

大模型的第一性原理:(一)统计物理篇
大模型的第一性原理:(一)统计物理篇白铂 博士,华为 2012 实验室理论研究部主任 信息论首席科学家
来自主题: AI技术研报
10959 点击 2025-12-12 08:57
白铂 博士,华为 2012 实验室理论研究部主任 信息论首席科学家

今日凌晨,比OpenAI早一个小时,谷歌甩出了3个Agent大招:Deep Research Agent功能更新,并首次向开发者开放;开源新网络研究Agent基准DeepSearchQA,旨在测试Agent在网络研究任务中的全面性;推出新交互API(Interactions API)。
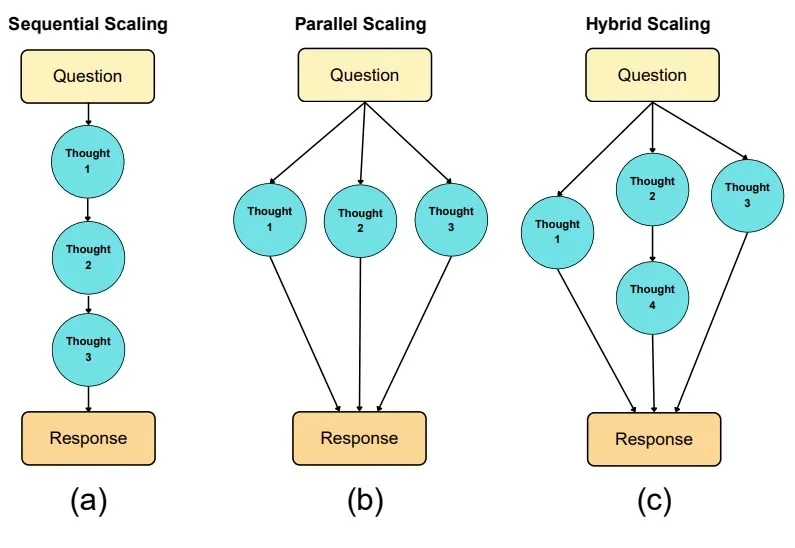
如果说大模型的预训练(Pre-training)是一场拼算力、拼数据的「军备竞赛」,那么测试时扩展(Test-time scaling, TTS)更像是一场在推理阶段进行的「即时战略游戏」。

有关大语言模型的理论基础,可能要出现一些改变了。
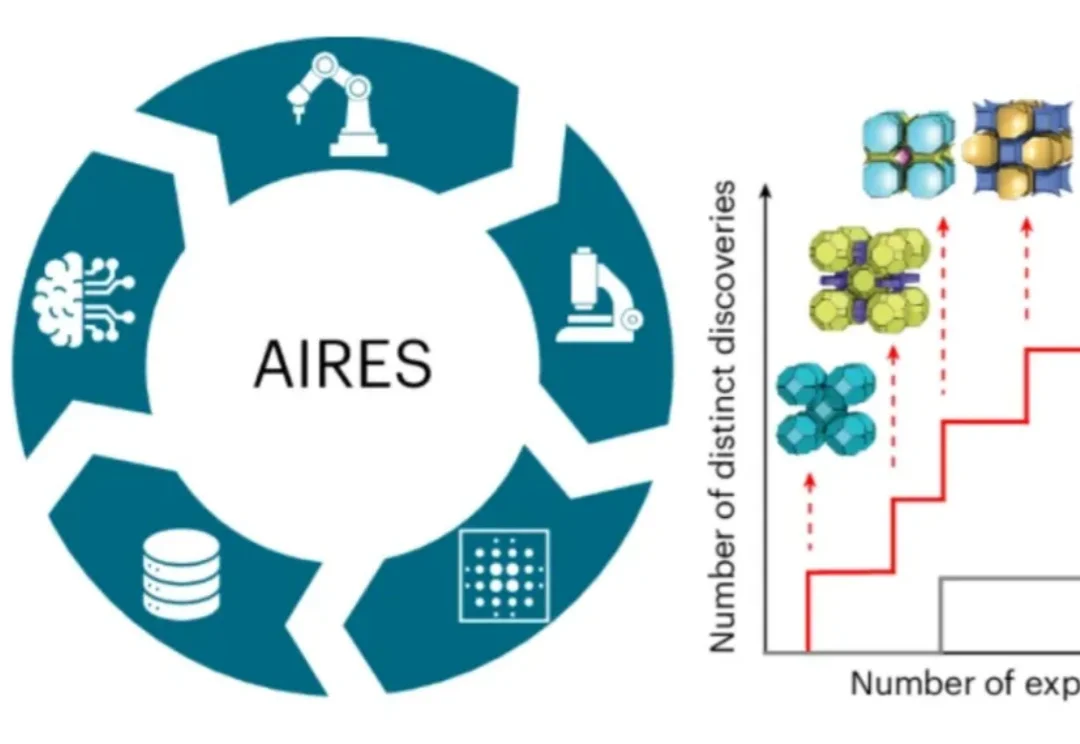
近日,师从新晋诺贝尔化学奖得主奥马尔·亚吉(Omar M. Yaghi)、目前在美国加州大学伯克利分校读博的荣自超,带领一个跨国际的研究团队,打造出名为AIRES (algorithmic iterative reticular synthesis)的机器学习指导的高通量实验平台,

