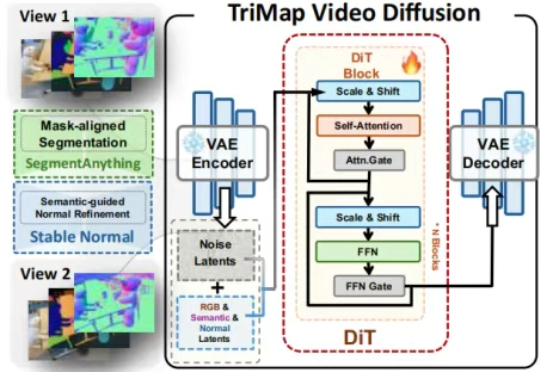
最少只用2张图,AI就能像人类一样理解3D空间了。ICCV 2025最新中稿的LangScene-X:以全新的生成式框架,仅用稀疏视图(最少只用2张图像)就能构建可泛化的3D语言嵌入场景,对比传统方法如NeRF,通常需要20个视角。
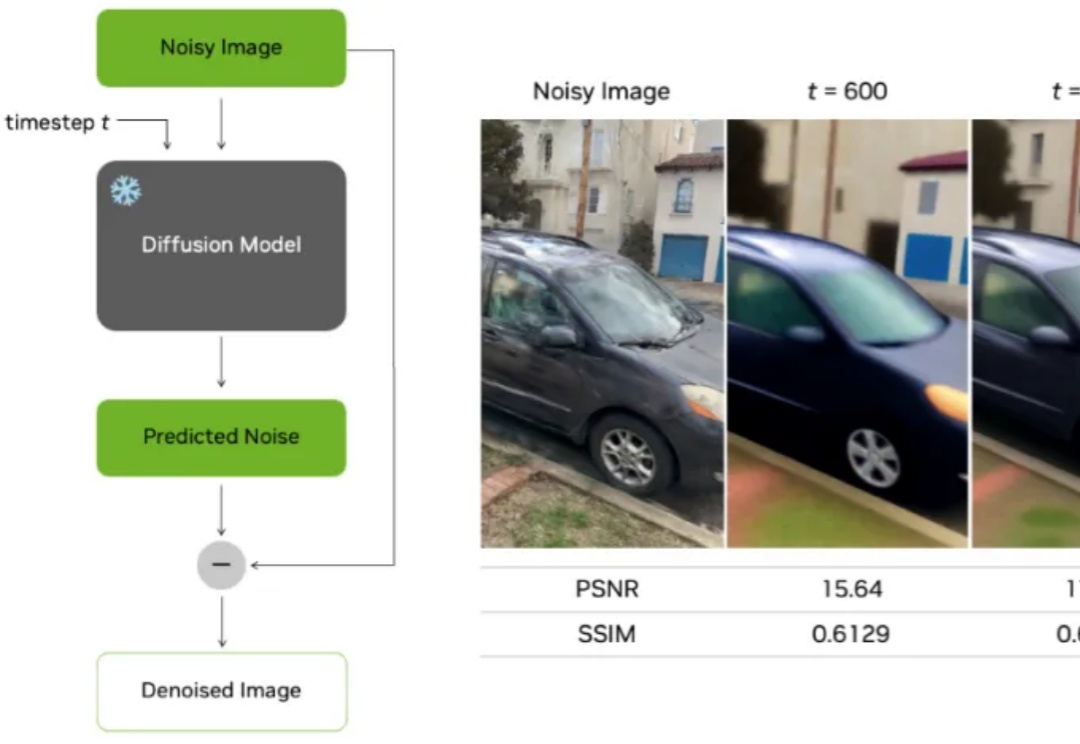
在 3D 重建领域,无论是 NeRF 还是最新的 3D Gaussian Splatting(3DGS),在生成逼真新视角时仍面临一个核心难题:视角一旦偏离训练相机位置,图像就容易出现模糊、鬼影、几何错乱等伪影,严重影响实际应用。

三维重建是计算机图形学的经典任务,具有很强的使用价值。近年来,诸如神经辐射场的隐式场方法 [1][2][3][4] 正成为重建任务广泛采用的表示。