
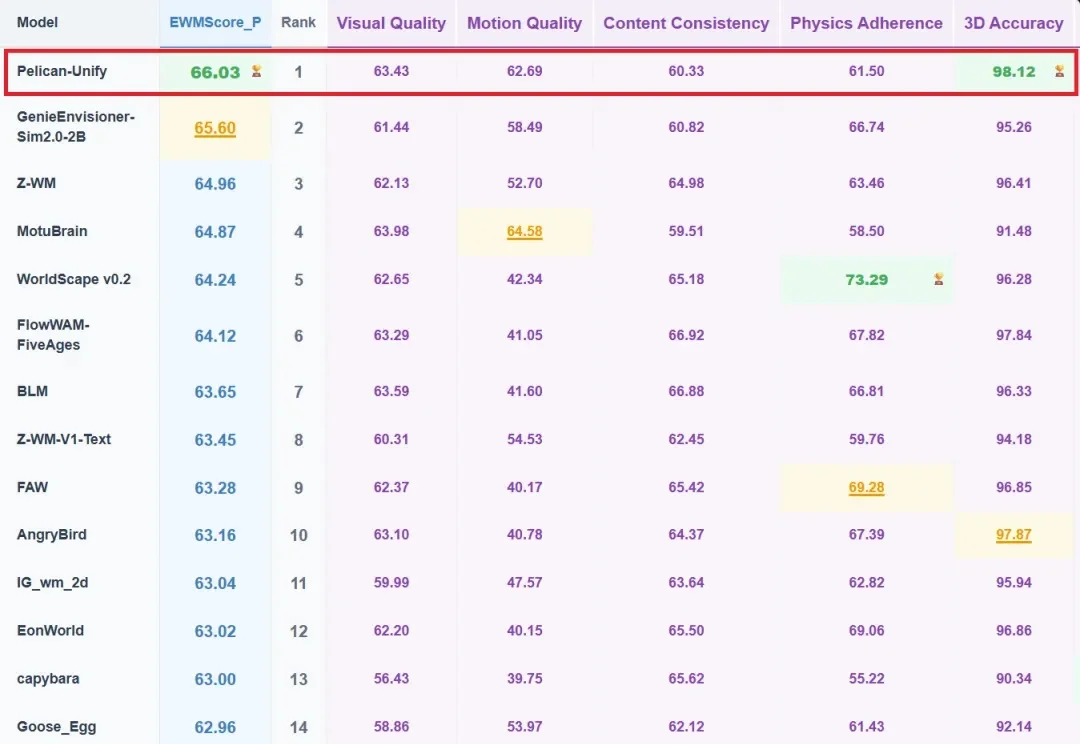
断崖第一!深度机智Z-WM再夺WorldArena冠军
断崖第一!深度机智Z-WM再夺WorldArena冠军2026 年 5 月,深度机智(DeepCybo)迎来成立一周年。
来自主题: AI资讯
9697 点击 2026-05-18 16:50
 搜索
搜索
2026 年 5 月,深度机智(DeepCybo)迎来成立一周年。

世界模型(World Model),想必你已经在很多场合听过这个术语了。它有时出现在视频生成领域,有时又出现在具身智能领域;它们的含义还有所差别,甚至看起来像是完全不同的概念。
最近,全球的网民都化身「监工」,围观了 Figure AI 的人形机器人直播在物流传送带上连续几十个小时,不间断地分拣包裹。
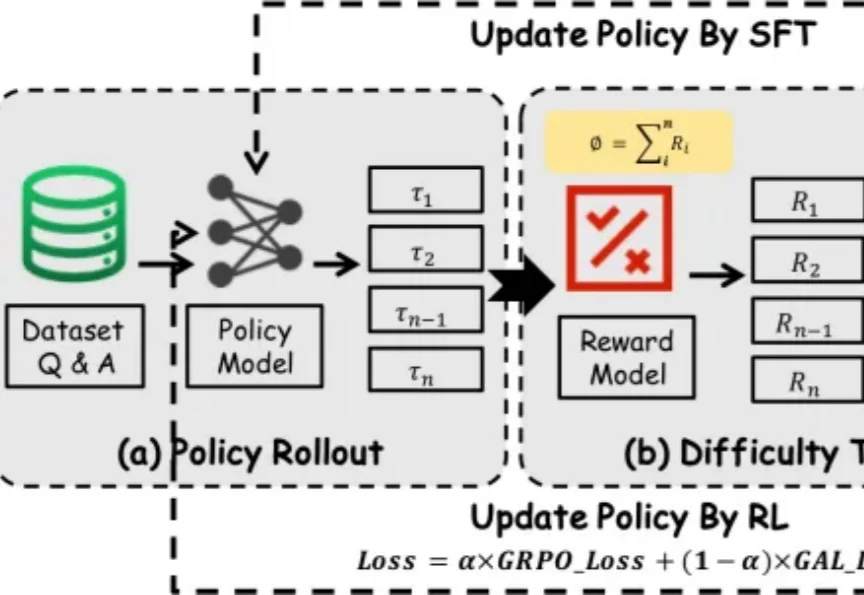
过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。

