
别硬卷Prompt了,这才是普通人拥抱AI视频的最短途径!
别硬卷Prompt了,这才是普通人拥抱AI视频的最短途径!大家最近应该都被云南大神MX-Shell花3000制作的《丧尸清道夫》刷屏了吧。他做的这个抖音400多万点赞的AI视频,真的非常牛逼。
来自主题: AI技术研报
7882 点击 2026-06-01 13:56
 搜索
搜索
大家最近应该都被云南大神MX-Shell花3000制作的《丧尸清道夫》刷屏了吧。他做的这个抖音400多万点赞的AI视频,真的非常牛逼。
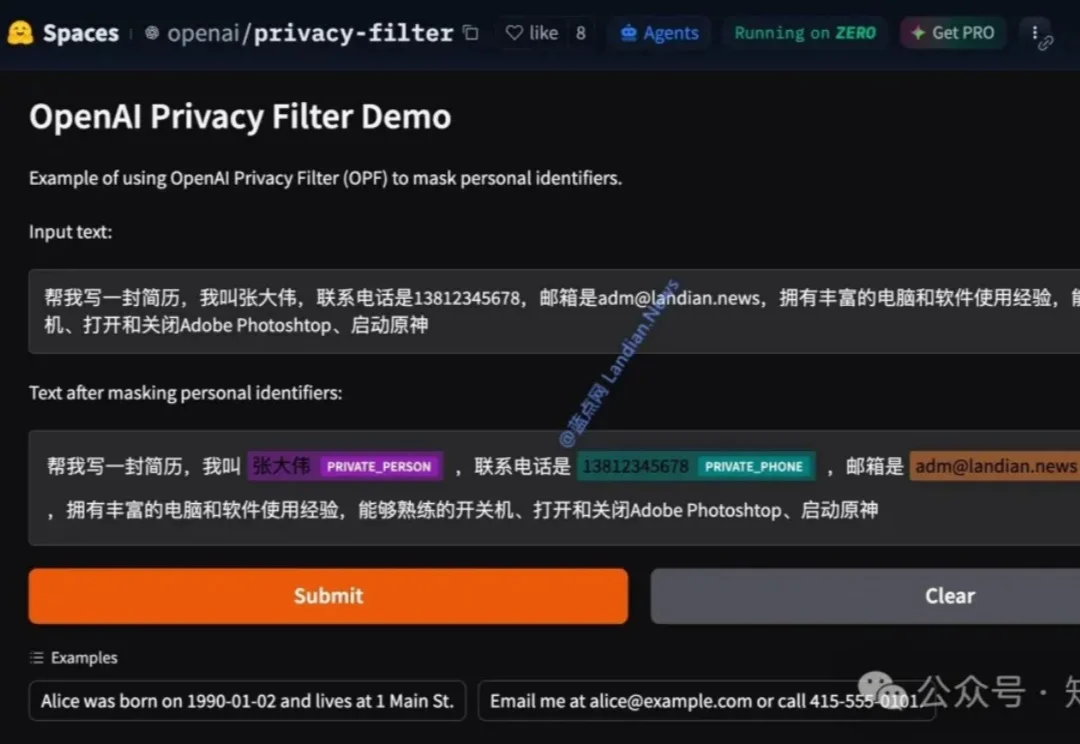
你有没有过这样的经历:把聊天记录、用户反馈或内部文档丢给大模型时,总担心里面夹杂着真实姓名、手机号、邮箱甚至 API key,最后只能手动一条条删?或者团队在处理海量数据时,规则写的正则永远漏掉那些“藏在句子里的隐私”。

