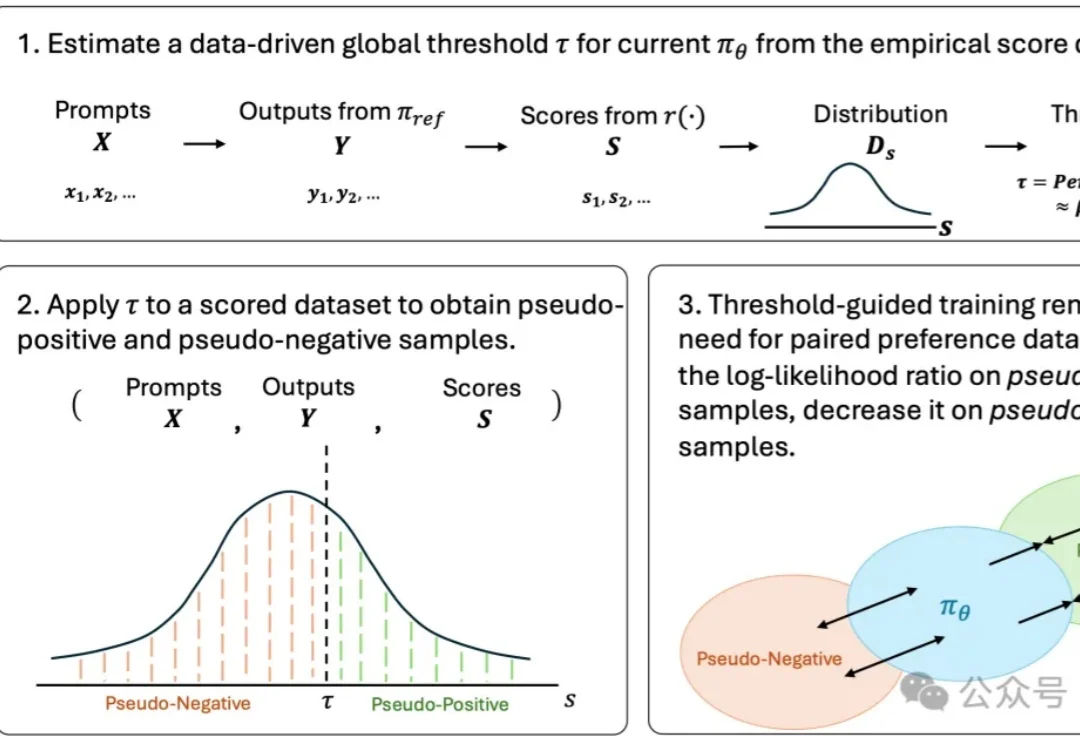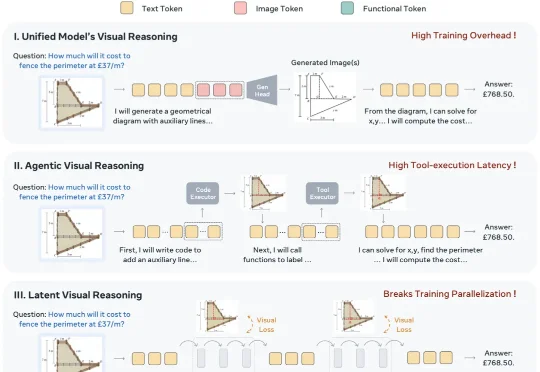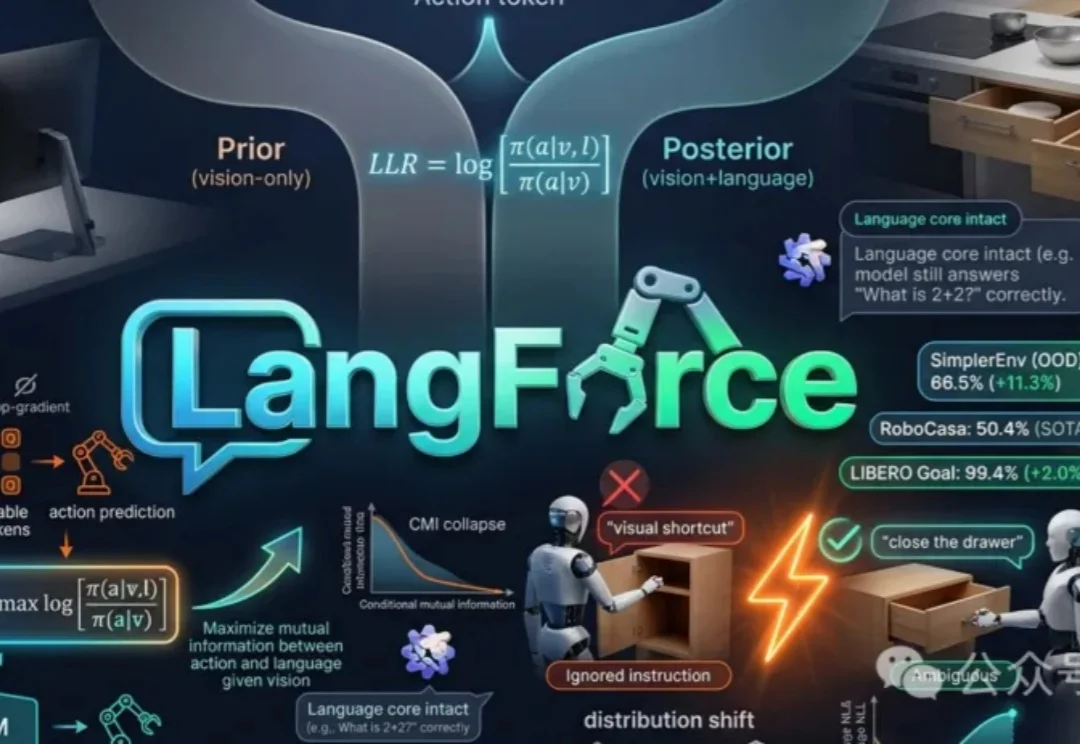