首个通用触觉基础模型FTP-1来了!Sharpa 联合清华大学等高校,用一套策略打通21种传感器与多类具身形态
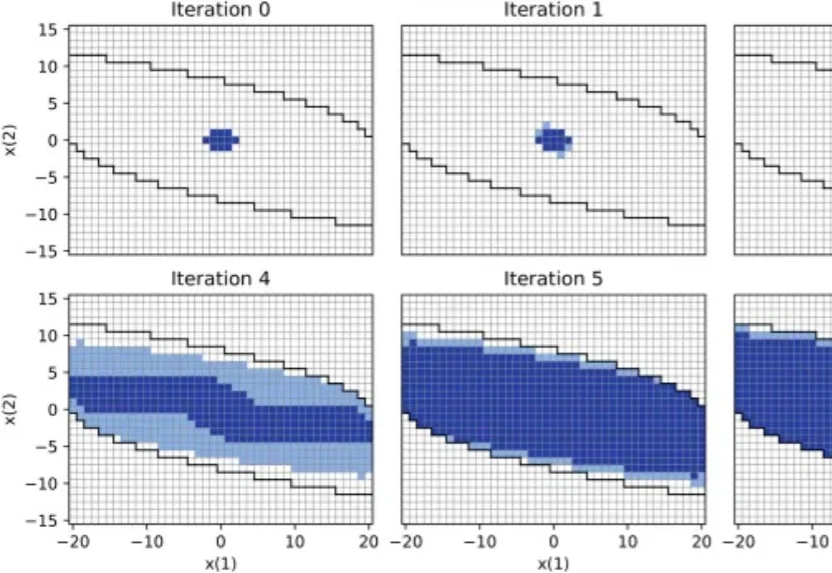
首个通用触觉基础模型FTP-1来了!Sharpa 联合清华大学等高校,用一套策略打通21种传感器与多类具身形态来自 Sharpa、清华大学、UC Berkeley、上海交通大学、ETH Zurich 等机构的研究者提出了首个通用触觉基础策略 FTP-1。它基于约 3,000 小时、来自 26 个数据来源和 21 种触觉传感器的数据进行预训练
来自主题: AI资讯
9652 点击 2026-06-28 11:12