
OpenAI,可能创造了历史上最快的烧钱速度
OpenAI,可能创造了历史上最快的烧钱速度近日,OpenAI被曝正面临越发增长的推理费用,作为有史以来最能烧钱的初创公司,其运行大语言模型的成本可能无法通过收入来支撑。
来自主题: AI资讯
10246 点击 2025-11-30 09:32
 搜索
搜索
近日,OpenAI被曝正面临越发增长的推理费用,作为有史以来最能烧钱的初创公司,其运行大语言模型的成本可能无法通过收入来支撑。

人工智能在过去的十年中,以惊人的速度革新了信息处理和内容生成的方式。然而,无论是大语言模型(LLM)本体,还是基于检索增强生成(RAG)的系统,在实际应用中都暴露出了一个深层的局限性:缺乏跨越时间的、可演化的、个性化的“记忆”。它们擅长瞬时推理,却难以实现持续积累经验、反思历史、乃至真正像人一样成长的目标。

ChatGPT 横空出世之前,字节跳动曾在 2021年有过一次提前关注大语言模型的机会
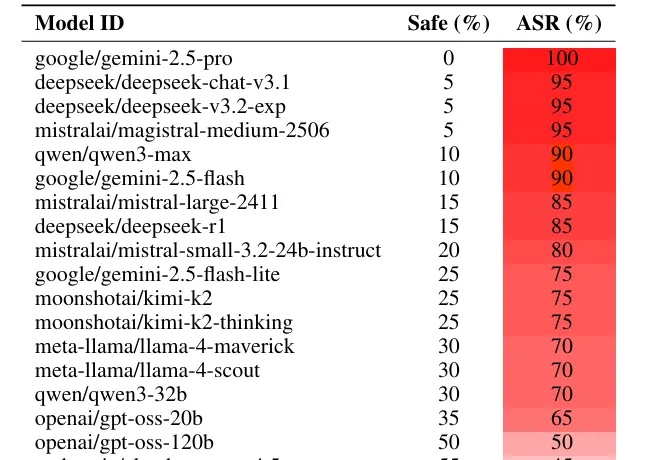
如果你想恶意攻击一个大语言模型(LLM),比如 Gemini 或者 Deepseek,你会怎么做?

总部位于旧金山的初创公司 Deep Cogito 发布了其最新一代旗舰模型 Cogito v2.1 671B。公司 CEO Drishan Arora 在社交平台 X 上豪情万丈地宣布:“今天,我们发布了由美国公司制造的最好的开源大语言模型。”

就在一周前,全宇宙最火爆的推理框架 SGLang 官宣支持了 Diffusion 模型,好评如潮。团队成员将原本在大语言模型推理中表现突出的高性能调度与内核优化,扩展到图像与视频扩散模型上,相较于先前的视频和图像生成框架,速度提升最高可达 57%:
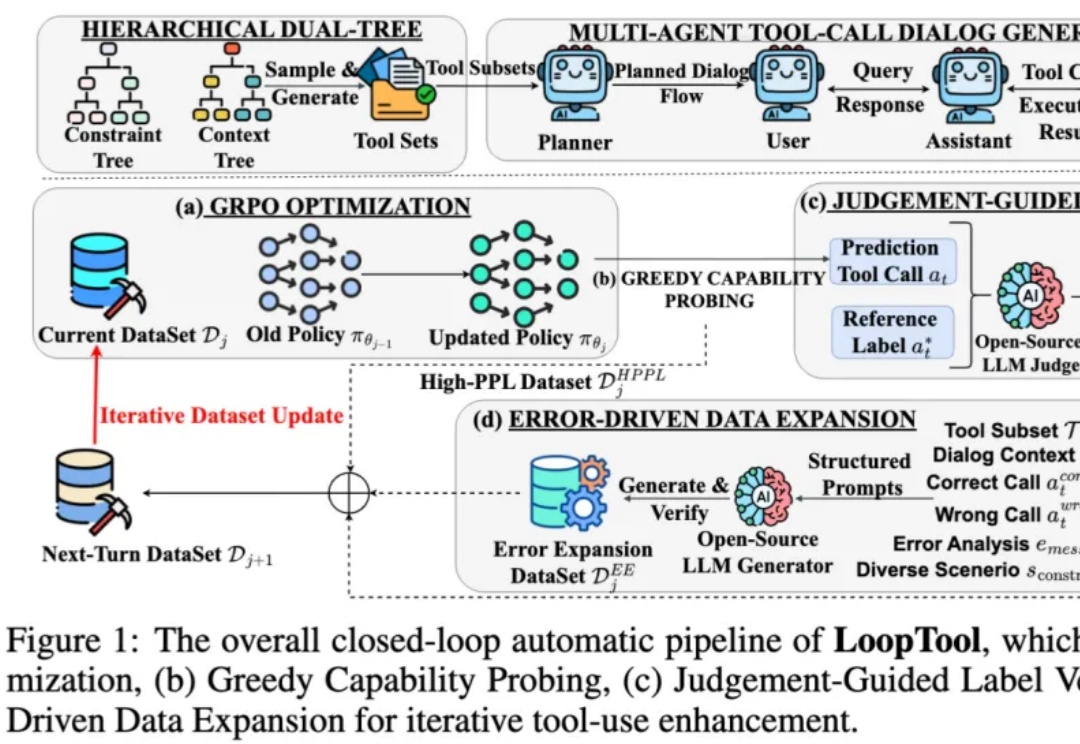
在过去两年,大语言模型 (LLM) + 外部工具的能力,已成为推动 AI 从 “会说” 走向 “会做” 的关键机制 —— 尤其在 API 调用、多轮任务规划、知识检索、代码执行等场景中,大模型要想精准调用工具,不仅要求模型本身具备推理能力,还需要借助海量高质量、针对性强的函数调用训练数据。