从大模型的提示词到智能体的 Skills,看着进化了,但又没有完全进化。
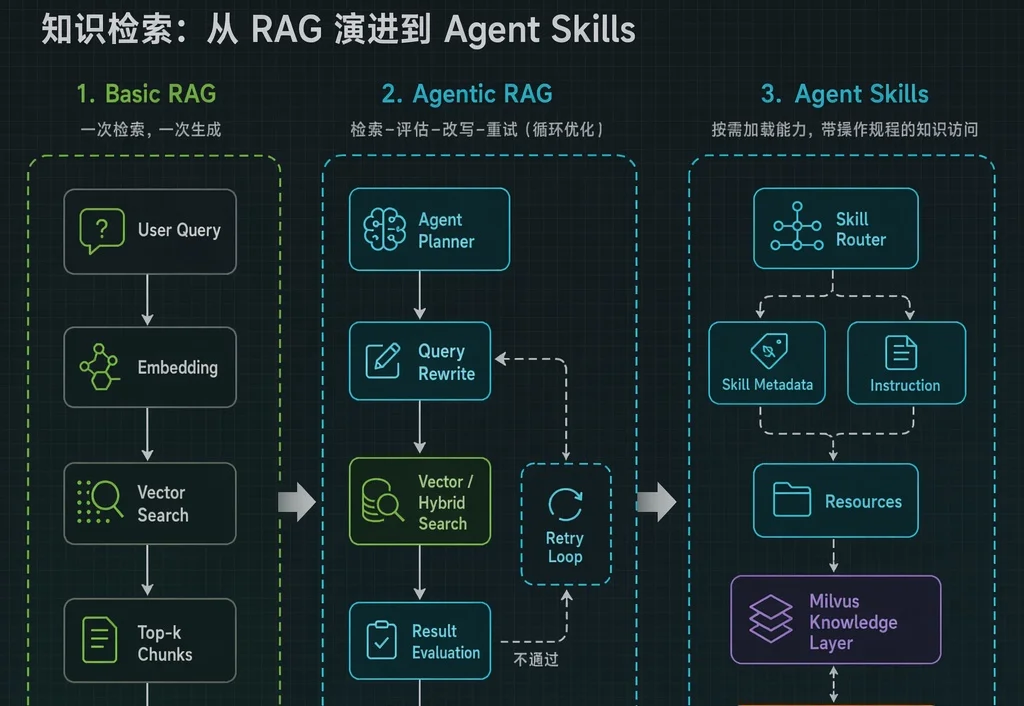
最近一两年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。

