英伟达全模态大模型 Nemotron 3 Nano Omni 来了,几秒搞定老黄3分钟演讲,吞吐量同类9倍
英伟达全模态大模型 Nemotron 3 Nano Omni 来了,几秒搞定老黄3分钟演讲,吞吐量同类9倍英伟达于昨日正式推出全新多模态推理模型Nemotron 3 Nano Omni,将文本、视觉、语音三大模态能力深度融合至单一模型体系,目前可免费使用。
来自主题: AI资讯
9371 点击 2026-04-29 19:52
 搜索
搜索
英伟达于昨日正式推出全新多模态推理模型Nemotron 3 Nano Omni,将文本、视觉、语音三大模态能力深度融合至单一模型体系,目前可免费使用。

你有没有想过,不用联网、仅用一张消费级显卡,就能在个人电脑上拥有一个「边看、边听、边说、还能主动提醒」的类人 AI 助手?这就是 MiniCPM-o 4.5 所能做到的。在技术创新下,它仅凭 9B 参数,实现了业界首个端到端全双工全模态大模型,让端侧 AI 普惠成为现实。其自 2026 年 2 月模型发布以来,在 Hugging Face 上的下载量已突破 25 万+。

林俊旸离职了,但 Qwen 不能停。最近 Qwen3.5-Omni 发布,一个原生全模态大模型,文本、图片、音频、视频的理解与生成,集于一身。 这不是第一个试图「什么都做」的模型。过去两年,多模态是所
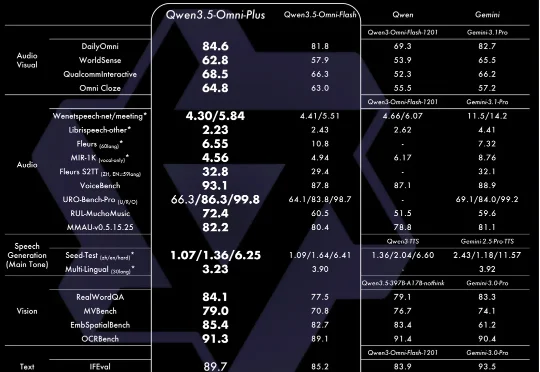
阿里刚刚发布了最新一代全模态大模型 Qwen3.5-Omni,在通用音频理解、推理、翻译和对话等维度,已全面超越 Gemini 3.1 Pro。所谓全模态,在于它拥有了接近人类的“感官”。它能听、能看、能说、能写。
这个国产开源模型,把多模态玩出了“魔法”感。
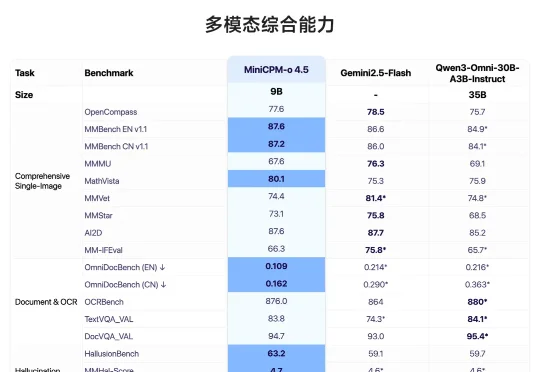
面壁开源了行业首个全双工全模态大模型 MiniCPM-o 4.5,相比已有多模态模型,MiniCPM-o 4.5 首次实现了「边看边听边说」以及「自主交互」的全模态能力,模型不再只是把视觉、语音作为静态输入处理,而是能够在实时、多模态信息流中持续感知环境变化,并在输出的同时保持对外界的理解。

