
开源编程语言Zig,向AI代码说「不」
开源编程语言Zig,向AI代码说「不」Zig 由一家非营利组织以及一批贡献者共同维护。任何程序员都可以向它的代码仓库提交代码,只要遵守项目的行为准则。规则之一就是:禁止提交 AI 辅助生成的代码。政策写得很清楚:不接受任何由大语言模型生成的内容,也不接受由大语言模型改写、润色、编辑、头脑风暴或调试过的内容。简单来说,就是让 AI 离 Zig 的代码贡献远一点。
来自主题: AI资讯
9041 点击 2026-05-31 12:11
 搜索
搜索
Zig 由一家非营利组织以及一批贡献者共同维护。任何程序员都可以向它的代码仓库提交代码,只要遵守项目的行为准则。规则之一就是:禁止提交 AI 辅助生成的代码。政策写得很清楚:不接受任何由大语言模型生成的内容,也不接受由大语言模型改写、润色、编辑、头脑风暴或调试过的内容。简单来说,就是让 AI 离 Zig 的代码贡献远一点。

后空翻、跑酷、单手抓举几十公斤……
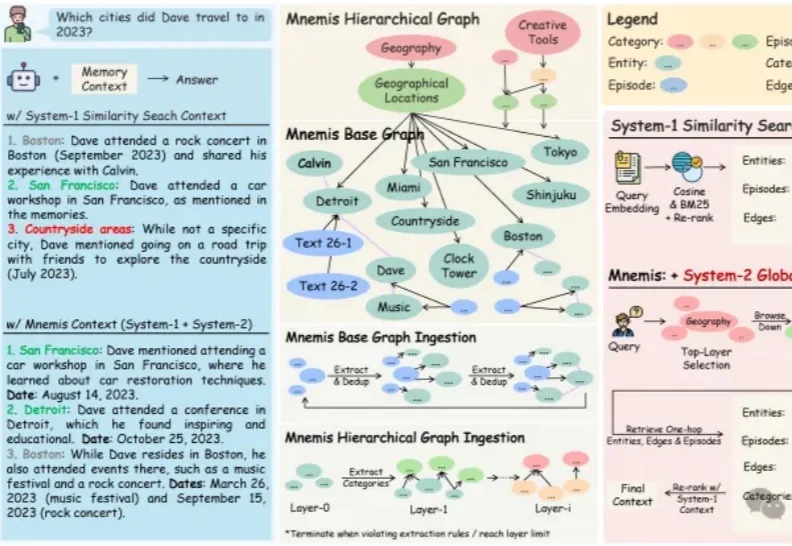
