
GPT-5得分不到0.4!法律+金融最大规模基准:1.9万+专家评估准则
GPT-5得分不到0.4!法律+金融最大规模基准:1.9万+专家评估准则最新PRBench基准可以测试AI在金融和法律领域的表现。结果显示,即使是顶尖大模型在处理复杂任务时也表现不佳,尤其在涉及重大经济后果的任务中。PRBench通过模拟真实场景和多轮对话,揭示了AI在专业领域的不足,强调开发更可靠AI系统的重要性。
来自主题: AI技术研报
7717 点击 2025-11-22 11:33
最新PRBench基准可以测试AI在金融和法律领域的表现。结果显示,即使是顶尖大模型在处理复杂任务时也表现不佳,尤其在涉及重大经济后果的任务中。PRBench通过模拟真实场景和多轮对话,揭示了AI在专业领域的不足,强调开发更可靠AI系统的重要性。
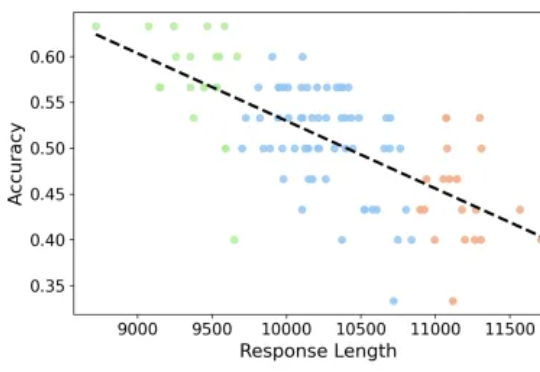
专注推理任务的 Large Reasoning Models 在数学基准上不断取得突破,但也带来了一个重要问题:越想越长、越长越错。本文解读由 JHU、UNC Charlotte 等机构团队的最新工作

