

Ilya罕见发声:大模型「大力出奇迹」到头了
Ilya罕见发声:大模型「大力出奇迹」到头了AI正从「规模时代」,重新走向「科研时代」。这是Ilya大神在最新采访中发表的观点。这一次,Ilya一顿输出近2万字,信息量爆炸,几乎把当下最热门的AI话题都聊了个遍:Ilya认为,目前主流的「预训练 + Scaling」路线已经明显遇到瓶颈。与其盲目上大规模,不如把注意力放回到「研究范式本身」的重构上。
来自主题: AI资讯
7602 点击 2025-11-26 14:38
AI正从「规模时代」,重新走向「科研时代」。这是Ilya大神在最新采访中发表的观点。这一次,Ilya一顿输出近2万字,信息量爆炸,几乎把当下最热门的AI话题都聊了个遍:Ilya认为,目前主流的「预训练 + Scaling」路线已经明显遇到瓶颈。与其盲目上大规模,不如把注意力放回到「研究范式本身」的重构上。

在AI视频创作过程中,创作者常因频繁切换多种工具而疲惫,导致创作热情消磨。近期,多所高校联合开源的UniVA框架,像一位「AI导演」,能整合多种视频工具,提供从脚本到成片的一站式自动化体验,改变传统「抽卡」式创作,支持多轮交互和主动纠错,还能实现风格迁移、前传创作等功能,为视频创作带来高效与便捷。

当大模型参数量冲向万亿级,GPT-4o、Llama4 等模型不断刷新性能上限时,AI 行业也正面临前所未有的瓶颈。Transformer 架构效率低、算力消耗惊人、与物理世界脱节等问题日益凸显,通用人工智能(AGI)的实现路径亟待突破。

当前,视频生成模型性能正在快速提升,尤其是基于Transformer架构的DiT模型,在视频生成领域的表现已经逐渐接近真实拍摄效果。然而,这些扩散模型也面临一个共同的瓶颈:推理时间长、算力成本高、生成速度难以提升。随着视频生成长度持续增加、分辨率不断提高,这个瓶颈正在成为影响视频创作体验的主要障碍之一。
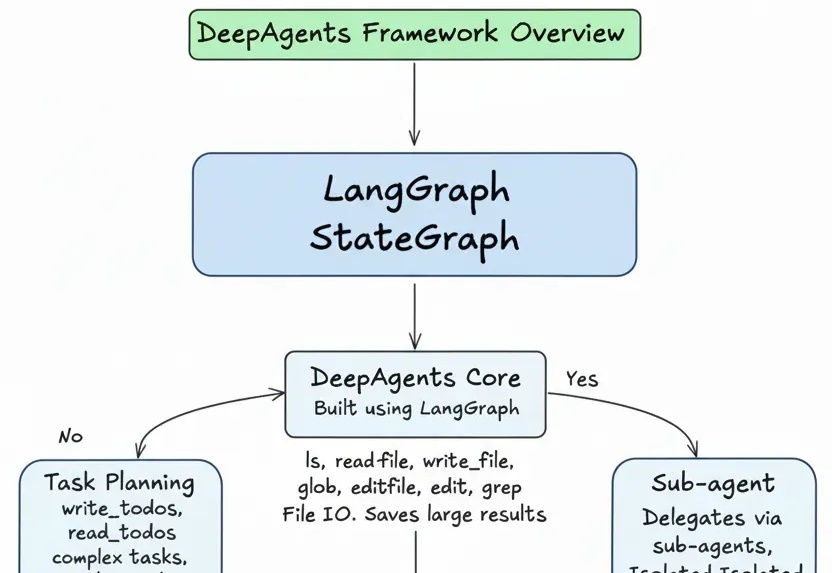
任务规划+文件系统访问+子agent委托
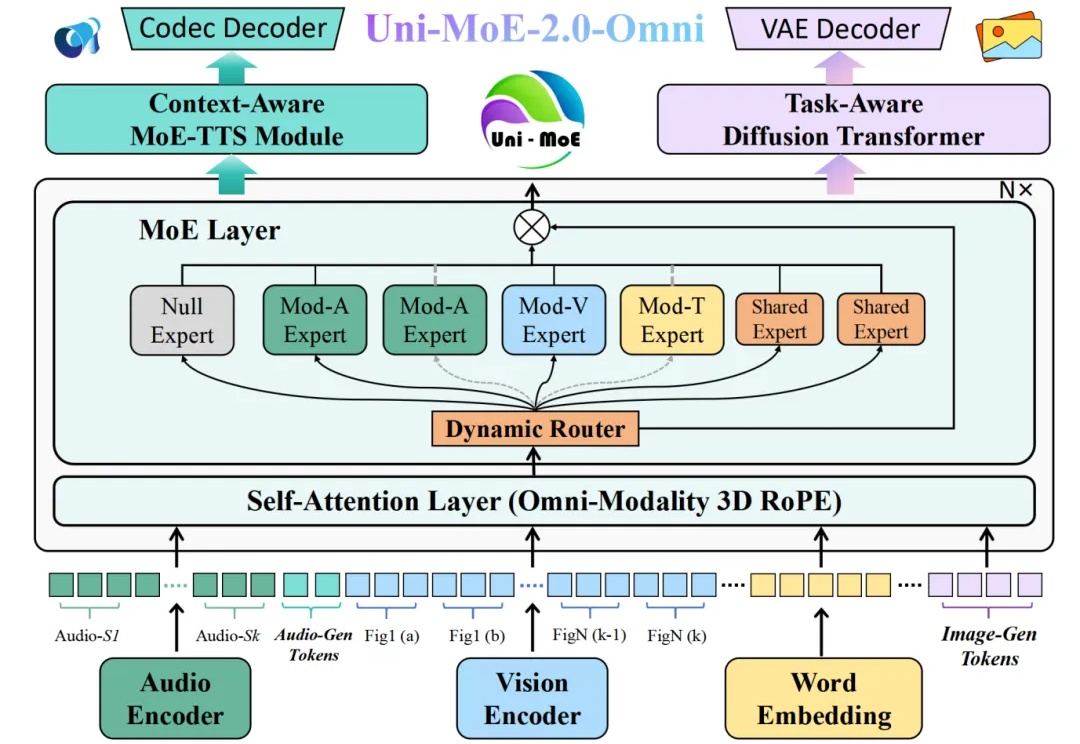
全模态大模型(Omnimodal Large Models, OLMs)能够理解、生成、处理并关联真实世界多种数据类型,从而实现更丰富的理解以及与复杂世界的深度交互。人工智能向全模态大模型的演进,标志着其从「专才」走向「通才」,从「工具」走向「伙伴」的关键点。

