

训练机器人方式对了吗?英伟达DreamZero双榜第一新反思
训练机器人方式对了吗?英伟达DreamZero双榜第一新反思近日,NVIDIA 发布的世界 - 动作模型 DreamZero,在两项颇具代表性的机器人基准测试 RoboArena 、MolmoSpaces 上双双登顶。
来自主题: AI技术研报
9188 点击 2026-03-04 14:32
近日,NVIDIA 发布的世界 - 动作模型 DreamZero,在两项颇具代表性的机器人基准测试 RoboArena 、MolmoSpaces 上双双登顶。
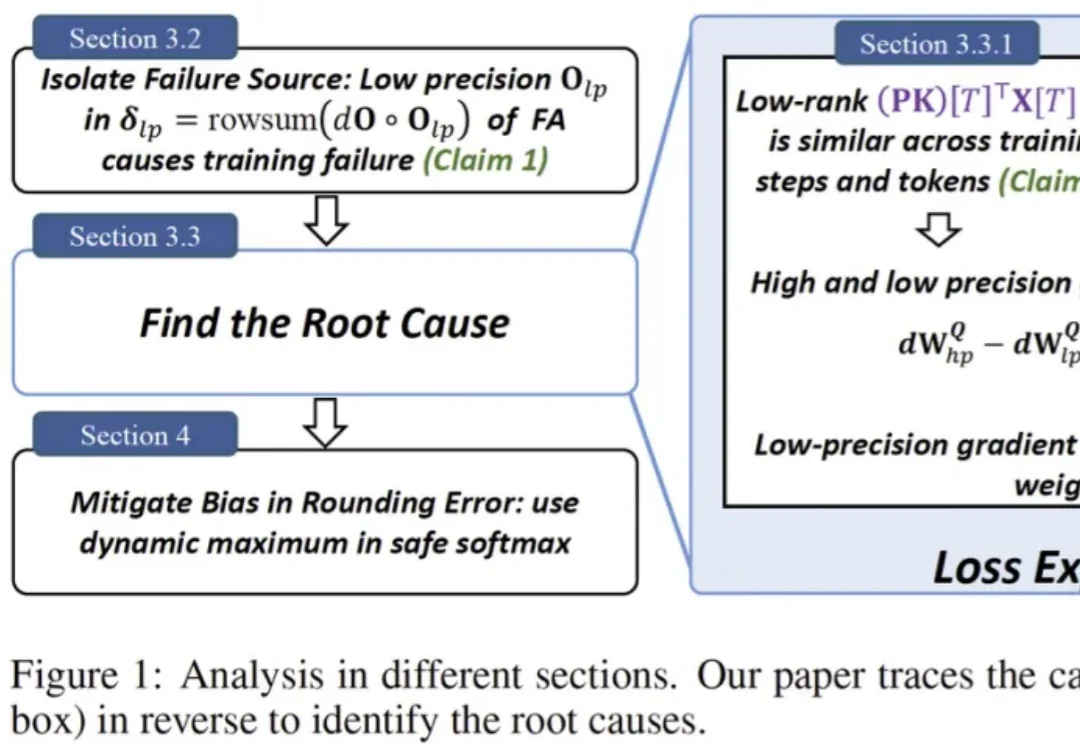
