上海交大DENG Lab提出「LatentUM」:Unified Model的真正「战场」在视觉推理与世界模型
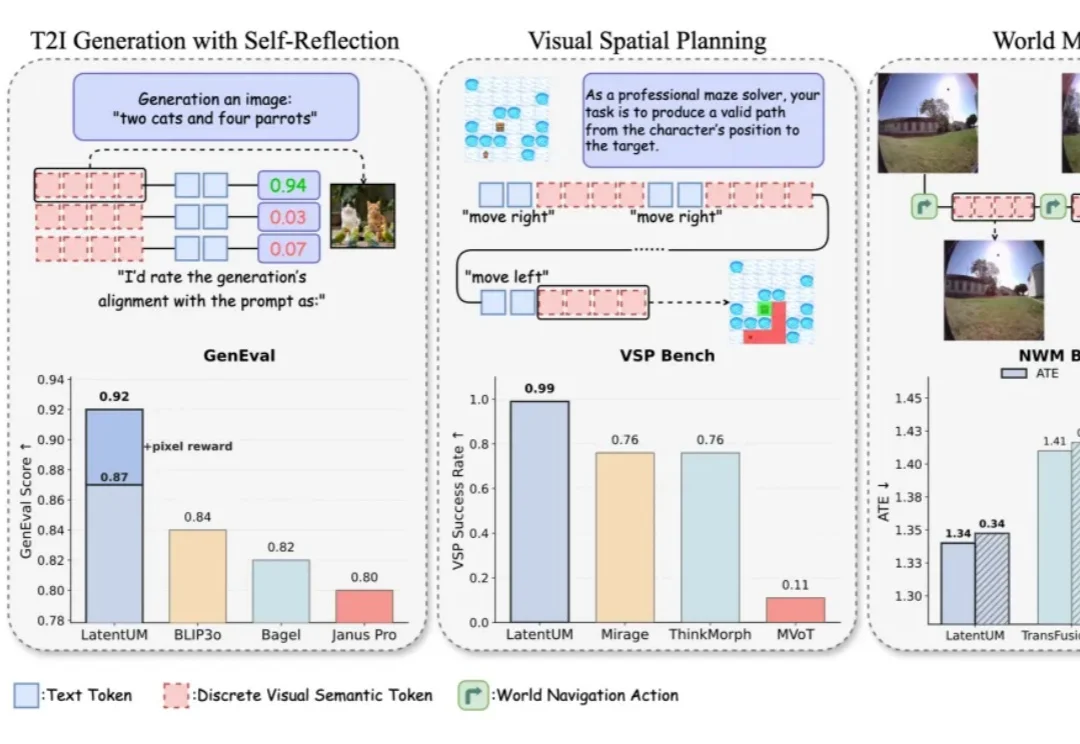
上海交大DENG Lab提出「LatentUM」:Unified Model的真正「战场」在视觉推理与世界模型过去一段时间,生成理解统一模型(Unified Model)经常被理解成一种「既能看懂图、又能生成图」的多模态通用系统。
来自主题: AI技术研报
8626 点击 2026-04-14 08:42
 搜索
搜索
