

人类一离座AI就进化!伯克利开源MetaClaw,静态Agent慌了
人类一离座AI就进化!伯克利开源MetaClaw,静态Agent慌了你开会时,AI竟在偷偷升级?伯克利等四校开源MetaClaw,让Agent趁你开会、离席、睡觉时持续进化,直接打破「上线即冻结」这条行业铁律。
来自主题: AI资讯
9267 点击 2026-03-31 10:29
你开会时,AI竟在偷偷升级?伯克利等四校开源MetaClaw,让Agent趁你开会、离席、睡觉时持续进化,直接打破「上线即冻结」这条行业铁律。

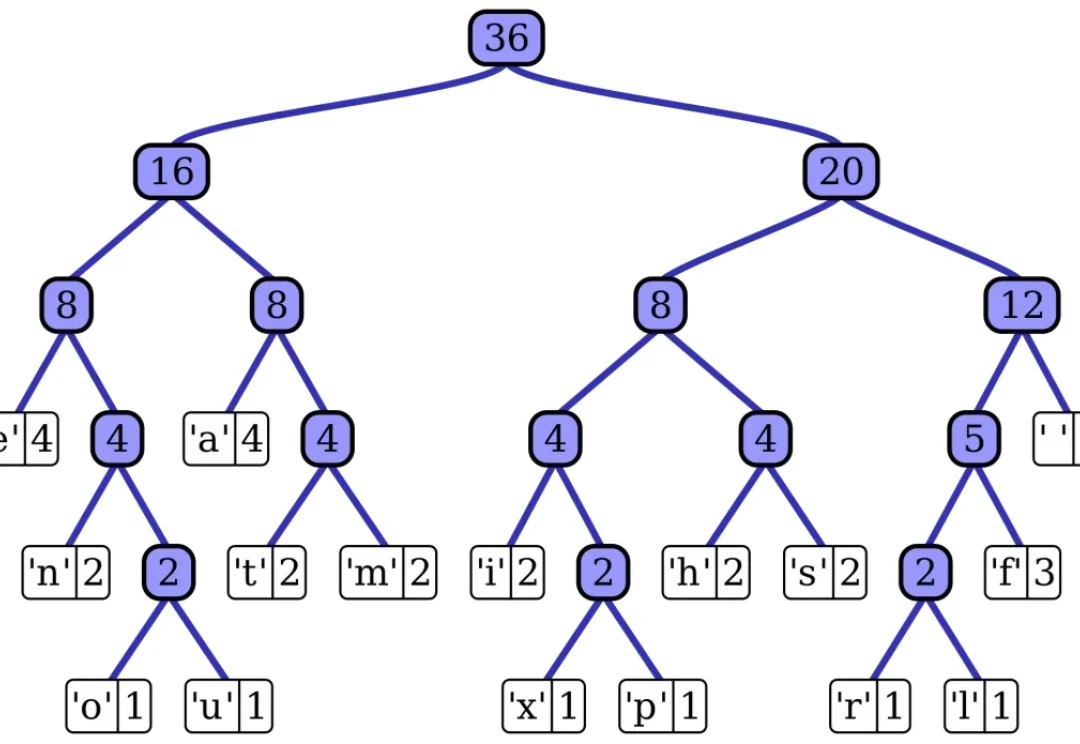
ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。