一句话总结:社区里困扰了多年的一个 “玄学” 现象终于被拆解清楚了:在 BF16 等低精度训练里,FlashAttention 不是随机出 bug,而是会在特定条件下触发有方向的数值偏置,借助注意力中涌现的相似低秩更新方向被持续放大,最终把权重谱范数和激活推到失控,导致 loss 突然爆炸。论文还给出一个几乎不改模型、只在 safe softmax 里做的极小修改,实测能显著稳定训练。
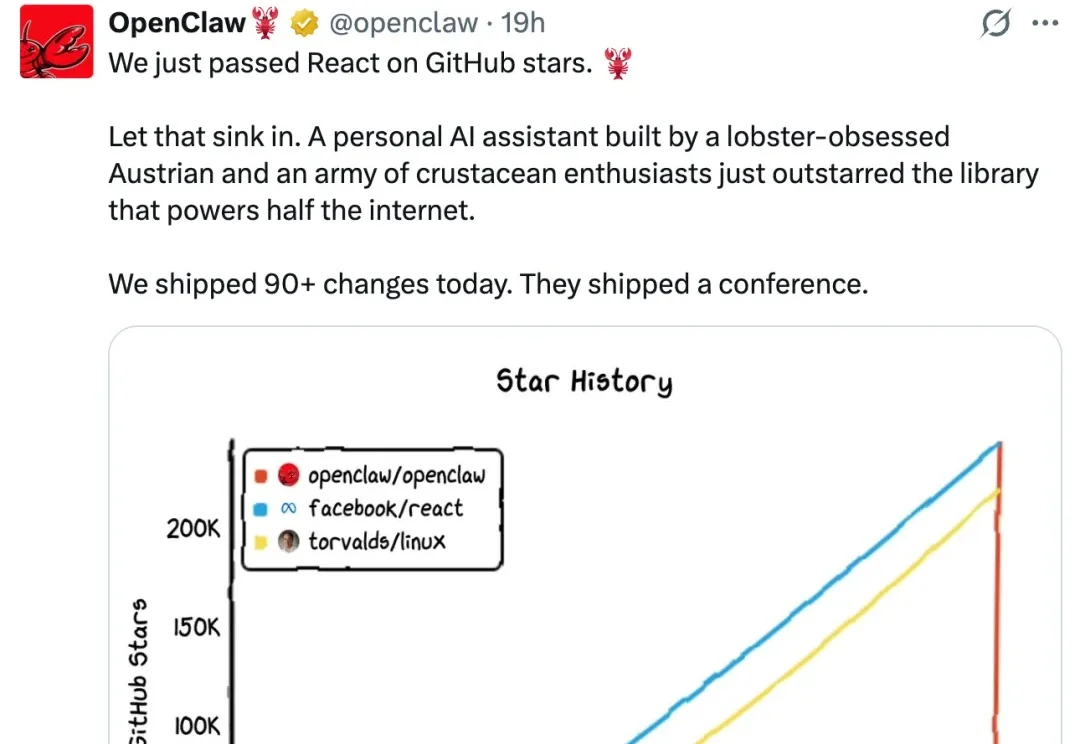
2026 开年已两个月,Agent 依然是全球最引人注目的 AI 赛道之一。OpenClaw(原 Clawbot)掀起的那波 Agent 热潮至今仍在发酵,甚至让「一人公司」概念第一次真正有了落地的可能性。