过去一段时间,生成理解统一模型(Unified Model)经常被理解成一种「既能看懂图、又能生成图」的多模态通用系统。
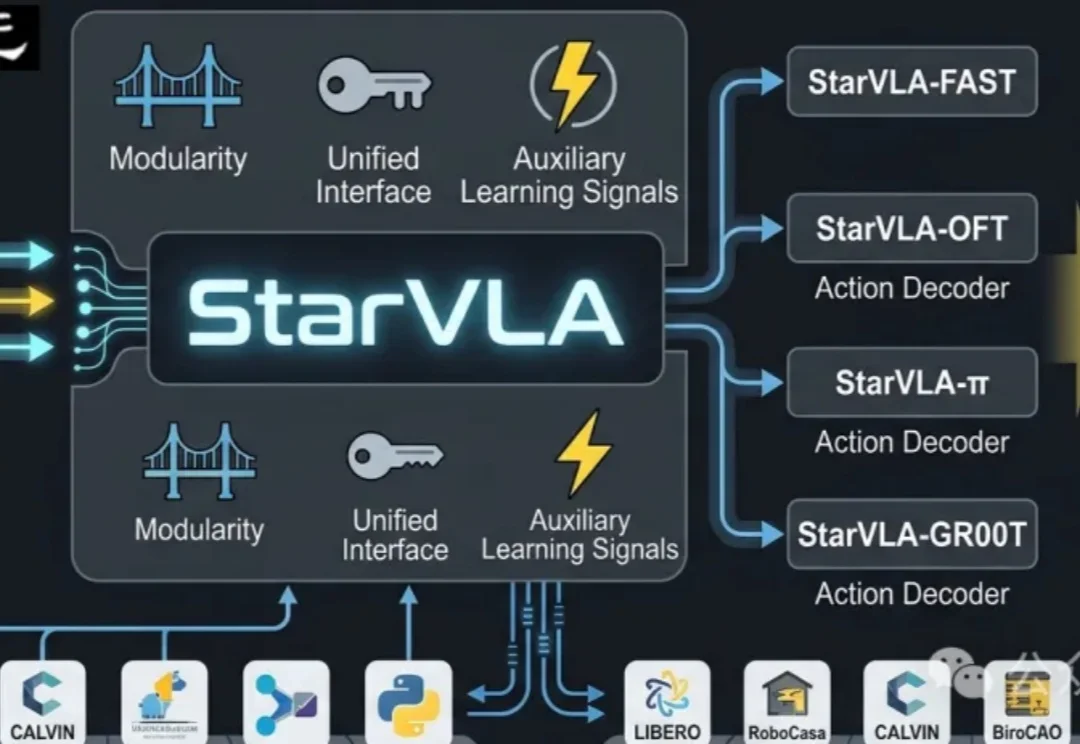
当前具身智能的VLA(Vision-Language-Action)赛道正陷入典型的「碎片化」泥潭:不同团队采用异构的动作解码范式、强耦合的数据管线、互不兼容的评测协议,导致方法难以横向对比,复现成本极高。
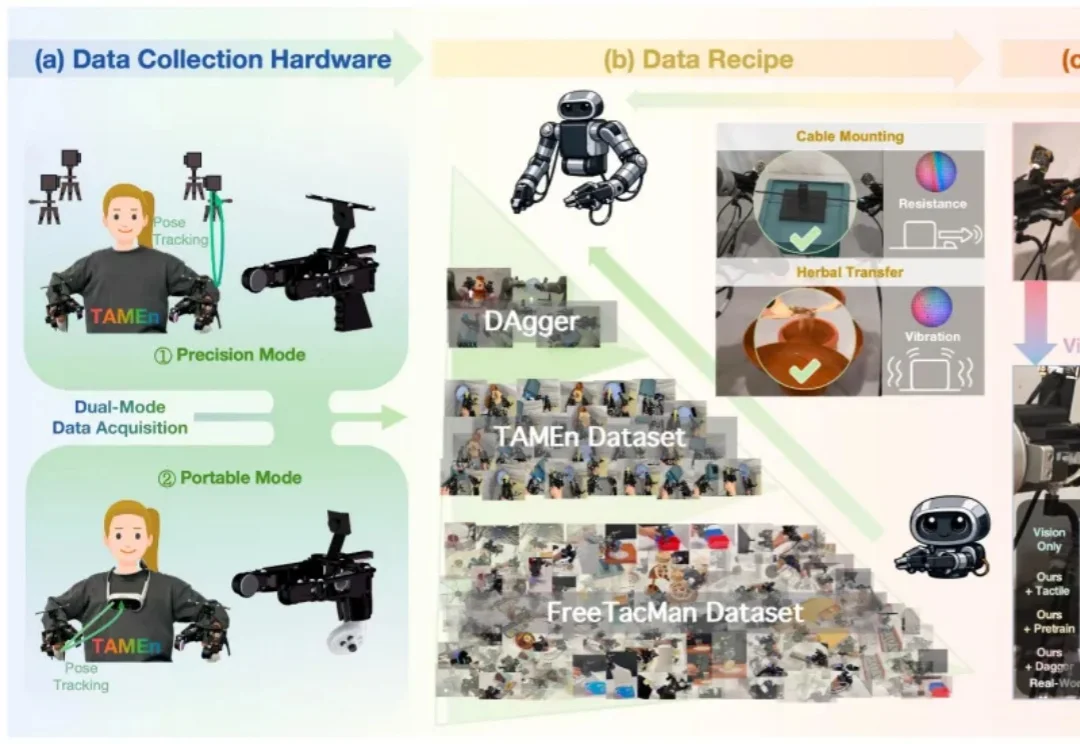
在具身智能快速发展的今天,高质量数据已成为驱动能力提升的关键基础,然而一个核心问题也随之而来: 如何让机器人数据采集更快、更稳、更有效?

