字节Seedance 2.0发论文了,171人署名,吴永辉曾妍在列
字节Seedance 2.0发论文了,171人署名,吴永辉曾妍在列现象级AI视频技术、字节Seedance 2.0在arXiv发论文了。晒了26页的Benchmark,和贡献者名单。170位团队成员全公开,署名和尊重都拉满了,不过嘛这就不怕……嘛?
来自主题: AI资讯
8384 点击 2026-04-17 15:18
 搜索
搜索
现象级AI视频技术、字节Seedance 2.0在arXiv发论文了。晒了26页的Benchmark,和贡献者名单。170位团队成员全公开,署名和尊重都拉满了,不过嘛这就不怕……嘛?

Claude最强“神话”模型,可能用到来自字节的技术?

字节Seed最新研究,让大模型能“原地改参数”了。既不用改模型结构,也不用重新训练,还跑得很快。具体是这么个情况。智能体时代嘛,大家都知道模型们面对的任务开始变得越来越复杂、上下文越来越长。

HappyHorse身份曝光,或将明天上线?

第一篇论文来自字节SEED团队, 打了一些基础; 《Over-Tokenized Transformer》。 论文标题看上去在讨论“过度分词”。 而重点必然是在第二篇上—— DeepSeek公司的学术成果Engram。 《Conditional Memory via Scalable Lookup》 也就是Engram模块所出处的论文。

据接近腾讯混元团队的知情人士透露,原字节Seed视觉AI平台团队负责人肖学锋,Infra团队张弛于近期低调入职腾讯,负责大模型Infra相关工作,向腾讯首席AI科学家姚顺雨汇报。

让AI自己写高性能GPU代码,字节Seed与清华AIR团队做到了。
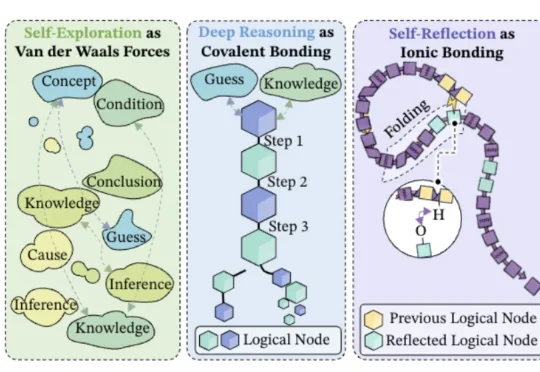
字节Seed都开始用化学思想搞大模型了——深度推理是共价键、自我反思是氢键、自我探索是范德华力?!
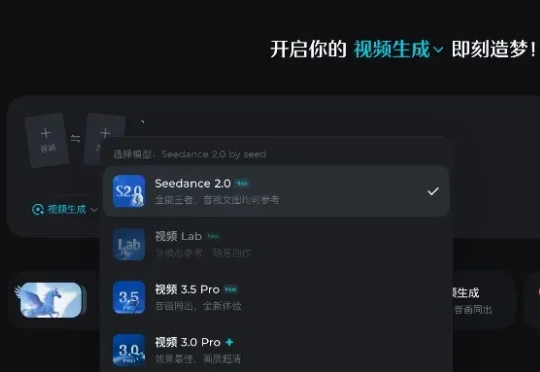
2月7日,字节跳动AI视频生成模型Seedance2.0开启灰度测试,该模型支持文本、图片、视频、音频素材输入,可以完成自分镜和自运镜,镜头移动后人物特征能够保持一致。

LLM的下一个推理单位,何必是Token?刚刚,字节Seed团队发布最新研究——DLCM(Dynamic Large Concept Models)将大模型的推理单位从token(词) 动态且自适应地推到了concept(概念)层级。