
独家 | CMU系⼜诞⽣⼀家具⾝智能公司「Zeno AI」
独家 | CMU系⼜诞⽣⼀家具⾝智能公司「Zeno AI」AI科技评论独家获悉,卡内基梅隆⼤学机器⼈研究院(CMURI)博⼠后、悉尼⼤学(USYD)⻓聘助理教授WilliamZhi联合创办具⾝智能公司⸺ZenoAI(芝诺机器⼈),致⼒于打造通⽤全栈物理智能(Full-stackPhysicalAI),提供可靠的全⾝灵巧操作解决⽅案。
来自主题: AI资讯
7808 点击 2026-04-21 13:17
 搜索
搜索
AI科技评论独家获悉,卡内基梅隆⼤学机器⼈研究院(CMURI)博⼠后、悉尼⼤学(USYD)⻓聘助理教授WilliamZhi联合创办具⾝智能公司⸺ZenoAI(芝诺机器⼈),致⼒于打造通⽤全栈物理智能(Full-stackPhysicalAI),提供可靠的全⾝灵巧操作解决⽅案。
如果摔断了手、打了两个月石膏,工作却不能停,程序员该怎么办?Anthropic 的研究员、《构建高效智能体》合著者 Erik Schluntz 的答案是:全权交给 Claude。

中国人民大学团队打造的AiScientist,旨在解决长程机器学习研究工程的持续性难题。该系统从论文理解开始,跨越环境配置、代码实现与实验迭代,保持状态连续与决策连贯,显著提升科研效率。其核心在于通过File-as-Bus机制,稳定保存项目状态,使AI能真正接手科研流程,而非仅辅助单个环节。
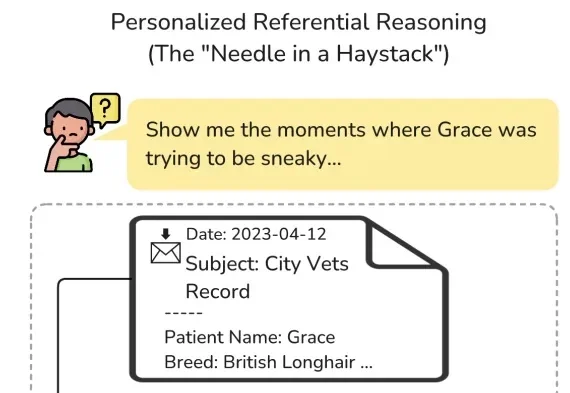
ATM-Bench 将「个人 AI 助手是否真的记得你」这件事,变成了一个研究的测试基准。结果并不乐观:专用记忆智能体系统普遍低于 20%,而 OpenClaw、Codex、Claude Code 等通用智能体普遍表现不佳,最高准确率不到 40%。

如今的大多数智能体,仍然活在一种「失忆式工作」模式中:每一次检索都是从零开始,每一条推理路径都无法沉淀,每一次失败也不会转化为经验。它们虽能多轮交互,但很难在深度研究中持续变强。

Anthropic 没有公开 Claude Mythos 的架构。但研究社区没有等。

如何创建大规模的Physical AI数据,来加速Physical AI开发者的进展。我们采取的方法,本质上是用算力去换数据;

研究者们花了十年去扩展层内的计算能力,却忘了扩展层间的通信能力。
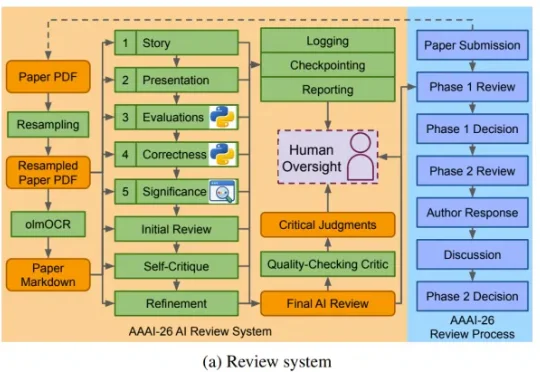
AI 的整体表现已经胜过了人类。或者按 AAAI 官方的说法是:「对 AAAI-26 作者和程序委员会成员的大规模调查显示,参与者不仅认为 AI 评审有用,而且在技术准确性和研究建议等关键维度上,实际上更偏好 AI 评审。」

IPO前夕,OpenAI一天流失三位高管!Sora创始人Bill Peebles,他负责的Sora已经直接被关停,团队转移到别的方向。AI for Science副总裁Kevin Weil,他的团队被拆分并入其他研究组。