随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的RAG(检索增强生成)方案依赖语义相似度检索历史信息,但“语义相似”并不等于“真正相关”,常常出现检索结果不完整、无法区分信息相关性、缺乏推理能力等问题。
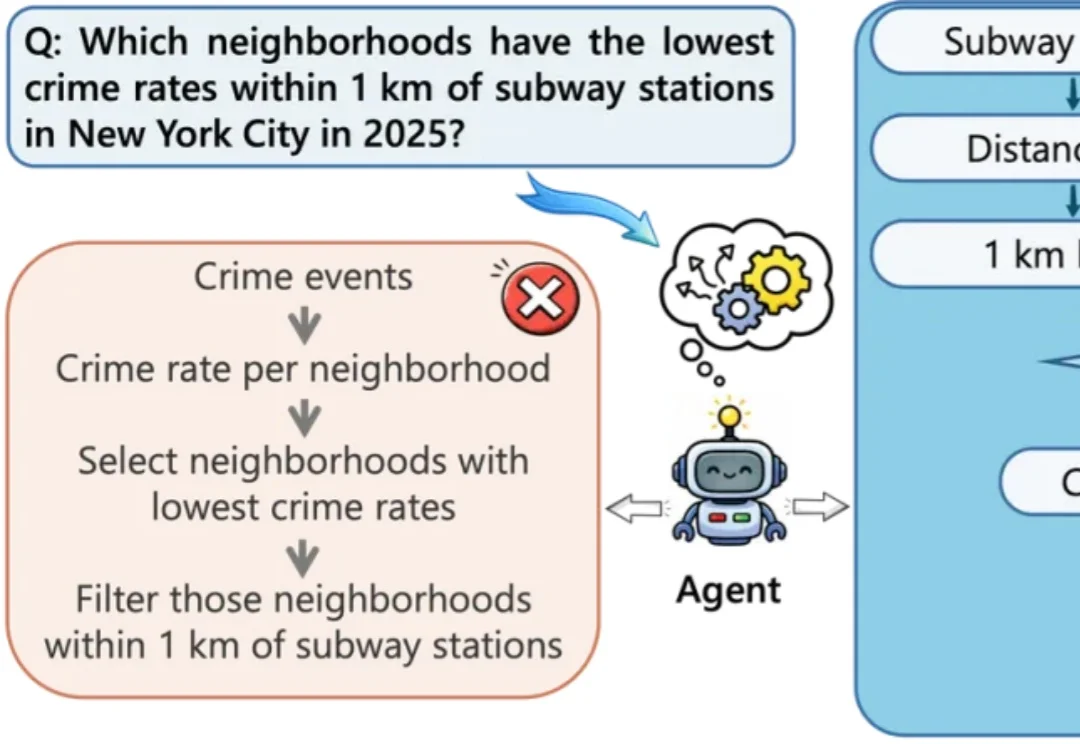
大语言模型在地图、城市、交通等空间领域的应用越来越广泛。对于这些场景来说,问题往往不只是 “查一个地点” 或 “调用一次路线 API” 就能解决的,而是需要把用户的自然语言问题组织成一段可执行、可验证的地理分析流程。
当前,测试时扩展范式普遍致力于增加推理长度。然而,已有研究表明,随着推理长度的持续增长,以垂直扩展为核心的计算范式容易陷入探索僵化等问题。因此,从另一维度拓展推理的宽度显得尤为重要。K2.5、Step3-VL 和 LongCat-Flash-Thinking 等模型已在推理宽度方面开展了有益的探索。

