
谷歌发布智能体Scaling Law:180组实验打破传统炼金术
谷歌发布智能体Scaling Law:180组实验打破传统炼金术智能体(Agent),即基于语言模型且具备推理、规划和行动能力的系统,正在成为现实世界 AI 应用的主导范式。
来自主题: AI技术研报
7092 点击 2025-12-12 10:27
 搜索
搜索
智能体(Agent),即基于语言模型且具备推理、规划和行动能力的系统,正在成为现实世界 AI 应用的主导范式。

在AI医疗的技术路线和商业模式上,双方走向了不同的方向:百川押注语言模型和ToC,邓江拥抱多模态和ToB。
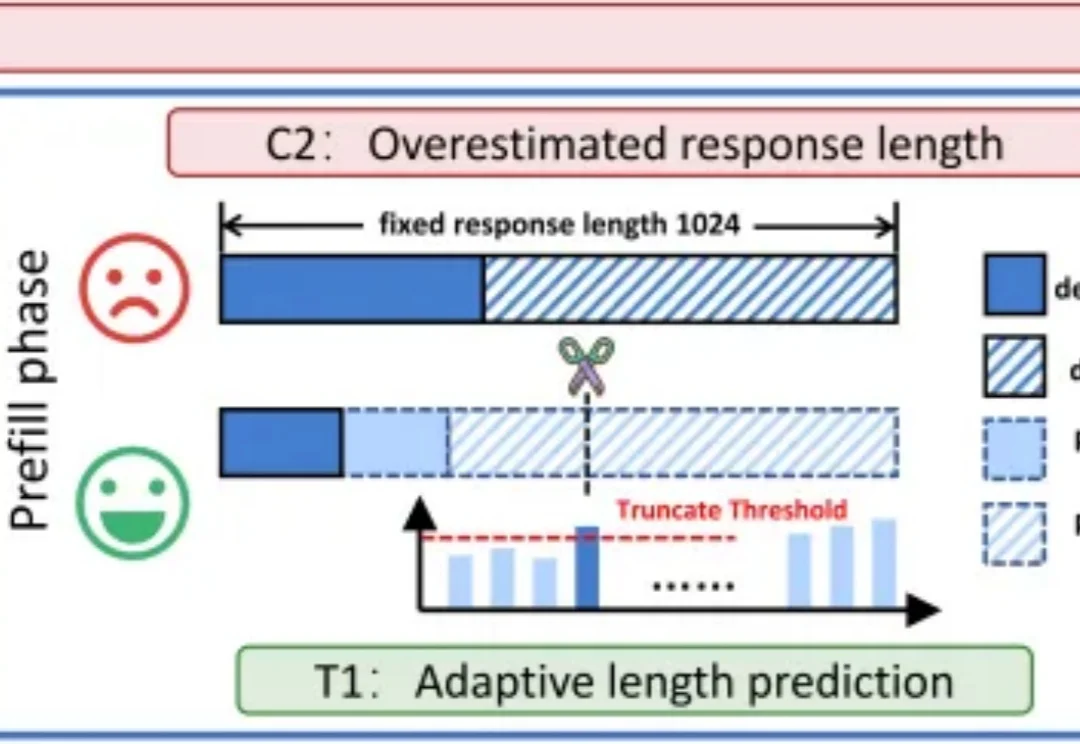
基于扩散的大语言模型 (dLLM) 凭借全局解码和双向注意力机制解锁了原生的并行解码和受控生成的潜力,最近吸引了广泛的关注。例如 Fast-dLLM 的现有推理框架通过分块半自回归解码进一步实现了 dLLM 对 KV cache 的支持,挑战了传统自回归 LLMs 的统治地位。

