
我用Meta“华人天团”打造的新模型,一张图复刻了一个“豆包App”
我用Meta“华人天团”打造的新模型,一张图复刻了一个“豆包App”MSL交出首张答卷。
来自主题: AI资讯
7464 点击 2026-04-09 15:21
 搜索
搜索
MSL交出首张答卷。

AI交互的「机械感」消失了!今天,豆包甩出原生全双工语音大模型Seeduplex,不仅能边听边说,甚至能听懂你在思考时的「卡壳」,就算环境再吵也不怕,抗干扰能力直接拉满。
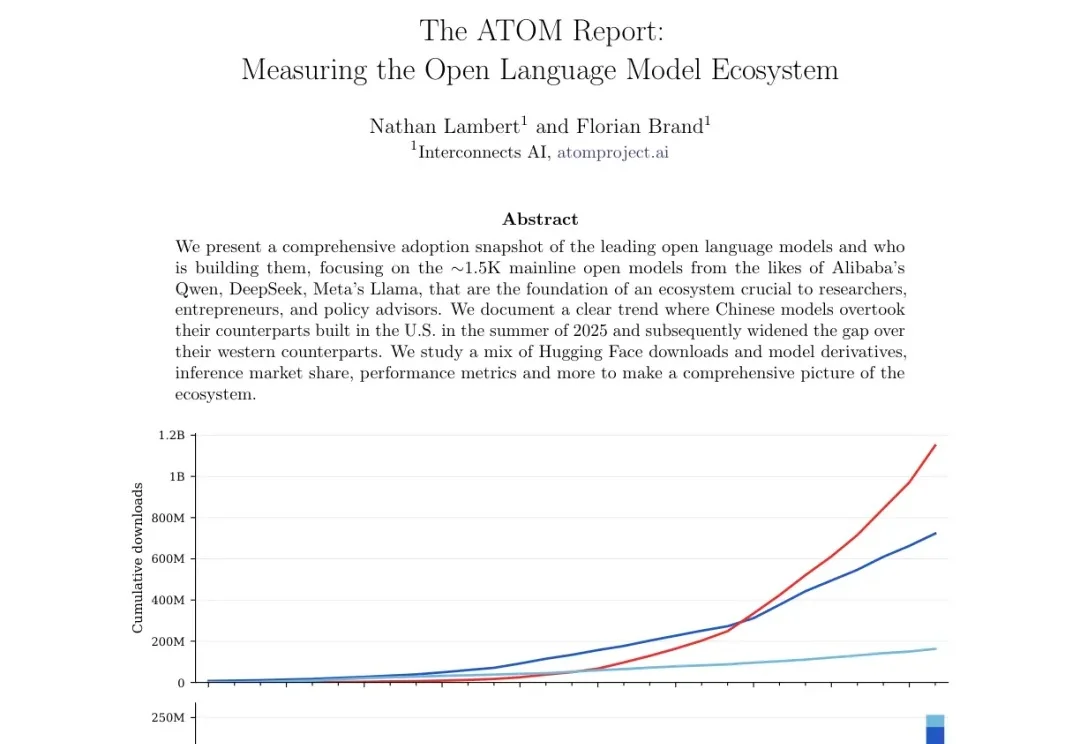
2026 年 4 月,Nathan Lambert 和 Florian Brand 发布了 The ATOM Report,一份关于开源语言模型生态的综合采纳度快照。这份报告追踪了约 1500 个主线开源模型的下载量、衍生模型、推理市场份额和性能数据,覆盖 2023 年 11 月到 2026 年 3 月
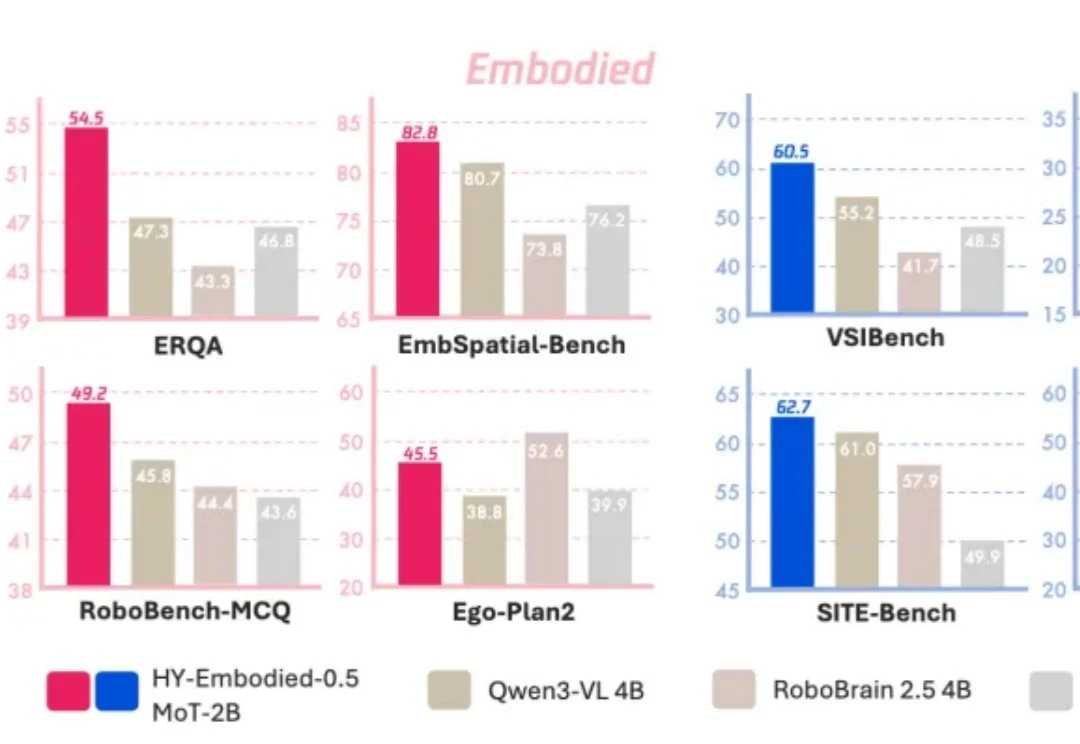
让大模型真正走进现实世界,是当下最迫切的需求之一。

RL之后,大模型为什么更容易「越训越单一」?面对五花八门的改进思路,也许答案并不复杂:先试着改一改KL项。

今天我们发布 MMX-CLI,一个面向 AI Agent 的命令行工具。接入 MMX-CLI 后,Agent 可以在 Claude Code、OpenClaw 等环境中原生调用 MiniMax 最新的编程、视频生成、语音合成、音乐创作等全模态模型,无需适配繁琐接口,也无需额外编写 MCP Server。

Generalist AI的GEN-1热度,仍在发酵。

黄仁勋用「五层蛋糕」讲清了AI全栈生态的分层逻辑,易鑫则把它翻译成汽车金融的落地打法:从算力、模型到Agent落地,解决的全是汽车金融最难的活。

被动成为新一代 AI 黄埔军校的字节跳动。

对本地部署玩家,尤其是Mac用户来说,长上下文推理最大的痛点往往不是“模型不够聪明”,而是稍微多用点上下文,统一内存就被撑爆了”,这一点在最近的Gemma-4 31B的部署中尤为明显,在同等上下文的情况,显存占用比Qwen3.5-27B高约一倍不止,直接劝退了不少人。但好消息是,谷歌近期提出的TurboQuant KV缓存量化算法,正是为了解决这个痛点而生。