英伟达提出了全球首个三模式的大语言模型系列,只需简单更改注意力模式 / 掩码,即可在自回归、扩散和自推测解码之间切换。一个模型,三种解码模式,没有额外的草稿模型,没有架构变更。最快的模式 token 吞吐量能提升 4 倍。

大语言模型真的只能走“预测下一个token”的路子吗?
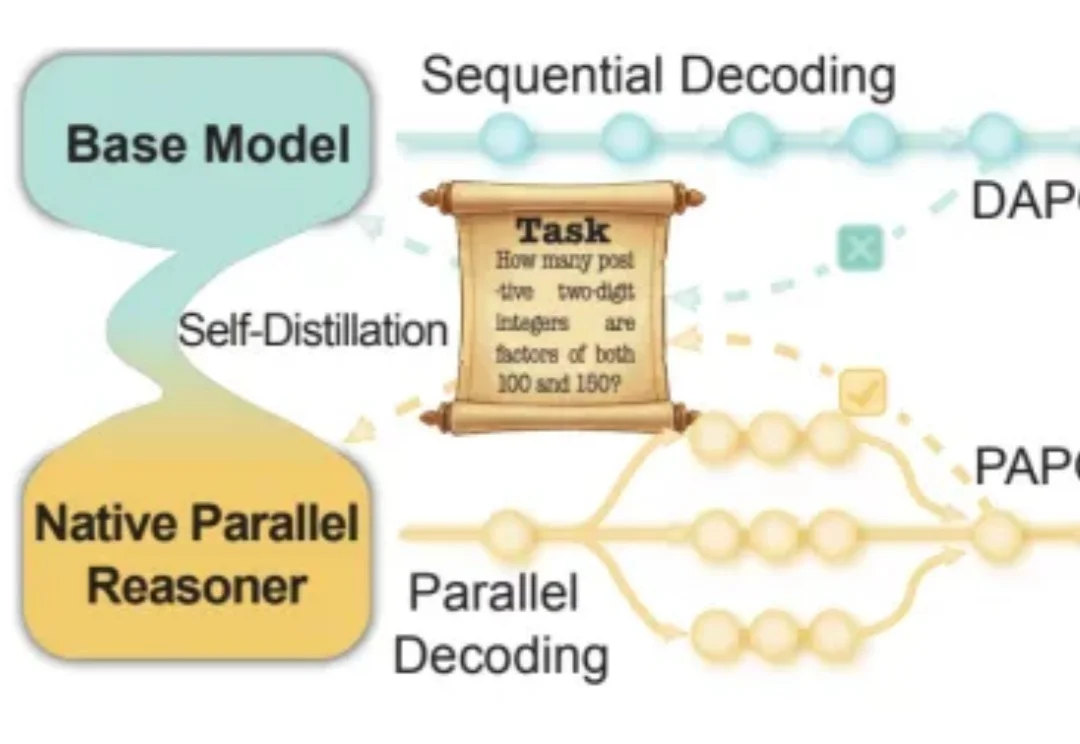
近年来,大语言模型在「写得长、写得顺」这件事上进步飞快。但当任务升级到真正复杂的推理场景 —— 需要兵分多路探索、需要自我反思与相互印证、需要在多条线索之间做汇总与取舍时,传统的链式思维(Chain-of-Thought)往往就开始「吃力」:容易被早期判断带偏、发散不足、自我纠错弱,而且顺序生成的效率天然受限。

近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。
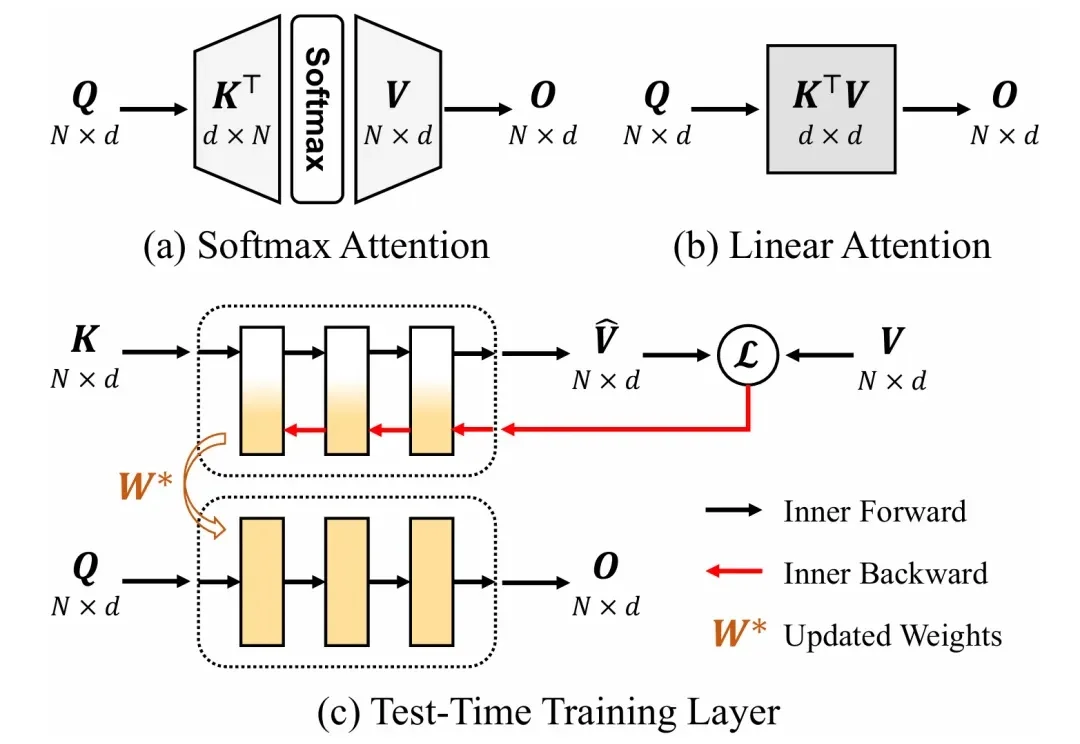
序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。