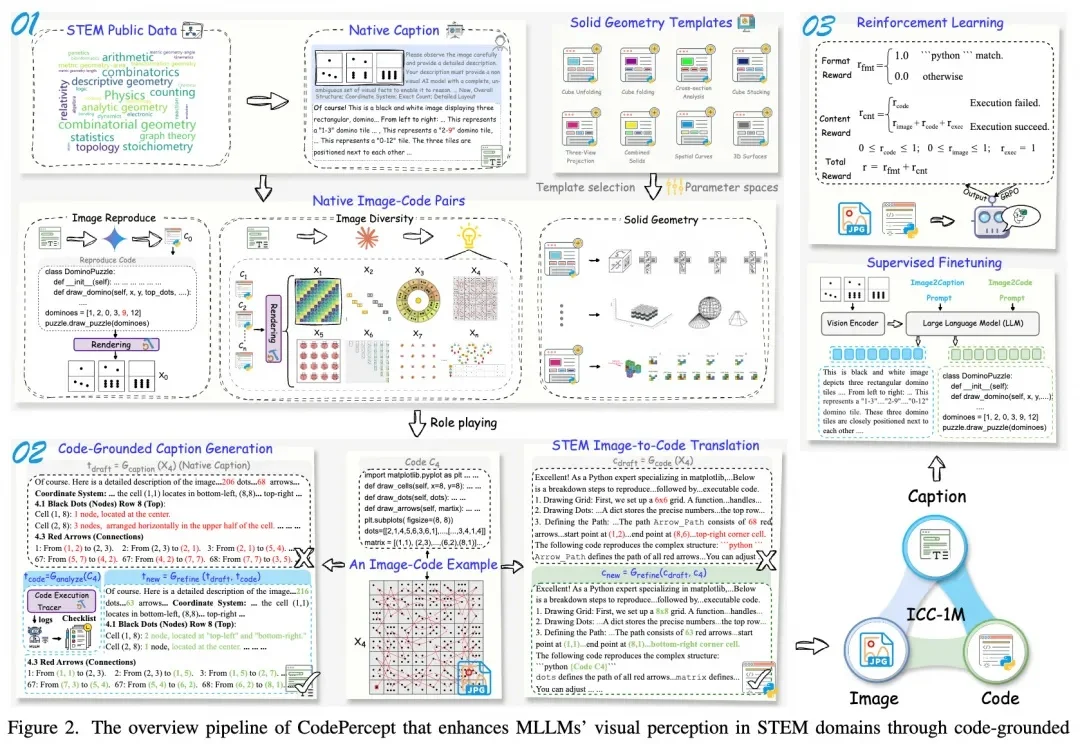
CVPR 2026 Oral | 清华+阿里发布ViT³:解锁「视觉TTT」新架构,突破Transformer复杂度瓶颈
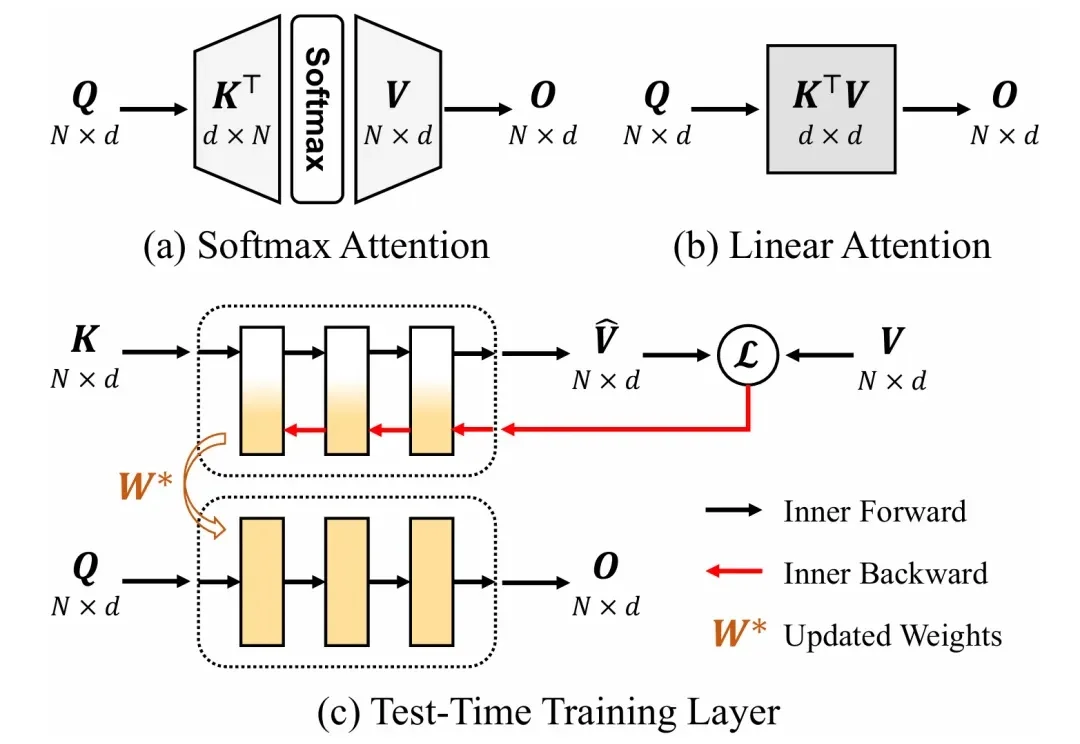
CVPR 2026 Oral | 清华+阿里发布ViT³:解锁「视觉TTT」新架构,突破Transformer复杂度瓶颈序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。
来自主题: AI技术研报
6099 点击 2026-05-18 15:30