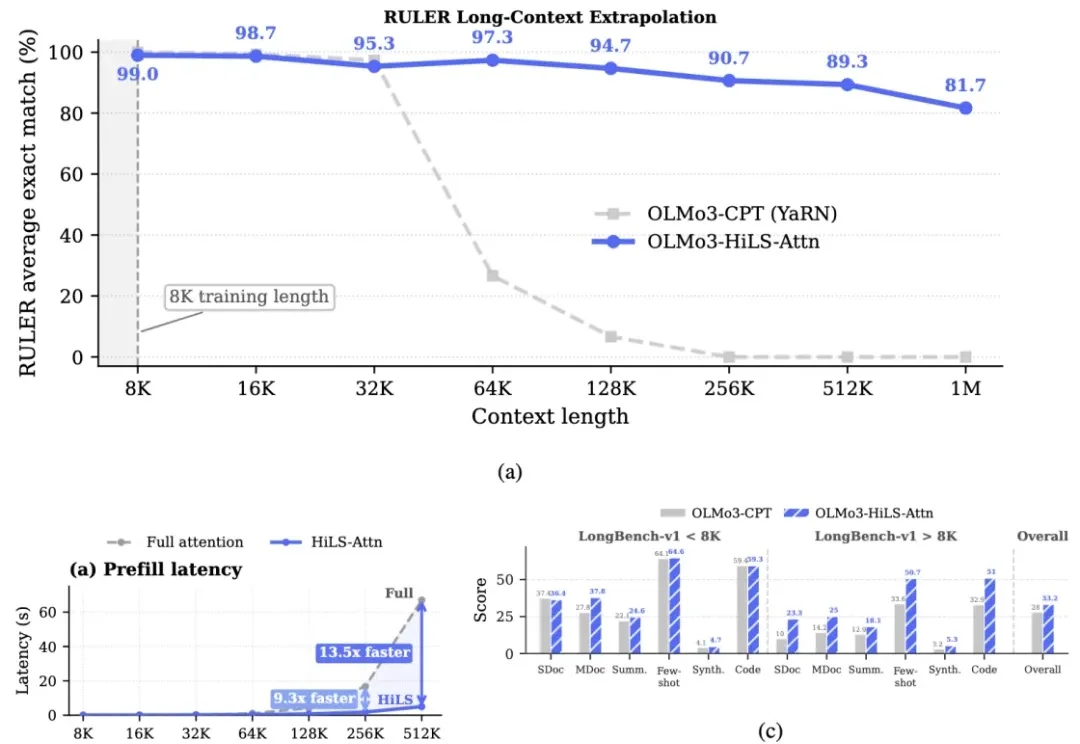
在数学上把稀疏注意力做对!腾讯Hy开源HiLS-Attention: 计算更少效果更好, 外推512倍
在数学上把稀疏注意力做对!腾讯Hy开源HiLS-Attention: 计算更少效果更好, 外推512倍让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。
来自主题: AI技术研报
9116 点击 2026-07-20 15:19
 搜索
搜索
让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。

市面上已有几十种Agent记忆方案,有的基于向量检索,有的基于知识图谱,有的靠定期总结“压缩”对话,有的则完全依赖模型自身的上下文窗口。它们各有各的说法,但在系统层面,到底哪种方案靠得住?哪种方案在你的工作负载下既不贵又准?

Kimi K3 是一个 2.8 万亿参数模型,基于 KDA 混合线性注意力机制(Kimi Delta Attention)和注意力残差(Attention Residuals)技术构建,原生支持视觉理解,并拥有 100 万 token 上下文窗口。它是全球首个开源的 3 万亿级别模型,面向长程编程、知识工作和推理等前沿智能场景而设计。