有关大语言模型的理论基础,可能要出现一些改变了。

今天我们正式发布 Jina-VLM,这是一款 2.4B 参数量的视觉语言模型(VLM),在同等规模下达到了多语言视觉问答(Multilingual VQA)任务上的 SOTA 基准。Jina-VLM 对硬件需求较低,可在普通消费级显卡或 Macbook 上流畅运行。
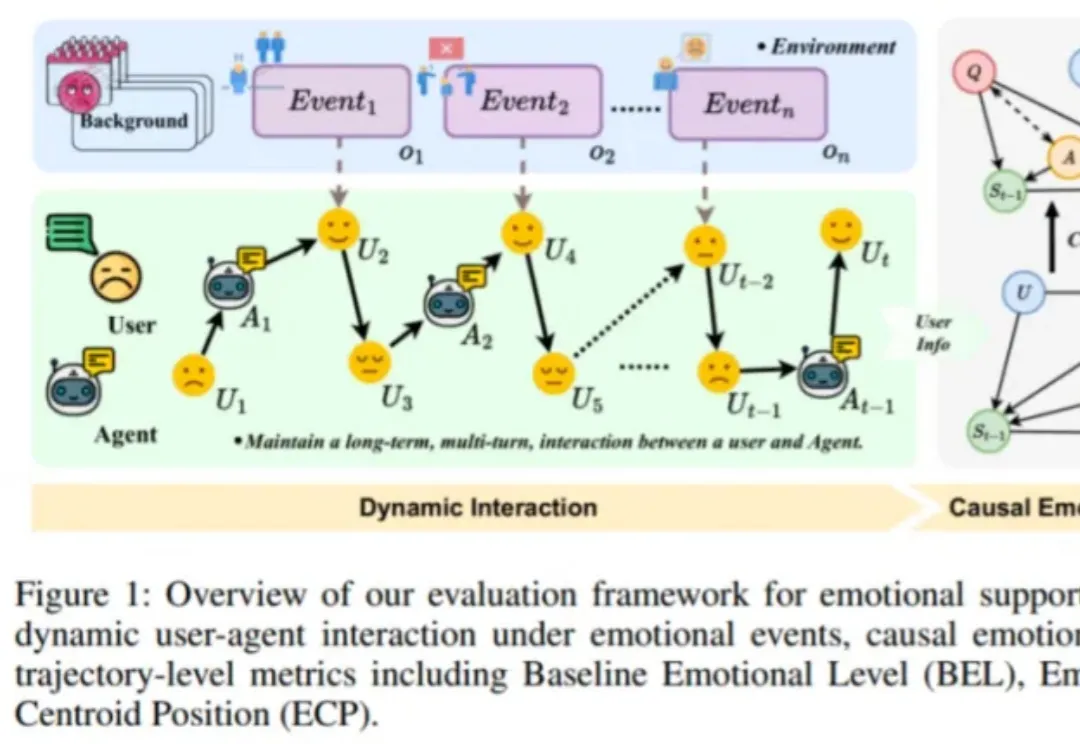
近日,由趣丸科技与北京大学软件工程国家工程研究中心共同发表的《Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models(检测情感动态轨迹:大语言模型情感支持的评估框架)》论文,获 AAAI 2026 录用。
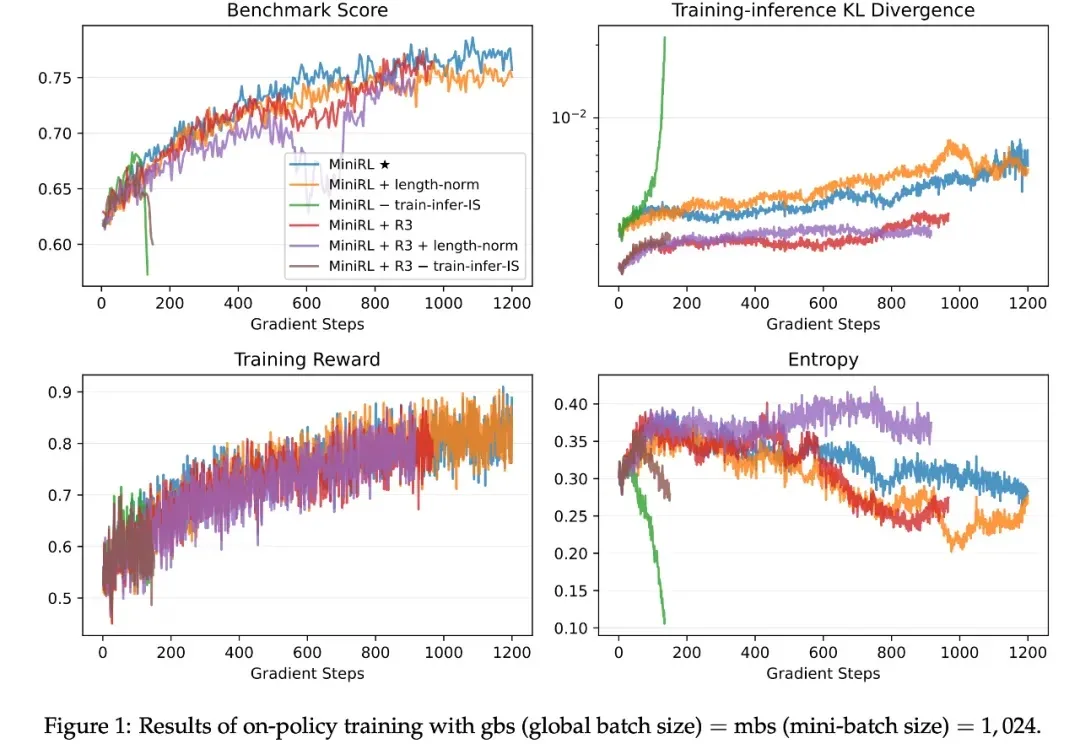
如今,强化学习(RL)已成为提升大语言模型(LLM)复杂推理与解题能力的关键技术范式,而稳定的训练过程对于成功扩展 RL 至关重要。由于语言具有强烈的上下文属性,LLM 的 RL 通常依赖序列级奖励 —— 即根据完整生成序列给一个标量分数。
关于如何避免让大语言模型产生幻觉,一直以来的相关研究都非常多。

2025 年 12 月,硅谷风险投资机构 Andreessen Horowitz(简称 a16z)与 AI 推理服务平台 OpenRouter 联合发布了一份名为《State of AI》的研究报告。这份报告基于 OpenRouter 平台上超过 100 万亿 token 的真实用户交互数据,试图呈现过去一年间大语言模型在实际应用中的真实状态。

在人工智能快速发展的今天,大语言模型已经深入到我们工作和生活的方方面面。然而,如何让AI生成的内容更加可信、可追溯, 一直是学术界和工业界关注的焦点问题。想象一下,当你向ChatGPT提问时,它不仅给出答案,还能像学术论文一样标注每句话的信息来源——这就是"溯源大语言模型"要解决的核心问题。