全新的具身模型空间能力评估范式 Theory of Space 突破了传统静态图文问答的局限,系统性地考察基础模型能否像人一样,在部分可观测的动态环境中,通过自主探索来构建、修正和利用空间信念。该论文已被 ICLR 2026 接收。
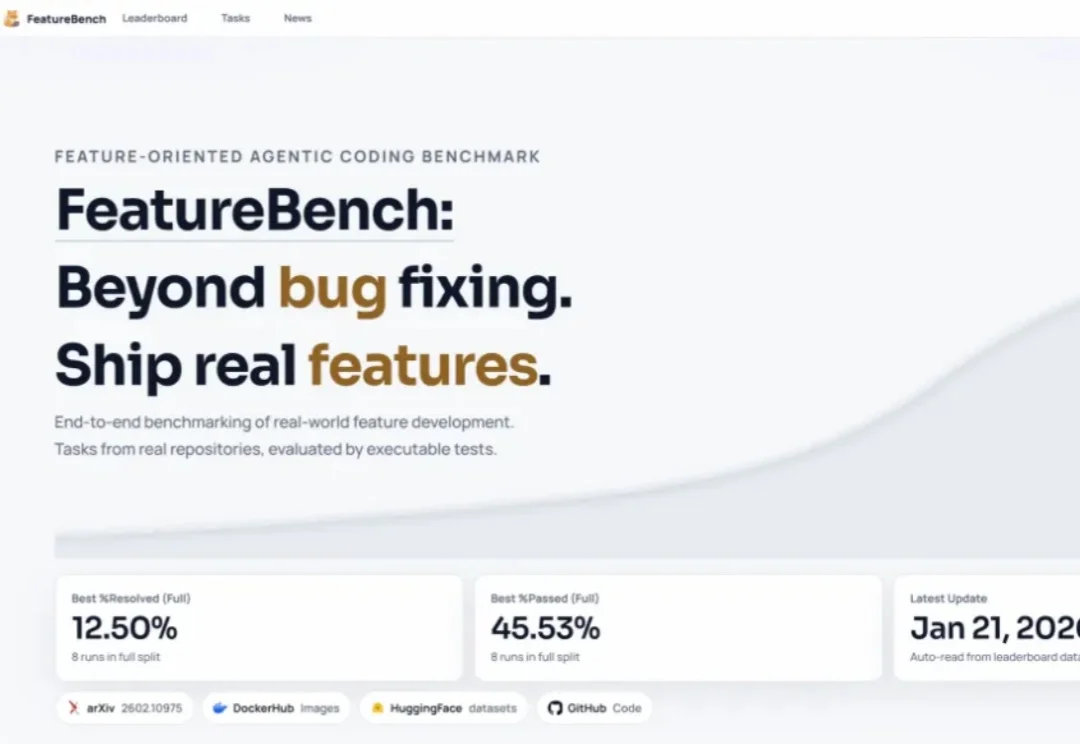
在 Princeton 发布 SWE-Bench 之后,用真实世界代码仓库+可执行测试评测大模型软件工程能力,几乎已成为学术界与工业界的共识。围绕 SWE issue 的评测范式迅速发展,也催生了一系列 SWE 系列 benchmark,在刻画模型 bug 修复能力方面发挥了重要作用。

伴随多模态大模型的发展,GUI Agent正成为人机交互的新范式。