宾夕法尼亚大学沃顿商学院(The Wharton School)今年发布了一系列名为《Prompting Science Reports》的重磅研究报告。他们选取了2024-2025最常用的模型(如GPT-4o, Claude 3.5 Sonnet, Gemini Pro/Flash等),在极高难度的博士级基准测试(GPQA Diamond)上进行了数万次的严谨测试。
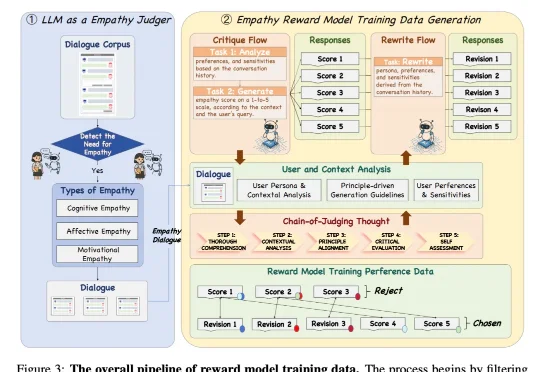
近日,来自 NatureSelect(自然选择)的研究团队 Team Echo 发布了首个情感大模型 Echo-N1,提出了一套全新的「情感模型训练方法」,成功将 RL 用在了不可验证的主观情感领域。仅 32B 参数的 Echo-N1,在多轮情感陪伴任务中胜率(Success Rate)达到 46.7%。作为对比,
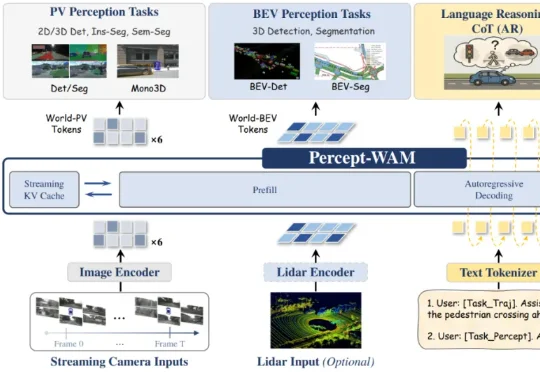
近日,来自引望智能与复旦大学的研究团队联合提出了一个面向自动驾驶的新一代大模型 ——Percept-WAM(Perception-Enhanced World–Awareness–Action Model)。该模型旨在在一个统一的大模型中,将「看见世界(Perception)」「理解世界(World–Awareness)」和「驱动车辆行动(Action)」真正打通,形成一条从感知到决策的完整链路。

为了打破英伟达的算力垄断,谷歌正在扶持云服务商Fluidstack分发自研TPU芯片,目前该公司正洽谈一轮7亿美元的巨额融资。最有意思的是,本轮融资的潜在领投方,竟是被OpenAI「扫地出门」的天才研究员阿申布伦纳。在这场算力豪赌中,谷歌的野心、前OpenAI核心成员的复仇与资本的狂热正交织在一起。

该公司年度经常性收入不到1000万美元。据TechCrunch援引知情人士报道,美国AI合成研究创企Aaru已完成由红点创投领投的A轮融资,公司名义估值(公司对外公布用于宣传的估值)达到10亿美元(约合人民币70.7亿元)。