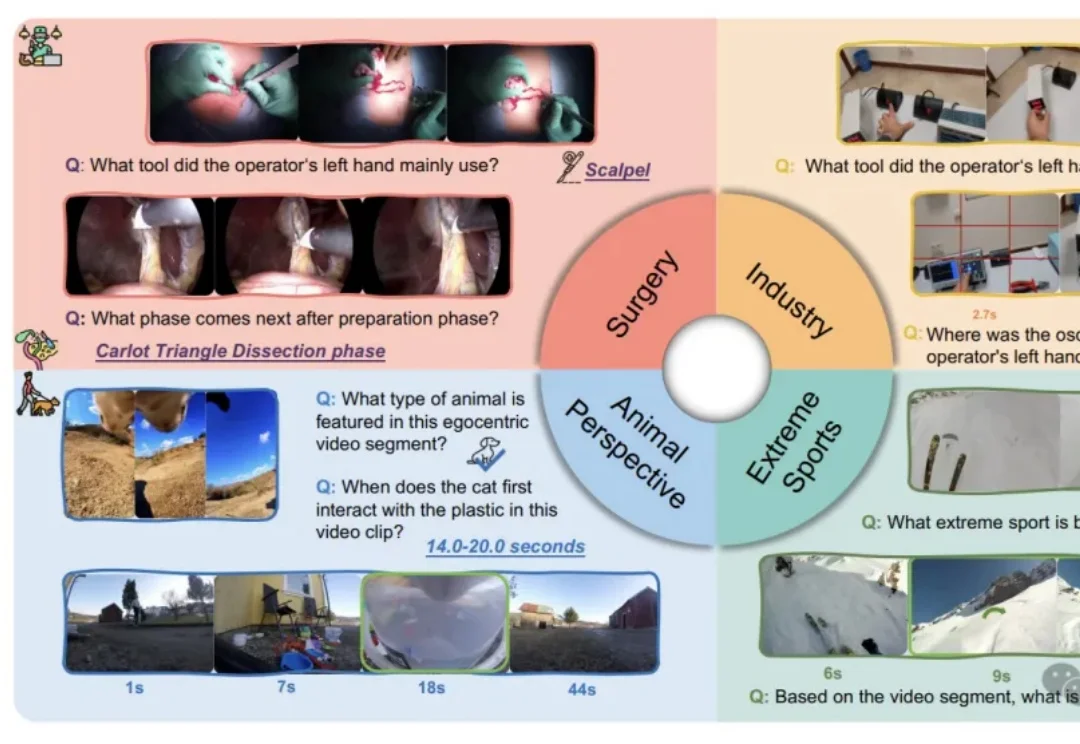
准确率腰斩!大模型视觉能力一出日常生活就「失灵」
准确率腰斩!大模型视觉能力一出日常生活就「失灵」我们习惯了AI在屏幕上侃侃而谈、生成美图,好像它无所不知。但假如把它“扔”进一个真实的手术室,让它用主刀医生的第一视角来判断下一步该用哪把钳子,这位“学霸”很可能当场懵圈。
来自主题: AI技术研报
9735 点击 2025-12-09 10:37
 搜索
搜索
我们习惯了AI在屏幕上侃侃而谈、生成美图,好像它无所不知。但假如把它“扔”进一个真实的手术室,让它用主刀医生的第一视角来判断下一步该用哪把钳子,这位“学霸”很可能当场懵圈。
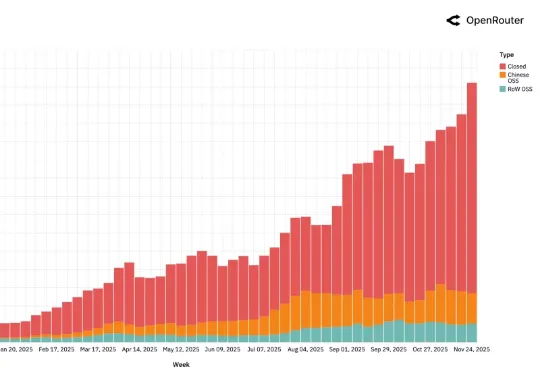
AI 领域迄今最大规模的用户行为实录,刚刚发布了。这是全球模型聚合平台 OpenRouter 联合硅谷顶级风投 a16z 发布的一份报告,基于全球 100 万亿次真实 API 调用、覆盖 300+款 AI 模型、60+家供应商、超过 50% 非美国用户 。
今日,美团正式发布并开源图像生成模型LongCat-Image,这是一款在图像编辑能力上达到开源SOTA水准的6B参数模型,重点瞄准文生图与单图编辑两大核心场景。在实际体验中,它在连续改图、风格变化和材质细节上表现较好,但在复杂排版场景下,中文文字渲染仍存在不稳定的情况。
上周,“豆包手机助手”一跃成为AI圈与手机圈的年度热点,热度与争议齐飞。我们抢在首批样机售罄前,自费3499元入手了一台搭载豆包手机助手的努比亚M153工程机,进行了3天的沉浸式体验,对这其中的争议和真实使用体验有了更深的感受。

在AI的浪潮下,学术研究正在被商业机构加速「量产化」,包装成明码标价的「入学筹码」。这不仅稀释了学术研究的含金量,挤占了学术资源,也可能导致学术通胀、学历贬值与更深层的信任危机。

最近,Google Research 发布了一篇 Blog《Titans + MIRAS:帮助人工智能拥有长期记忆》。它们允许 AI 模型在运行过程中更新其核心内存,从而更快地工作并处理海量上下文。

12 月 1 日,DeepSeek 一口气发布了两款新模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。几天过去,热度依旧不减,解读其技术报告的博客也正在不断涌现。知名 AI 研究者和博主 Sebastian Raschka 发布这篇深度博客尤其值得一读,其详细梳理了 DeepSeek V3 到 V3.2 的进化历程。

这个年末,存储行业过得不是很太平:AI巨头们不计成本地囤货,让存储行业迎来了一轮史诗级涨价。作为涨价潮的起点,内存(DRAM)与固态硬盘(SSD,核心为NAND闪存)的价格涨幅堪称惊人。相较于一年多前的市场低谷,如今大家要购买同款内存产品,价格已飙升至此前的三四倍。
如今,强化学习(RL)已成为提升大语言模型(LLM)复杂推理与解题能力的关键技术范式,而稳定的训练过程对于成功扩展 RL 至关重要。由于语言具有强烈的上下文属性,LLM 的 RL 通常依赖序列级奖励 —— 即根据完整生成序列给一个标量分数。

谷歌DeepMind掌门人断言,2030年AGI必至!不过,在此之前,还差1-2个「Transformer级」核爆突破。恰在NeurIPS大会上,谷歌甩出下一代Transformer最强继任者——Titans架构。