针对端到端全模态大模型(OmniLLMs)在跨模态对齐和细粒度理解上的痛点,浙江大学、西湖大学、蚂蚁集团联合提出 OmniAgent。这是一种基于「音频引导」的主动感知 Agent,通过「思考 - 行动 - 观察 - 反思」闭环,实现了从被动响应到主动探询的范式转变。
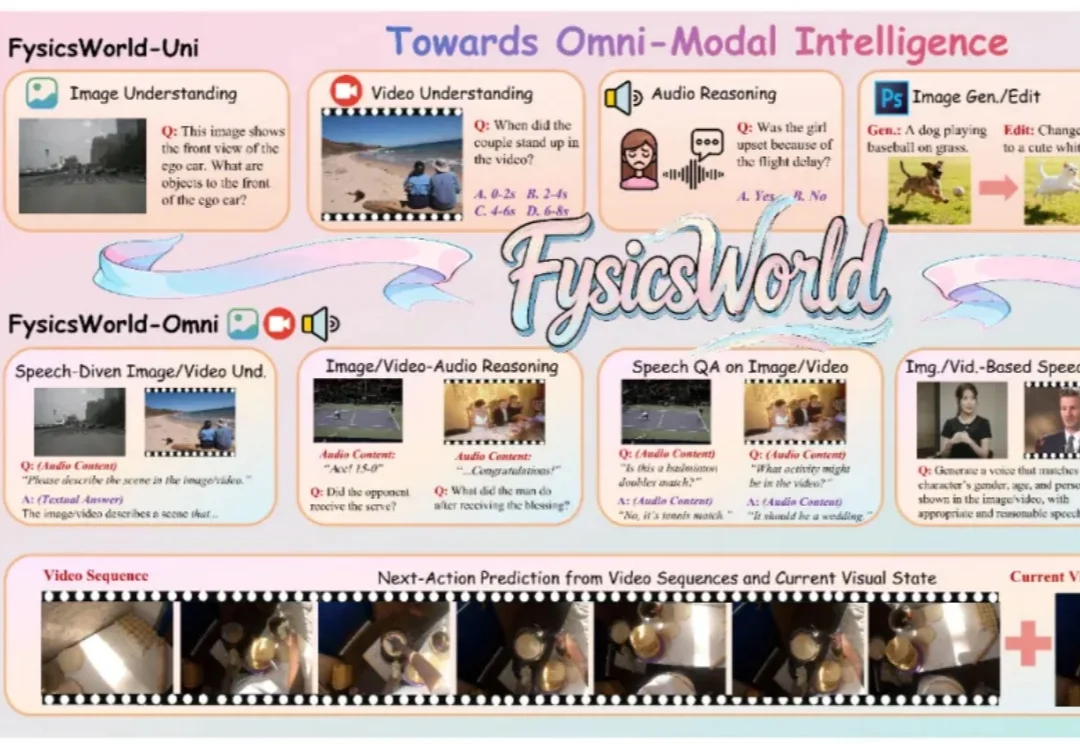
近年来,多模态大语言模型正在经历一场快速的范式转变,新兴研究聚焦于构建能够联合处理和生成跨语言、视觉、音频以及其他潜在感官模态信息的统一全模态大模型。此类模型的目标不仅是感知全模态内容,还要将视觉理解和生成整合到统一架构中,从而实现模态间的协同交互。
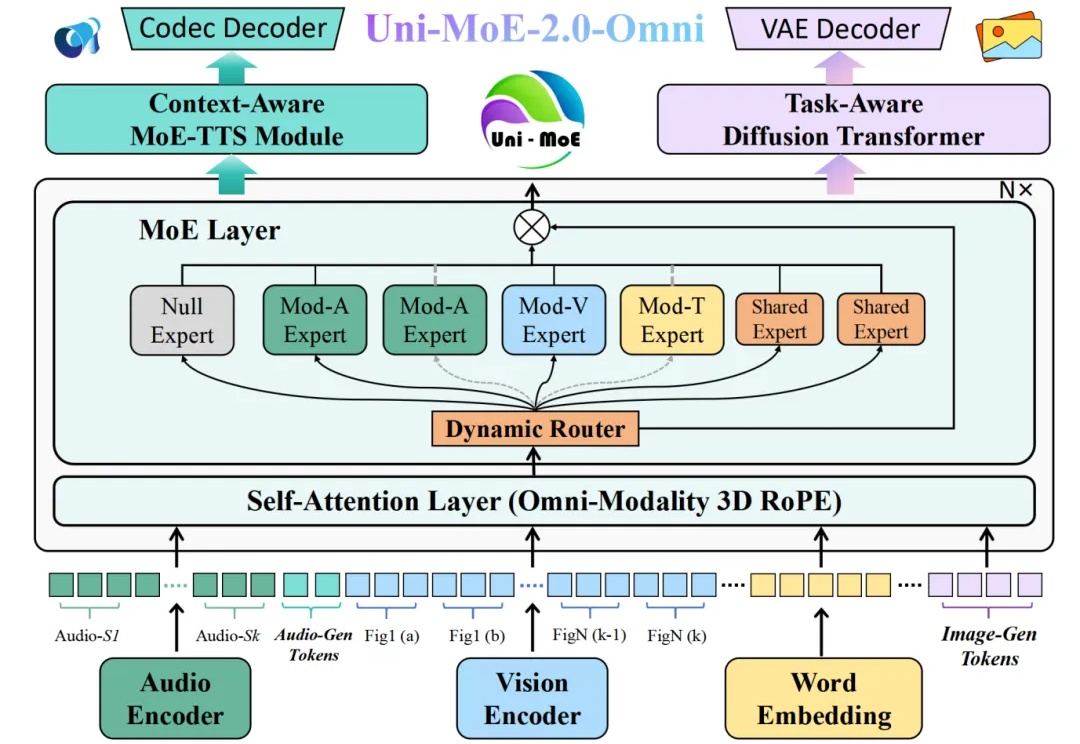
全模态大模型(Omnimodal Large Models, OLMs)能够理解、生成、处理并关联真实世界多种数据类型,从而实现更丰富的理解以及与复杂世界的深度交互。人工智能向全模态大模型的演进,标志着其从「专才」走向「通才」,从「工具」走向「伙伴」的关键点。
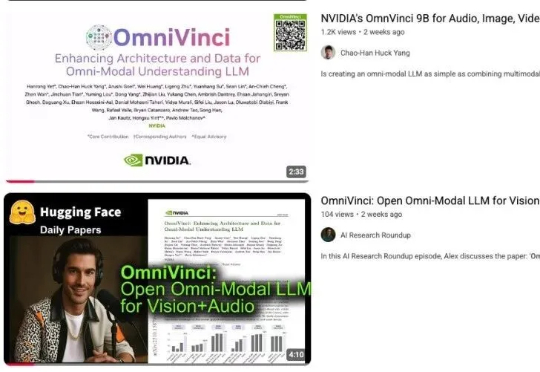
OmniVinci是英伟达推出的全模态大模型,能精准解析视频和音频,尤其擅长视觉和听觉信号的时序对齐。它以90亿参数规模,性能超越同级别甚至更高级别模型,训练数据效率是对手的6倍,大幅降低成本。在视频内容理解、语音转录、机器人导航等场景中,OmniVinci能提供高效支持,展现出卓越的多模态应用能力。