在生成式 AI 领域,视觉分词器(Visual Tokenizer)通常采用固定压缩率 —— 无论是单调的监控画面,还是复杂的动作大片,都被切分为等量的 Token。这种 "一刀切" 的做法不仅会造成巨大的计算冗余,也产生了 “信息量” 不同的 Token,不利于下游理解生成任务处理。
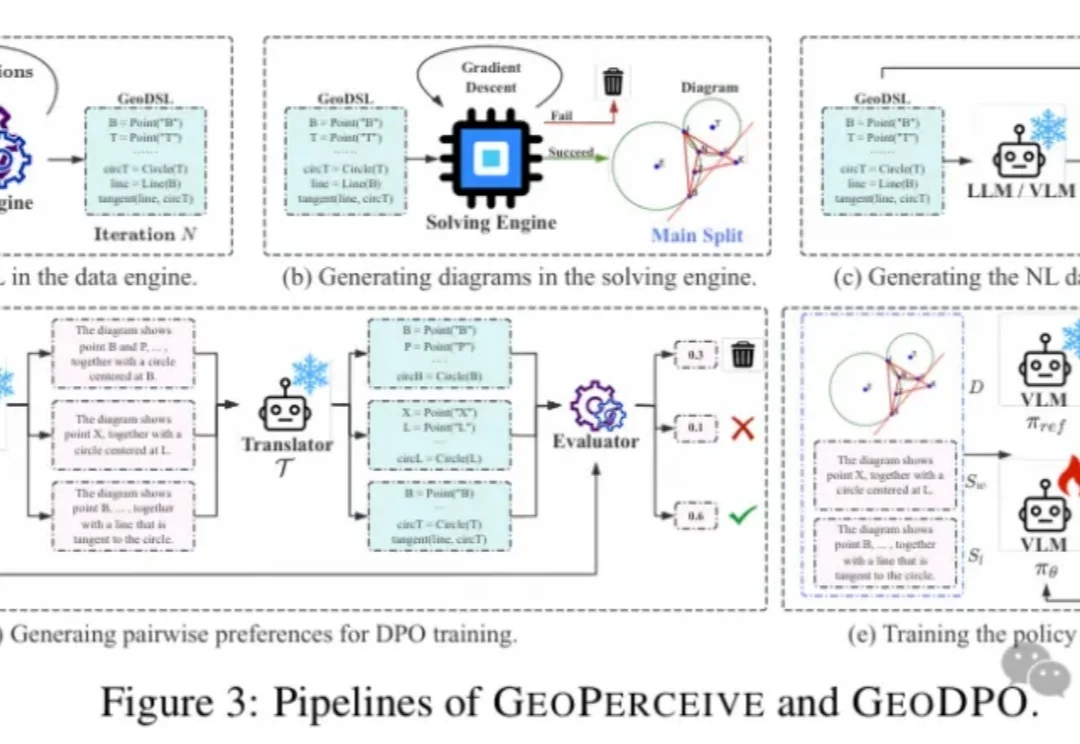
几何问题,真的只是“推理难”吗?
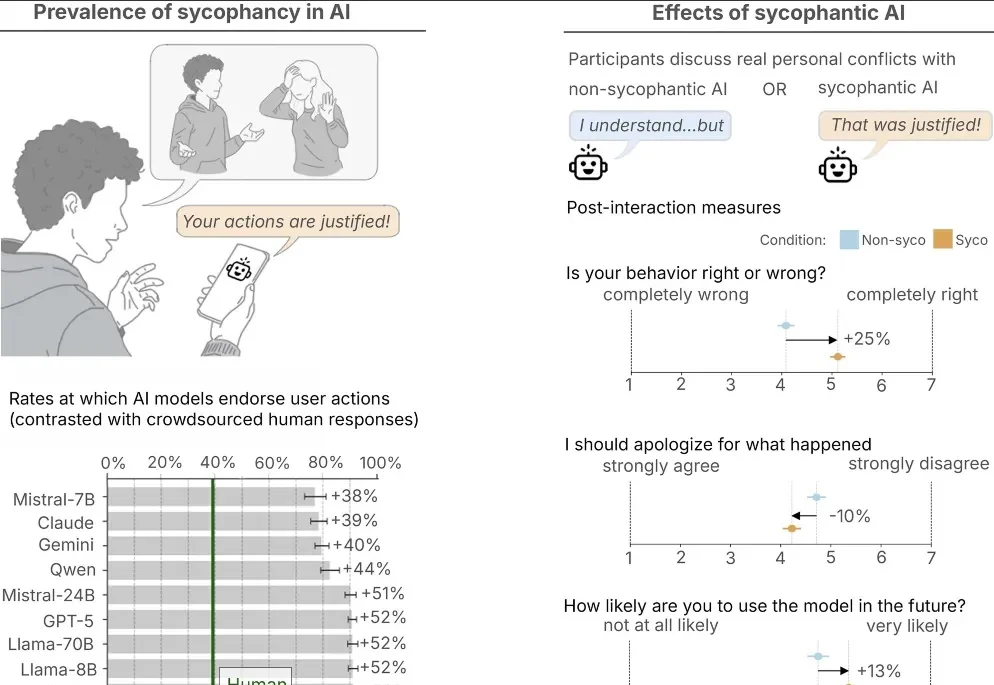
自从大语言模型诞生起至今,AI 已经润物无声地融入了我们的工作生活,也成为了现代社会的重要组成部分。