7 月 16 日,月之暗面正式发布 Kimi K3:总参数量 2.8 万亿(2.8T),原生视觉理解,100 万 token 上下文,并且——开源权重。这是历史上第一个摸到 2.8 万亿参数量级的开源模型。前任"开源最大模型"的纪录保持者?也是它自己。
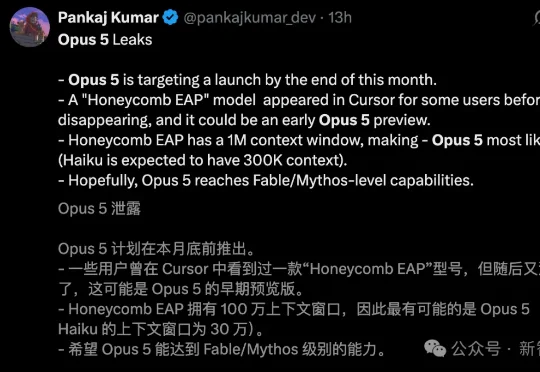
Opus 5可能要来了!有开发者意外发现,一款名为Honeycomb EAP神秘模型,1M上下文,代号「蜂巢」,在「模型列表」中短暂现身。大家一致推测,这就是Opus 5「早期预览版」,可能在月底上线。

为了打破多镜头长视频面临的高延迟、零交互困境,香港中文大学与快手可灵团队联合提出了首个实时流式多镜头长视频生成框架 ——ShotStream。该研究打破了传统双向架构的限制,将多镜头合成定义为基于历史上下文的下一镜头生成任务,用户可以通过动态流式提示词在运行时动态指导叙事走向!更令人振奋的是
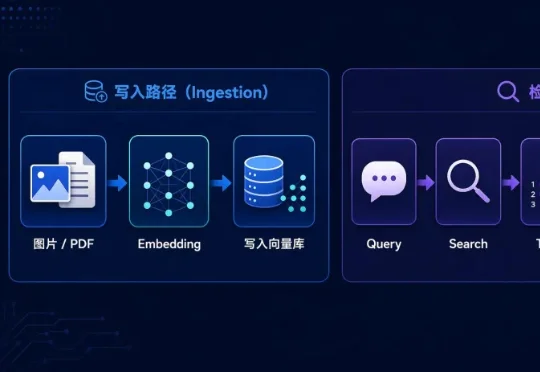
多模态 Agent 的记忆系统,过去很容易被理解成一个升级版 RAG:图片、图表、PDF 进来之后,先抽取内容、做 embedding、写进向量库;用户提问时,再用 query 做检索,把命中的top-k图片、文档页或图表一并塞进上下文,再交给多模态模型回答。整个过程中,所有原始模态信息都会不加选择的塞给大模型。
我天天在ai news radar里刷呀刷,真刷出了个新的开源项目,Tutti。光看Readme的时候,我以为它又是一套给Agent套GUI的桌面壳,实际上它提供了一个实时共享的工作空间,我所有agent可以共享上下文,文件,应用和任务。
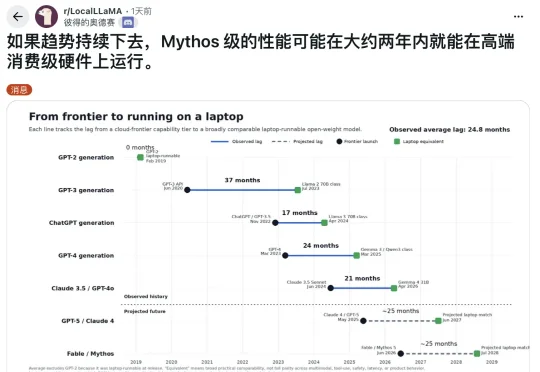
曾经人们讨论前沿模型时,话题通常是「它有多强」「它比竞品快多少」「它能取代什么工作」。但这一次,有人开始问它能不能跑在端侧。不过说实话,这个想法目前放在 Fable 5 身上,还是太乐观了,这毕竟是 Anthropic 第一个 Mythos 级的公开模型,100 万 token 上下文窗口,专为长时间异步任务设计

据 The Information 报道,MiniMax 正在研发一款参数规模达 2.7 万亿的大语言模型,内部代号暂定为 M3 Pro,最快有望于今年第三季度发布,并计划同步开源。相较于现有旗舰模型 M3 的 4280 亿参数,M3 Pro 的规模实现了数量级跃升,预计将在复杂推理、多步骤任务处理及长上下文理解等能力上进一步增强。