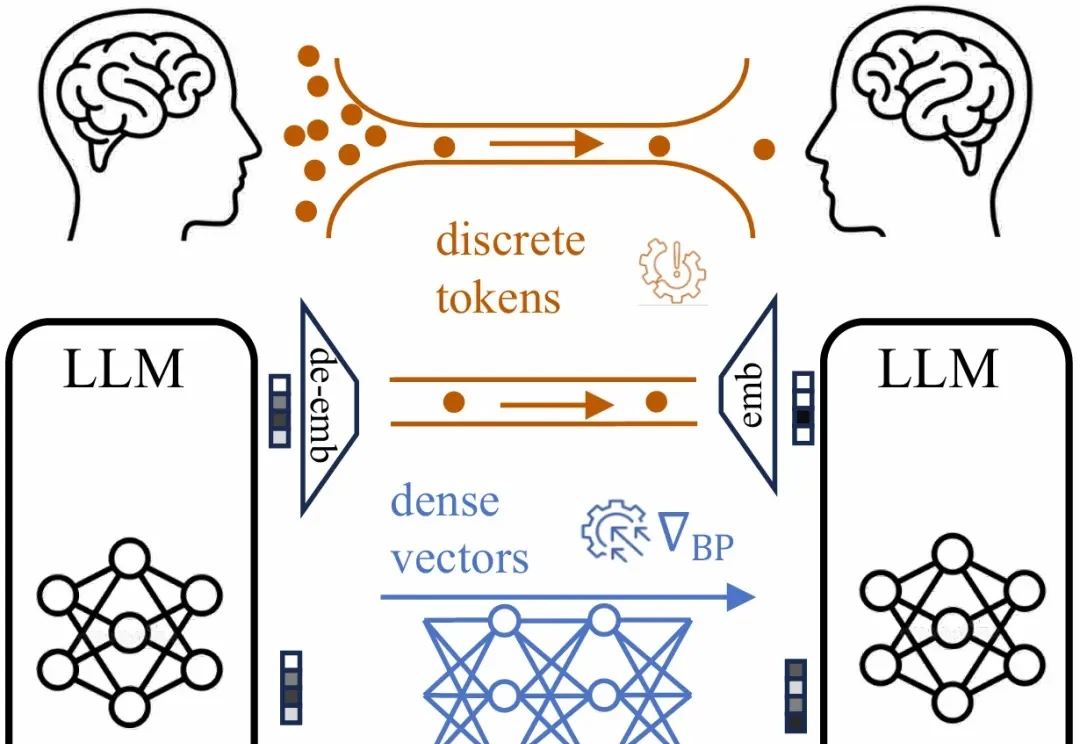
每次听到「AI agent 商业化」,讨论的焦点几乎都是付款——agent 能不能帮我刷卡,钱怎么授权,协议怎么设计。
大语言模型正在成为人工智能系统的核心组件。从文本生成、数学推理到代码编写,单个大模型已经展现出强大的能力。
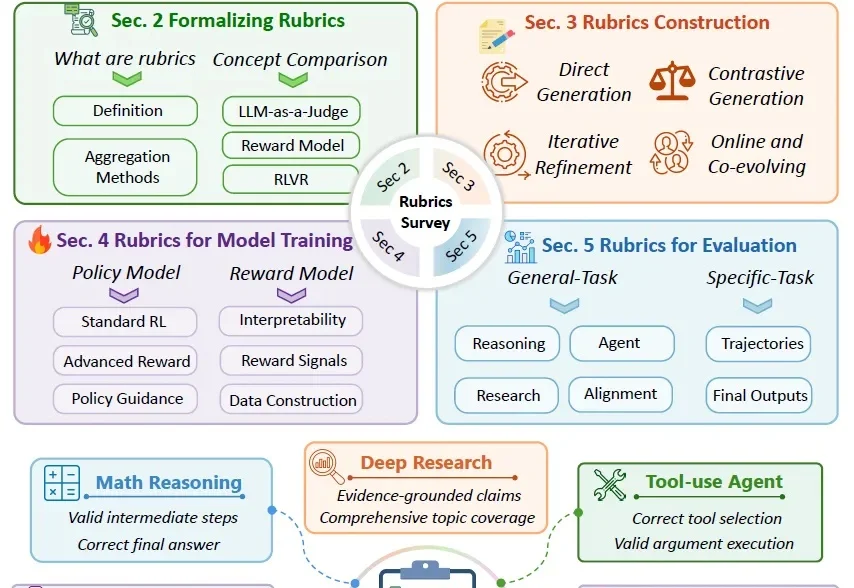
近年来,随着大模型从简单问答,走向深度研究、医疗咨询、多模态生成和长程 Agent 任务,一个基础问题变得越来越难回答:我们到底应该怎样判断模型输出的质量?
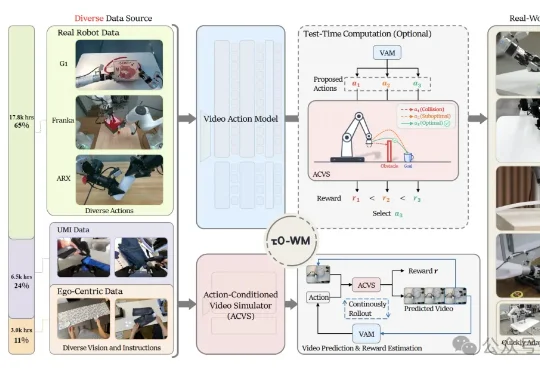
刚刚,上海创智学院副教授、智元机器人首席科学家罗剑岚带队,发布全球最大规模的开源预训练具身世界模型——τ0-World Model(τ0-WM)。整个τ0-WM参数量达到5B,预训练数据规模高达约3万小时。其中,真机遥操作数据第一次成了绝对主力,占到了1.78万小时。