最近不论是在学术圈还是产业实践中,对于RLVR和传统SFT之间的区别与联系,以及RL本身基于奖励建模反馈机制并结合不同的策略优化算法过程中对模型显性知识的学习和隐参数空间的变化的讨论热度一直很高。

如果告诉你,仅仅改变提示词(Prompt)的结构,就能让大模型在复杂推理任务上的表现暴涨 60%,你相信吗?

最新研究发现,只要把恶意指令写成一首诗,就能让Gemini和DeepSeek等顶尖模型突破安全限制。这项针对25个主流模型的测试显示,面对「诗歌攻击」,百亿美金堆出来的安全护栏瞬间失效,部分模型的防御成功率直接归零。最讽刺的是,由于小模型「读不懂」诗里的隐喻反而幸免于难,而「有文化」的大模型却因为过度解读而全线破防。
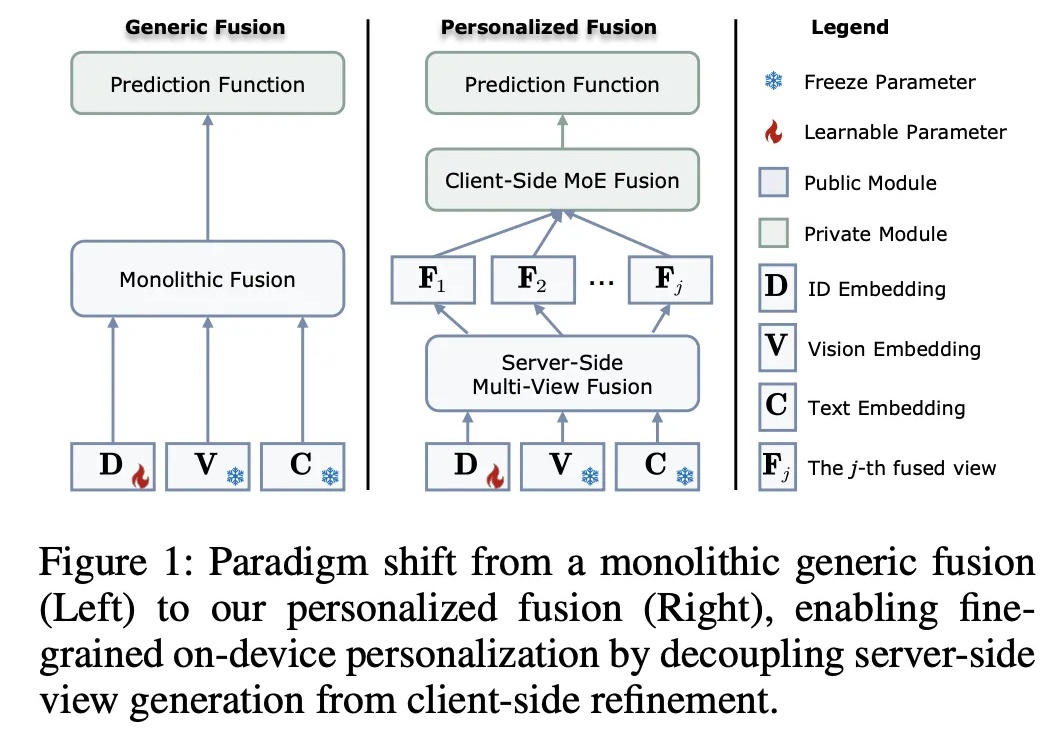
在推荐系统迈向多模态的今天,如何兼顾数据隐私与个性化图文理解?悉尼科技大学龙国栋教授团队联合香港理工大学杨强教授、张成奇教授团队,提出全新框架 FedVLR。该工作解决了联邦环境下多模态融合的异质性难题,已被人工智能顶级会议 AAAI 2026 接收为 Oral Presentation。