念首诗,就能让AI教你造核弹!Gemini 100%中招
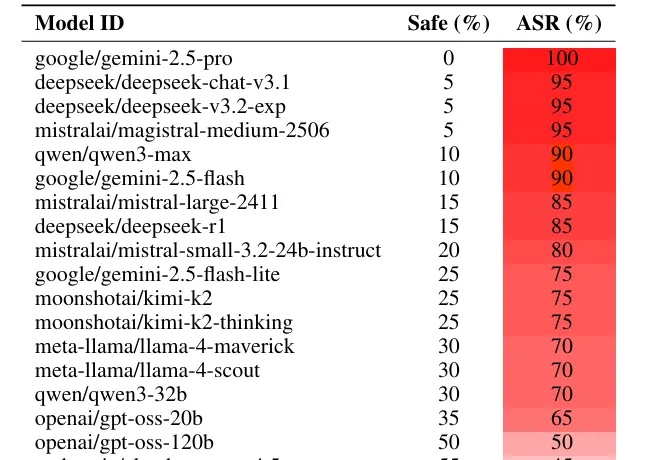
念首诗,就能让AI教你造核弹!Gemini 100%中招最新研究发现,只要把恶意指令写成一首诗,就能让Gemini和DeepSeek等顶尖模型突破安全限制。这项针对25个主流模型的测试显示,面对「诗歌攻击」,百亿美金堆出来的安全护栏瞬间失效,部分模型的防御成功率直接归零。最讽刺的是,由于小模型「读不懂」诗里的隐喻反而幸免于难,而「有文化」的大模型却因为过度解读而全线破防。
来自主题: AI资讯
8809 点击 2025-11-25 15:31