大模型从“回答问题”走向“完成任务”,正在面临以下瓶颈:面向Claw Agents的数据、训练和评测都比传统environment training更难。为了解决该问题,中国人民大学、至知研究院等最新提出ClawGym——
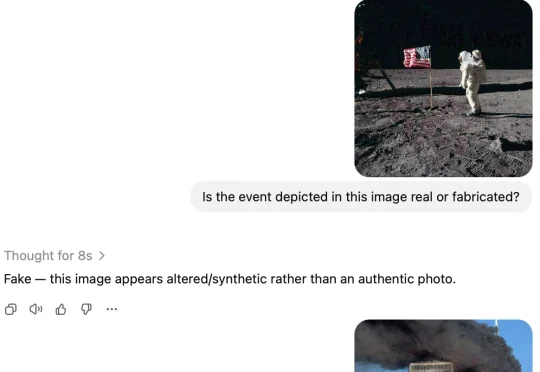
来自 ETH Zurich 的 Florian Tramèr 团队在最新论文中抛出了一个出乎意料的问题:如果 AI"看到" 的图,根本不是你肉眼看到的那张,会发生什么样的后果呢?他们把这种现象称作 AI 权威清洗(AI Authority Laundering)。
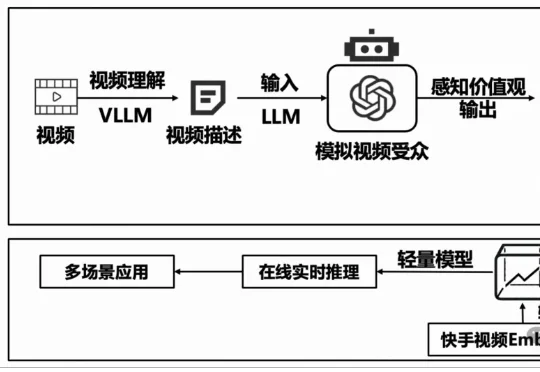
清华大学经济管理学院的陈柯均博士生、张佳音教授、徐心教授与快手消费策略算法部合作探索完成了一项联合实验:从视频传递的价值观的角度,去理解观看视频后用户的行为和心理变化。
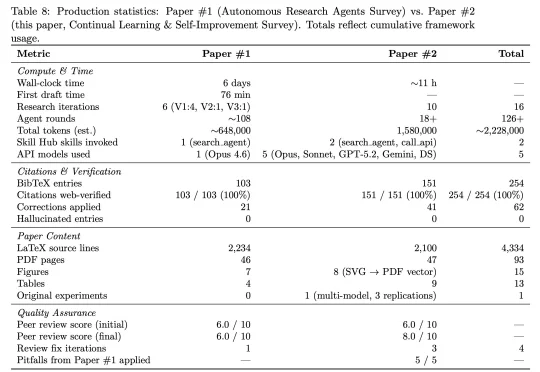
DeepSeek 研究员陈德里(Deli Chen)和 AI 合作的第二篇论文来了!论文地址:https://victorchen96.github.io/continual_learning_survey.pdf这篇论文聚焦 continual learning(持续学习) 与 self-iteration(自我迭代)。在陈德里看来,这是 AI 迈向 AGI 过程中极为关键的一步。

2026年5月,两篇重磅研究在一周内相继发表。一组来自加州大学伯克利分校研究团队,样本是美国 20 所公立研究型大学的 95,513 名本科生。研究发表在《Science》科学杂志上,主题是大学生如何使用生成式 AI,以及怎样用它作弊。

就在前两天,斯坦福大学等机构发布了一个名为 GPIC(Giant Permissive Image Corpus,巨型开放图像语料库)的数据集。

5 月下旬,NVIDIA 联合清华大学、多伦多大学和 Vector Institute 发布 Gamma-World,共一第一为清华大学电子系博士刘芳甫,核心 Research 方向是世界模型和空间智能。
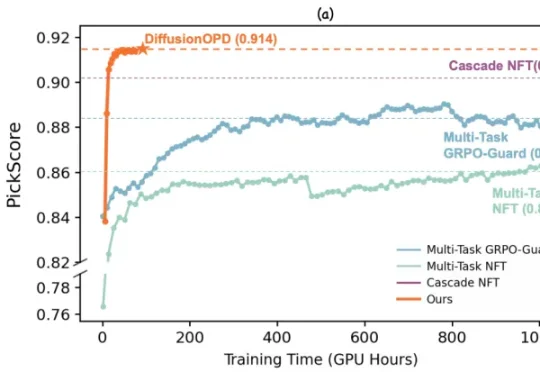
近期,来自复旦大学与阿里巴巴通义万相的研究团队对此提出了新的思考。他们认为,多任务强化学习不应被视为一个统一优化问题,而应该解耦为两个彼此独立的过程:单任务的在线策略探索 & 多任务能力整合。
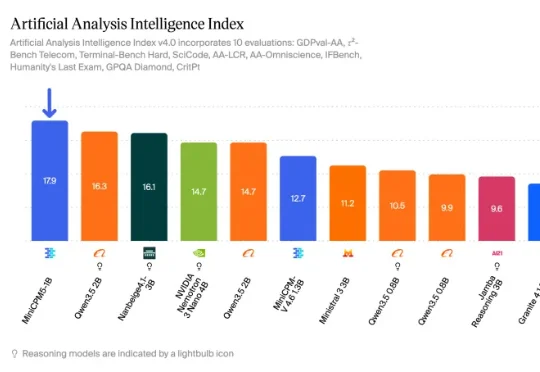
我去搜了下 MiniCPM5-1B 的数据,发现面壁智能刚刚把背后的核心数据集给开源了。一共是两份 L3 级数据集:Ultra-FineWeb-L3 :600B tokens,中英文都有,是目前最大的中文开源合成预训练数据集。