前沿AI竞赛在2025年11月达到高潮。48小时内,谷歌推出Gemini 3 Pro宣称在主要推理基准测试中领先,而OpenAI立即用GPT-5.1-Codex-Max反击,这是一款专门训练用于通过创新"压缩"(compaction)技术自主工作超过24小时的专业编码模型[43]。加上Claude Sonnet 4.5已确立的编码统治地位和激进的安全过滤器,开发者面临前所未有的选择:
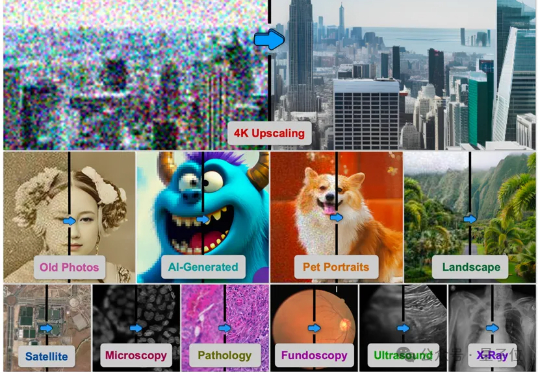
由德克萨斯A&M大学、斯坦福大学、Snap公司、CU Boulder大学、德克萨斯大学奥斯汀分校、加州理工大学、Topaz Labs以及加州大学Merced分校的研究者联合提出的基于AI智能体的方法4KAgent针对不同类型的图像以及需求对图像进行智能修复并放大到4K分辨率,带来优秀的视觉感知效果。该工作已被NeurIPS 2025接收。
昨天,DeepSeek 在 GitHub 上线了一个新的代码库:LPLB。
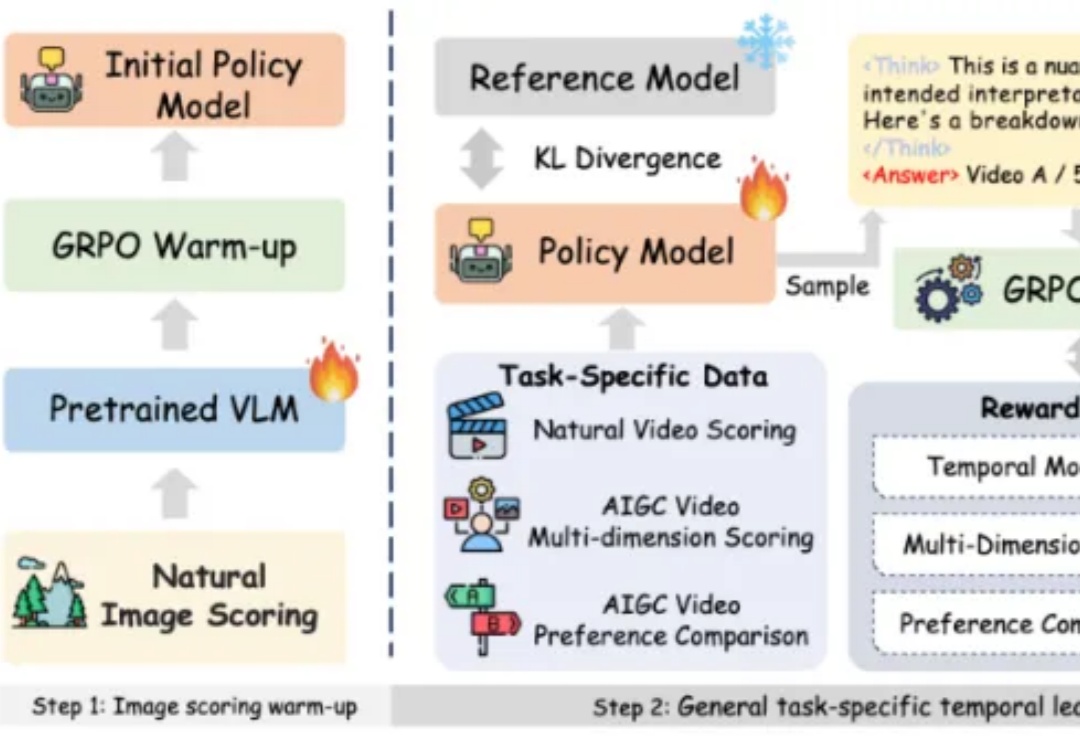