LeCun念叨了好几年的JEPA,被160行代码给复刻了。GitHub上有个开发者,用极简单文件形式,用PyTorch把JEPA核心系列全部实现了一遍,从I-JEPA到LeWorldModel,五个变体一个没落,就为了——
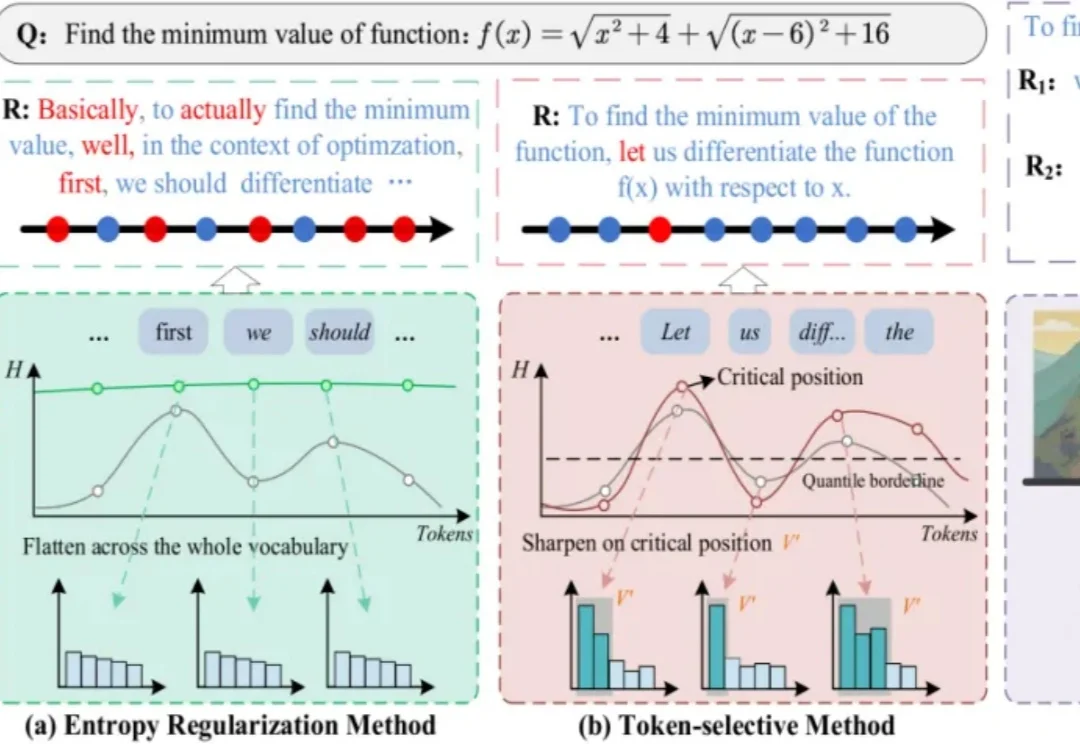
I²B-LPO 是一个面向 RLVR 后训练的探索增强框架,通过改进 rollout 策略引导模型生成更多样化的推理轨迹,将探索行为从 “重复采样” 推进到 “在关键节点生成更具区分度的推理轨迹”,在多个数学基准上同时提升准确率与语义多样性,最高分别达 5.3% 和 7.4%。该工作接收于 ACL 2026 Main,来自阿里达摩院 - 智能决策团队。

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。

随着大模型后训练(Post-training)技术的发展,强化学习(RL)在提升模型推理能力方面的表现备受瞩目。

近日,原力灵机开源的具身智能原生框架 Dexbotic 宣布正式支持以 RLinf 作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着 VLA 模型研发中长期存在的「SFT 与 RL 割裂」问题,正在被真正打通。