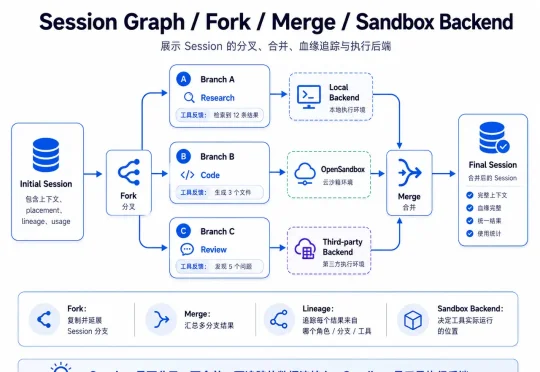
上百个Agent,该怎么管?清华团队新思路:用OpenRath重做Session
上百个Agent,该怎么管?清华团队新思路:用OpenRath重做Session最近,一个来自清华大学与中山大学的团队(Rath Team)把他们的解法开源了,叫OpenRath:这是一个像PyTorch的多智能体、多会话运行时。它的主张是:别再围着Agent转了。真正该被当成一等公民的,是Session。
来自主题: AI资讯
8945 点击 2026-06-18 10:29
 搜索
搜索
最近,一个来自清华大学与中山大学的团队(Rath Team)把他们的解法开源了,叫OpenRath:这是一个像PyTorch的多智能体、多会话运行时。它的主张是:别再围着Agent转了。真正该被当成一等公民的,是Session。
AI 正在学着操作电脑。由清华大学计算机系博士团队创立的非十科技,最近发布了一款桌面 Agent 产品 ———Agivar。与多数产品试图优化 Prompt 不同,它选择从另一个方向切入:让 AI 主动学习用户的工作流程。
在《三体》式的科幻想象中,文明可以被遥远地观察,社会可以被冷静地记录,人类行为仿佛成为一个可被推演的复杂系统。

过去一年,具身智能行业最热闹的画面是什么?

可以说生数科技是最原教旨主义的清华系AI创业公司:仨创始人都清华的,其中俩都一个课题组的,置身清华内,相当于实验室给企业转化了。

具身智能领域新星OriginFlow(渊澈太初)宣布接连完成天使轮、战略轮、Pre-A1轮多轮融资,累计融资总额超5亿元人民币。创始人秦深涛,25岁。本科毕业于哈尔滨工业大学,目前是清华大学博士生。2025年创业,他率先提出并落地NeuroScale数据采集范式,以非侵入式运动神经接口为核心入口,为机器人采集长期缺失的物理交互数据。

新智元近日对话了清华大学教授沈阳。作为长期关注 AI 应用、智能体与产业实践的学者,同时也是 ZeeLin(智灵动力)首席科学家,他个人每天的Token消耗量近10亿,本次对话围绕「自进化AI的自我递归进化」这一主线展开,讨论 AI 自进化与科研、叙事、商业与AGI相关的十个话题。
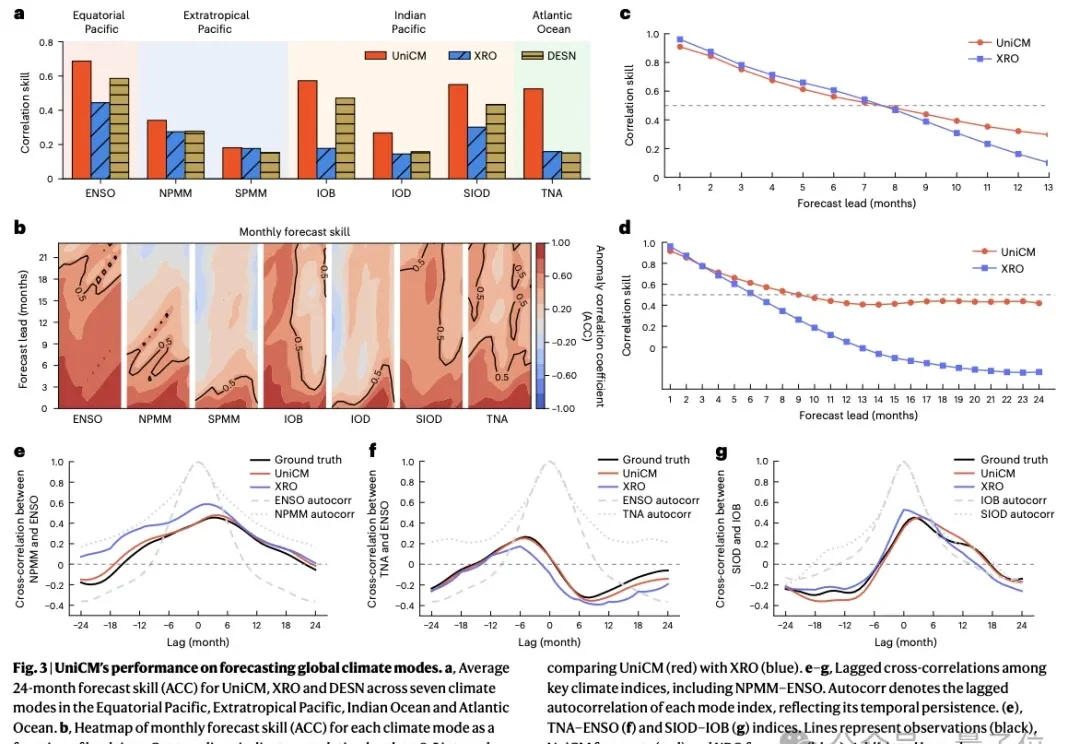
全球气候异常事件正在深刻影响农业生产、水资源调度、能源管理和防灾减灾。

硬氪获悉,具身智能世界模型公司「千诀科技」日前完成数亿元A轮融资,本轮由京铭资本领投,山东新动能、山东财金资本、元禾厚望、芯能创投、南创投、英诺天使基金、尚势资本、仁爱集团、玄素投资等机构共同投资,投资方阵容汇集了国家队、产业方、市场化基金及家族办公室。Maple Pledge枫承资本长期出任私募股权融资顾问。

随着视频生成技术的发展,模型正在从短视频片段合成,向流式长视频生成演进。然而,仅仅做到视觉上的逼真是不够的。一个功能完备的视频世界模型,必须能够在长时序交互中保持稳定的内部状态,并遵循真实世界的物理定律与逻辑规则。