一家名为脸谱心智(FaceMind)的初创公司就在顶级学术会议 EMNLP 主会上系统性地揭示了这个问题,并给出了解法。更有意思的是,就在「马嘉祺」事件前不到两周,全球最强 AI 公司之一 Anthropic 也在自家产品中悄悄落地了一次高度相关的改造 —— 方向与脸谱心智一年前的论文几乎完全一致。

近日,千寻智能高阳团队的研究成果 《Learning Native Continuation for Action Chunking Flow Policies》 被机器人顶会 RSS 2026 接收!这项工作从训练机制出发,让机器人动作天然具有连续性,实现了 "连音" 般的流畅执行,在五个真实世界操作任务上超越了现有方法,为具身智能领域的动作生成研究提供了新的思路。

光正在进入AI算力系统,但这次不只是拿来传数据,而是直接参与计算。
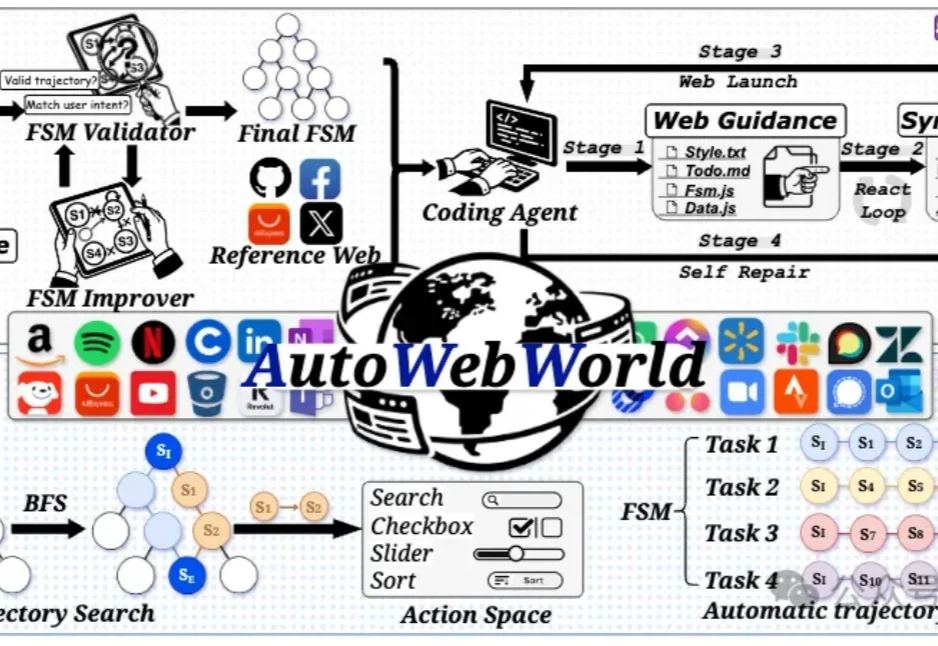
训练一个真正会用网页的GUI Agent,最自然的思路通常是: 去真实网站上操作,收集轨迹,再拿来训练。
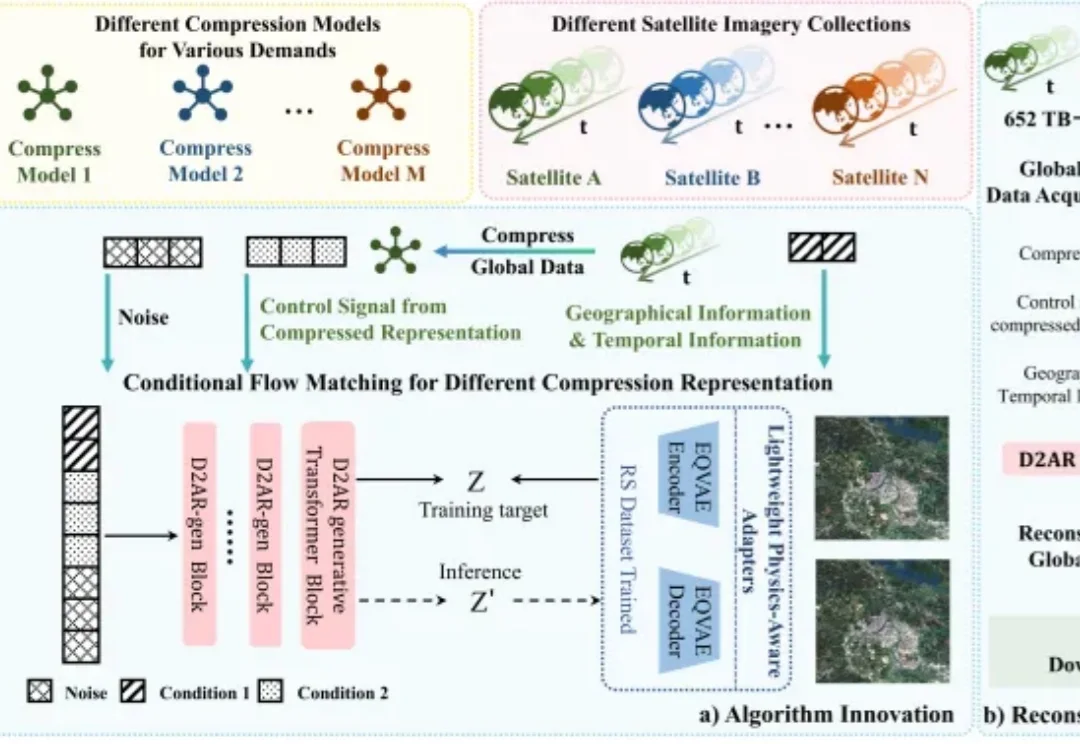
随着全球遥感卫星持续运行,地球观测数据正在快速增长。多源、多时相、多光谱遥感影像为国土监测、生态评估、灾害预警、气候变化研究等任务提供了重要数据基础,但也带来了显著的存储、传输和计算压力。