近日,AAAI 2026 公布了录用结果,该会议是是人工智能领域极具影响力的国际顶级学术会议之一。据悉本次会议共有 23680 篇投稿进入审稿阶段,最终 4167 篇论文被录用,录取率为 17.6%。
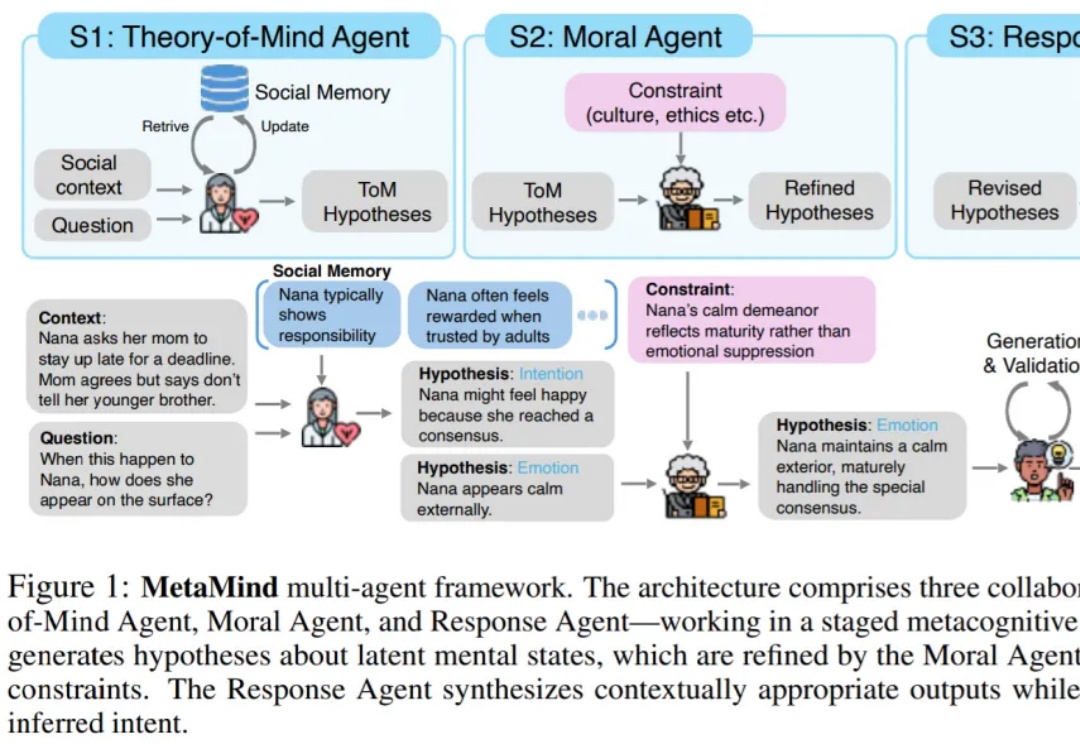
“What is meant often goes far beyond what is said, and that is what makes conversation possible.” ——H. P. Grice
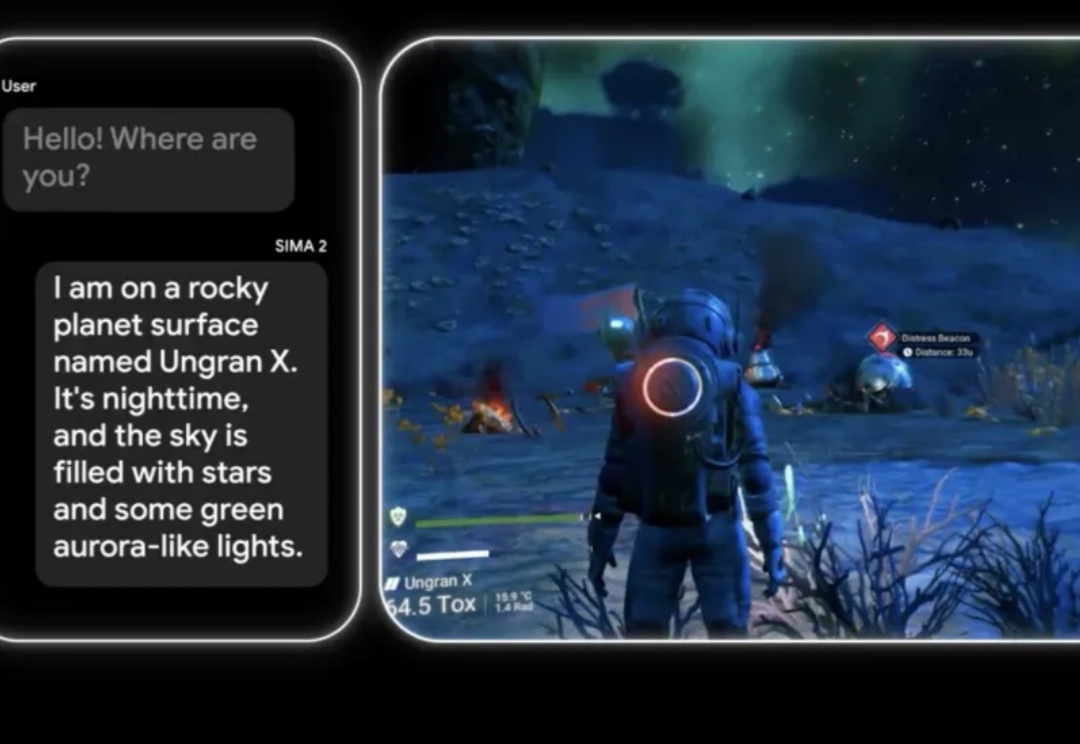
游戏,是AI通往真实世界的训练场。

继轻量级强化学习(RL)框架 slime 在社区中悄然流行并支持了包括 GLM-4.6 在内的大量 Post-training 流水线与 MoE 训练任务之后,LMSYS 团队正式推出 Miles——一个专为企业级大规模 MoE 训练及生产环境工作负载设计的强化学习框架。

扩散模型「去噪」,是不是反而忘了真正去噪?何恺明携弟子出手,回归本源!