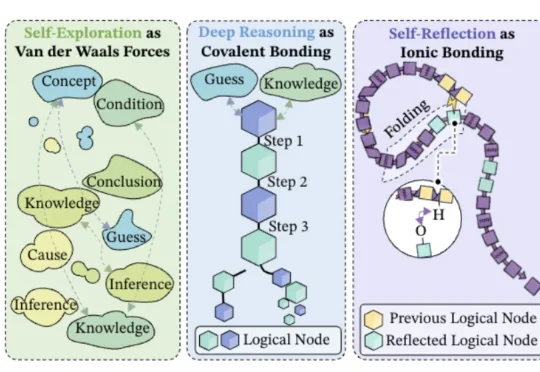
字节Seed用化学思想搞AI,把DeepSeek-R1的脑回路拆成了分子结构
字节Seed用化学思想搞AI,把DeepSeek-R1的脑回路拆成了分子结构字节Seed都开始用化学思想搞大模型了——深度推理是共价键、自我反思是氢键、自我探索是范德华力?!
来自主题: AI技术研报
10239 点击 2026-02-24 15:37
 搜索
搜索
字节Seed都开始用化学思想搞大模型了——深度推理是共价键、自我反思是氢键、自我探索是范德华力?!

机器之心编译 如果把人生看作一个开放式的大型多人在线游戏(MMO),那么游戏服务器在刚刚完成一次重大更新的时刻,规则改变了。 自 2022 年 ChatGPT 惊艳亮相以来,世界已经发生了深刻变化。在

近日,微软Bing Ads与DKI团队发表论文《AdNanny: One Reasoning LLM for All Offline Ads Recommendation Tasks》,宣布基于DeepSeek-R1 671B打造了统一的离线推理中枢AdNanny,用单一模型承载所有离线任务。这标志着从维护一系列任务特定模型,转向部署一个统一的、推理中心化的基础模型,从

以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务
过去两年,大模型的推理能力出现了一次明显的跃迁。在数学、逻辑、多步规划等复杂任务上,推理模型如 OpenAI 的 o 系列、DeepSeek-R1、QwQ-32B,开始稳定拉开与传统指令微调模型的差距。直观来看,它们似乎只是思考得更久了:更长的 Chain-of-Thought、更高的 test-time compute,成为最常被引用的解释。
2025 年 1 月 20 日,DeepSeek(深度求索)正式发布了 DeepSeek-R1 模型,并由此开启了新的开源 LLM 时代。在 Hugging Face 刚刚发布的《「DeepSeek 时刻」一周年记》博客中,DeepSeek-R1 也是该平台上获赞最多的模型。

「服务器繁忙,请稍后再试。」
昨晚夜里快12点,AI视频公司PixVerse毫无预兆的发了一个项目。PixVerse R1,下一代实时世界生成模型。这玩意你看文字,可能不是很好理解,我直接放一个官方的demo视频,大家的感觉应该会强一些。

GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。