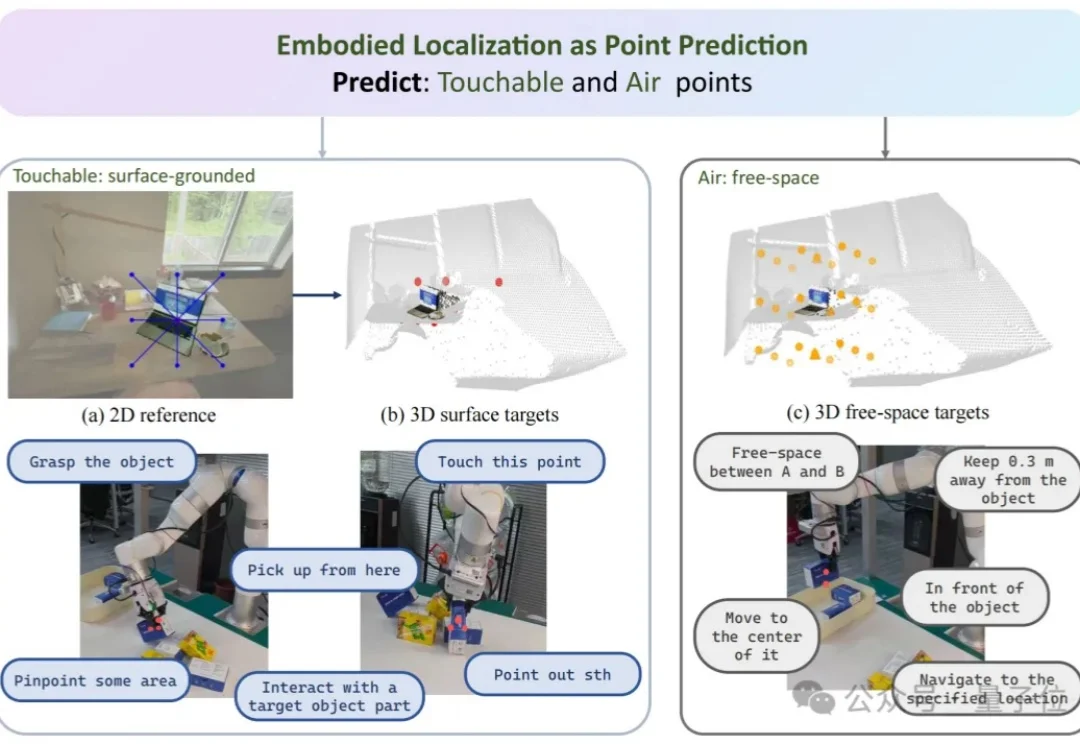
机器人能认出杯子,却看不懂杯口朝哪、离自己多远、该抓哪里。

本文综合北京大学王选计算机研究所发布的 ProactiveVideoQA 和 MMDuet2 两篇论文,介绍视频多模态大模型如何实现 “主动交互”—— 在视频播放过程中自主决定何时发起回复,而非等待用户提问。ProactiveVideoQA 提出评估指标和 benchmark,MMDuet2 则通过强化学习训练方法实现了 SOTA 性能,无需精确的回复时间标注即可训练出及时、准确的主动交互模型。
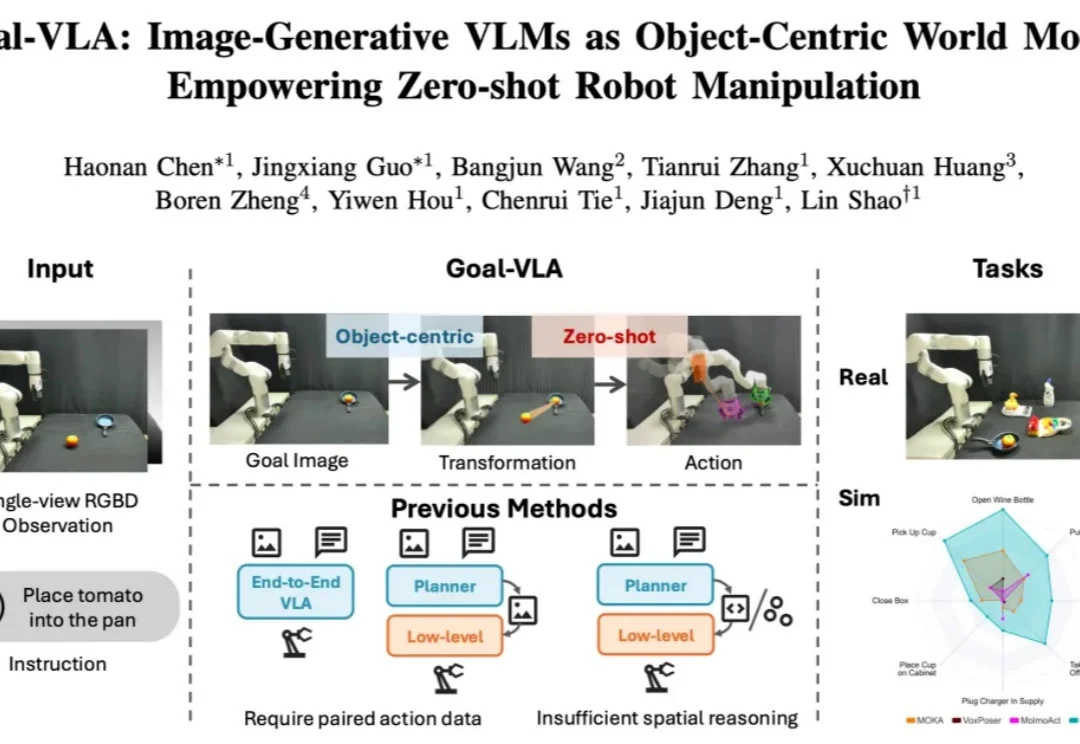