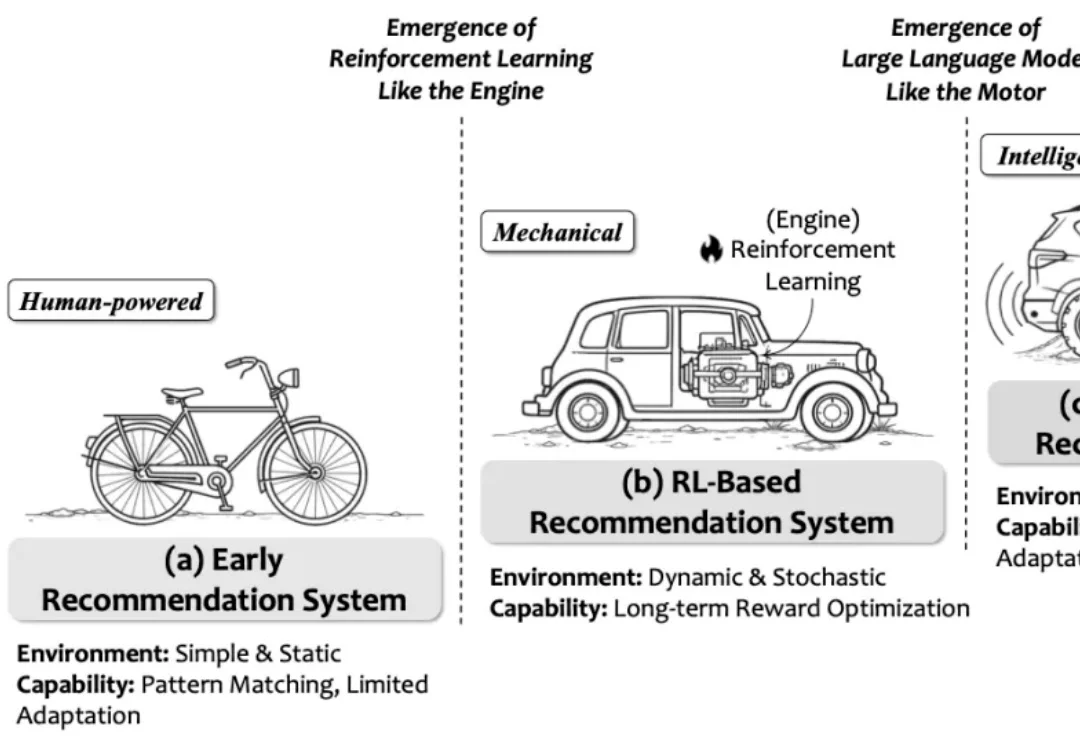
强化学习(RL)将推荐系统建模为序列决策过程,支持长期效益和非连续指标的优化,是推荐系统领域的主流建模范式之一。然而,传统 RL 推荐系统受困于状态建模难、动作空间大、奖励设计复杂、反馈稀疏延迟及模拟环境失真等瓶颈。
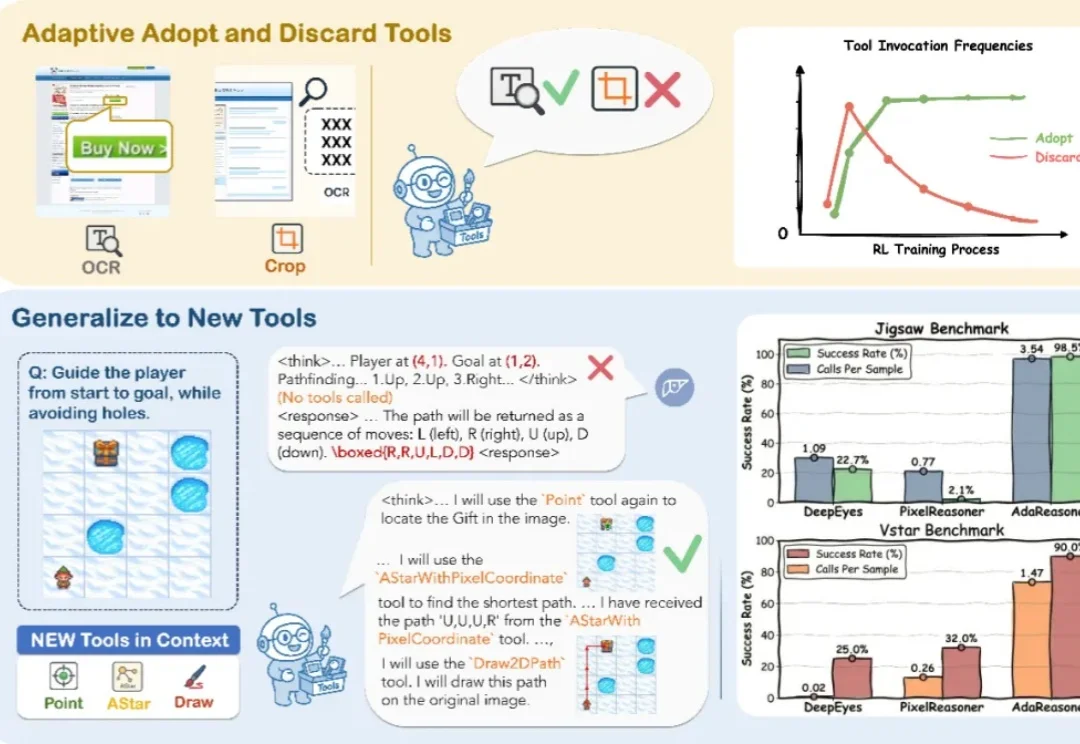
你见过 7B 模型在拼图推理上干翻 GPT-5 吗?

让AI自己写高性能GPU代码,字节Seed与清华AIR团队做到了。

没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。