ICML 2026|从「鉴伪」到「修复」,AI图像取证进入闭环时代
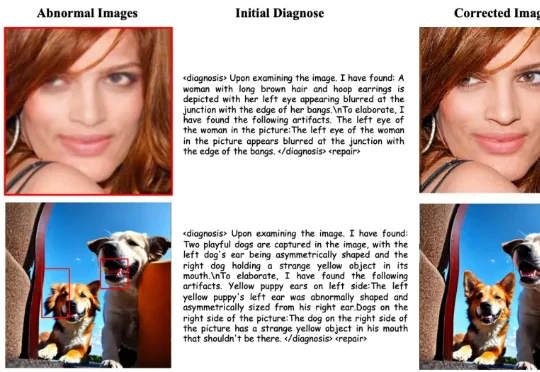
ICML 2026|从「鉴伪」到「修复」,AI图像取证进入闭环时代对于 AI 生成图像中可能存在的不自然伪影,我们是否不仅能够将其定位和解释,还能进一步对其进行修复,使图像恢复为更加真实、自然的视觉外观?围绕这一问题,来自北京大学等机构的研究者提出了 GenShield:一个统一的自回归框架,将 AI 生成图像检测 与 图像伪影修复 结合到同一个闭环中,实现从 “诊断” 到 “修复” 的一体化建模。
来自主题: AI技术研报
7709 点击 2026-06-21 10:31