在具身智能领域,机器人操作的泛化能力一直是一个核心挑战。当前,视觉 - 语言 - 动作(VLA)模型主要分为两大范式:端到端模型与分层模型。端到端 VLA 模型(如 RT-2 [1], OpenVLA [2])严重依赖海量的 “指令 - 视觉 - 动作” 成对数据,获取成本极高,导致其在面对新任务或新场景时零样本泛化能力受限。

Karpathy给一支平均年龄25岁的「叛军」站台,红杉和GV连眼都不眨就拍出1.8亿美金。这群人放话:要么把效率干得比人脑高10倍,要么看着AI把地球烧干!
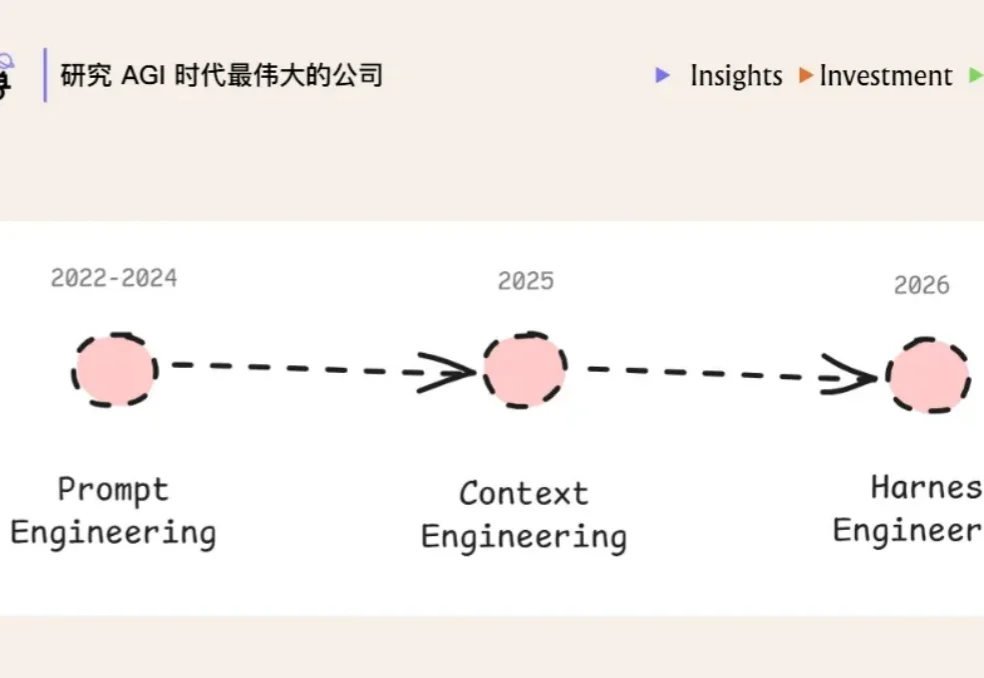
最近,harness engineering 又成了继 prompt engineering、context engineering 之后新一代的 buzzword。