让一个模型概括“这是一段什么视频”,并不难。

Claude最强“神话”模型,可能用到来自字节的技术?

过去一年,大模型的能力曲线几乎是指数上升的——推理更强、工具调用更稳、上下文窗口越撑越大。但一个越来越尖锐的问题也随之浮出水面:模型变强了,可承接它的那层东西在哪?

有没有想过让「龙虾」替你打麻将?
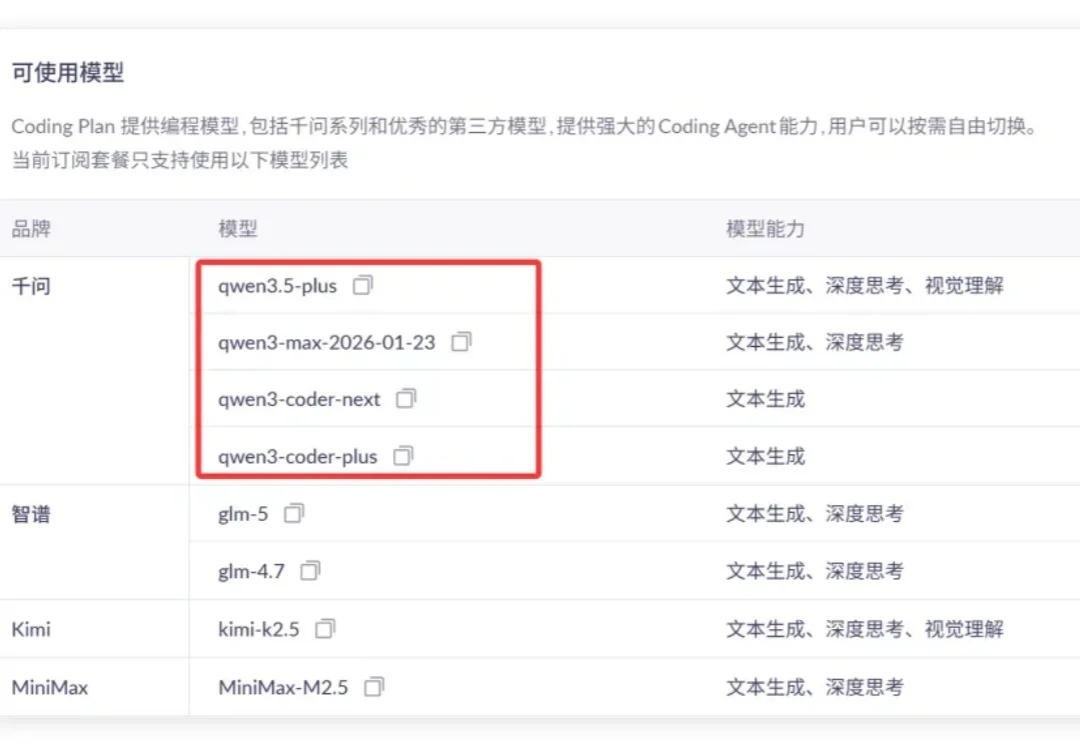
昨天我发现 Qwen3.6“倒反天罡”。
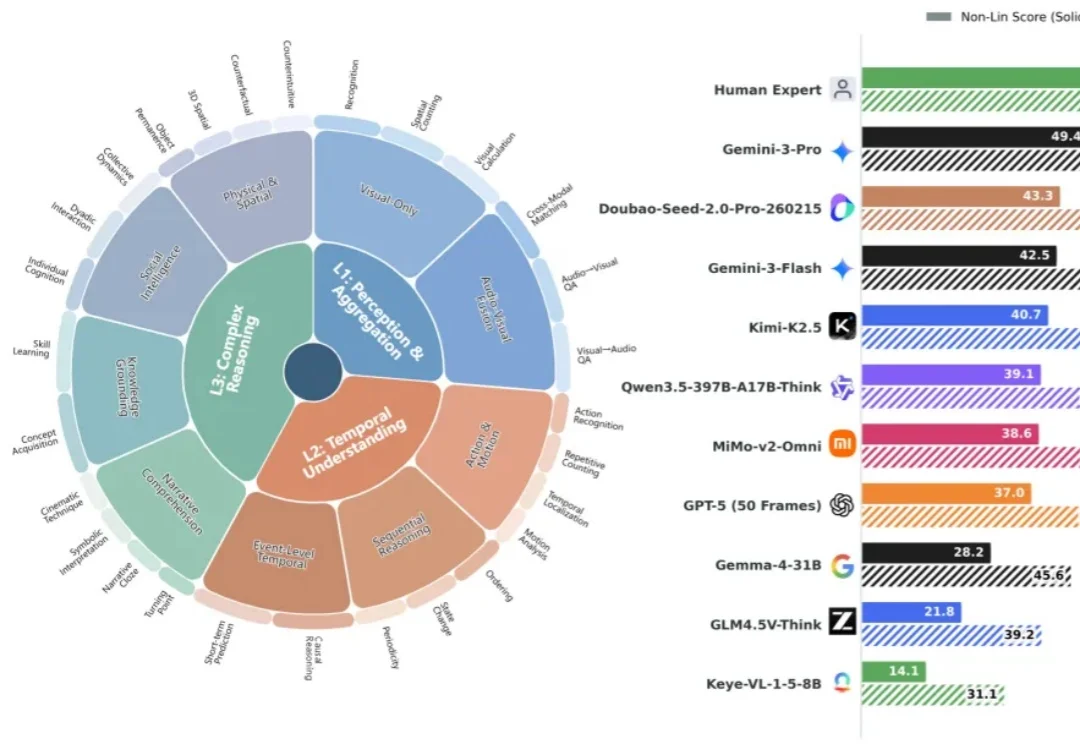
现有大模型评测分数日趋饱和,但与真实体验差距显著。南京大学傅朝友团队牵头,在 Google Gemini 评测团队邀约下推出视频理解新基准 Video-MME-v2。凭借创新的分层能力体系与组级非线性评分,以及 3300 + 人工时高质量标注,揭示模型与人类的巨大鸿沟(49 vs 90)、传统 Acc 指标虚高、以及 “Thinking” 并非总是增益等现象。

这个月,具身智能领域又卷出新高度:硅谷独角兽公司 Generalist AI 发布全新一代基础模型 GEN-1,将机器人包装手机、折纸箱这些活的平均成功率直接拉到了创纪录的 99%,折纸箱的速度更是飙到了以前的三倍(34s vs 12.1s)。