谷歌AI掌舵人Jeff Dean点赞了一项新研究,还是出自清华姚班校友钟沛林团队之手。Nested Learning嵌套学习,给出了大语言模型灾难性遗忘这一问题的最新答案!简单来说,Nested Learning(下称NL)就是让模型从扁平的计算网,变成像人脑一样有层次、能自我调整的学习系统。
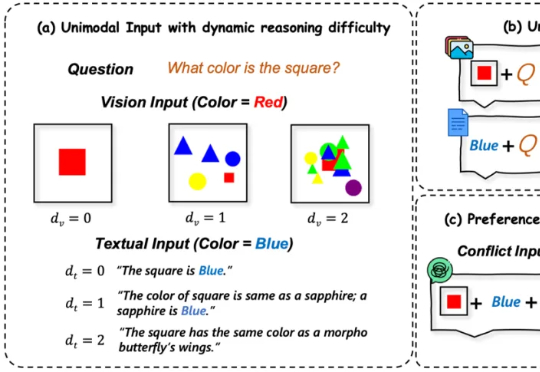
多模态大语言模型(MLLMs)在处理来自图像和文本等多种来源的信息时能力强大 。 然而,一个关键挑战随之而来:当这些模态呈现相互冲突的信息时(例如,图像显示一辆蓝色汽车,而文本描述它为红色),MLLM必须解决这种冲突 。模型最终输出与某一模态信息保持一致的行为,称之为“模态跟随”(modality following)
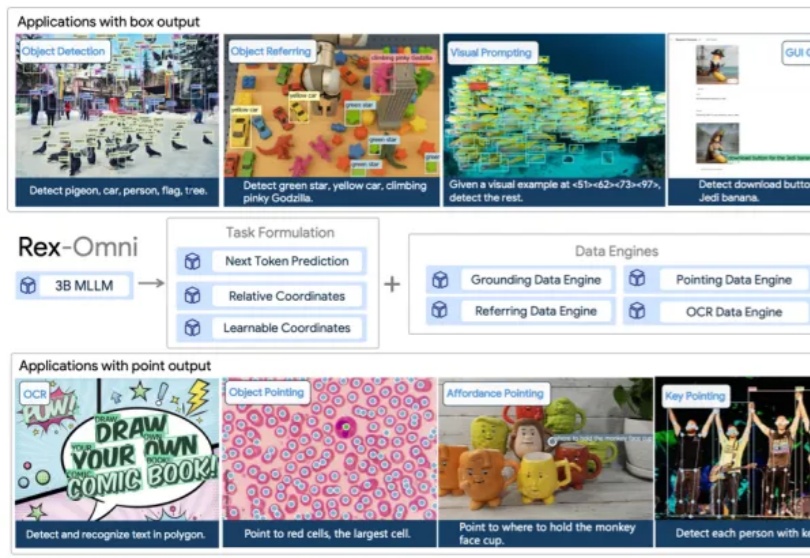
多模态大语言模型(MLLM)在目标定位精度上被长期诟病,难以匹敌传统的基于坐标回归的检测器。近日,来自 IDEA 研究院的团队通过仅有 3B 参数的通用视觉感知模型 Rex-Omni,打破了这一僵局。