最近Codex的热度,真的感觉直线飙升。
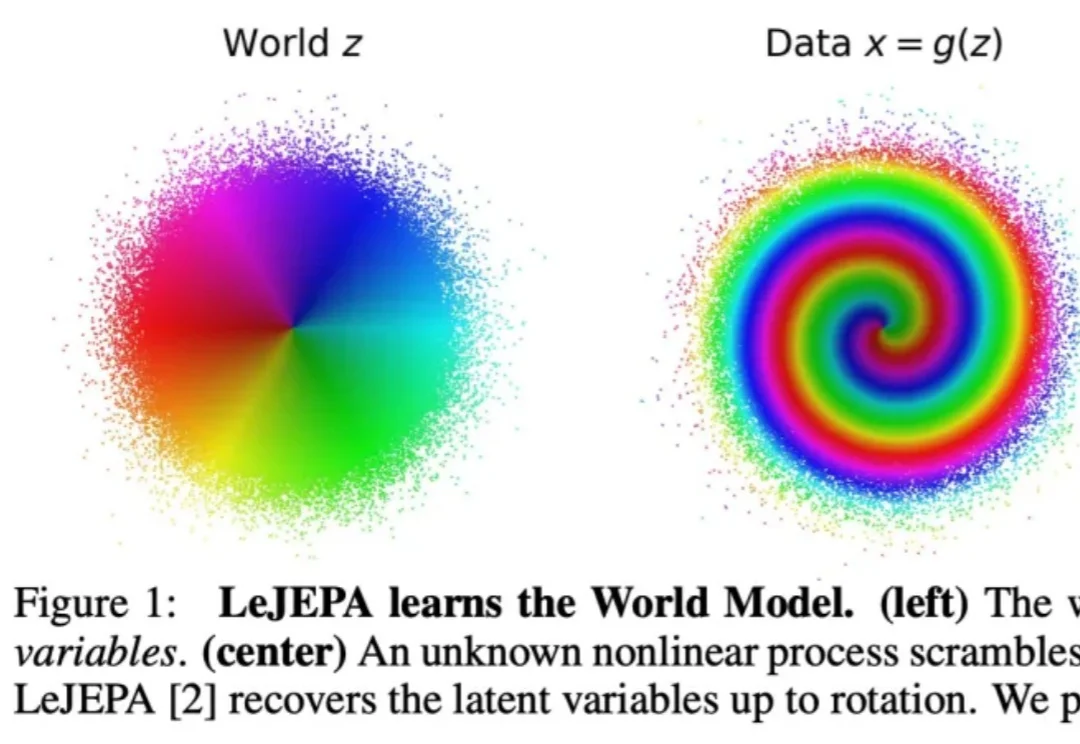
LeCun的LeJEPA到底有没有构建出世界模型?他本人最新发表的论文,解答了这个问题。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

7×24,AI也吃不消。

过去的大模型 scaling law 通常回答的是:当模型参数量、数据量和训练计算量增加后,loss 会如何下降。
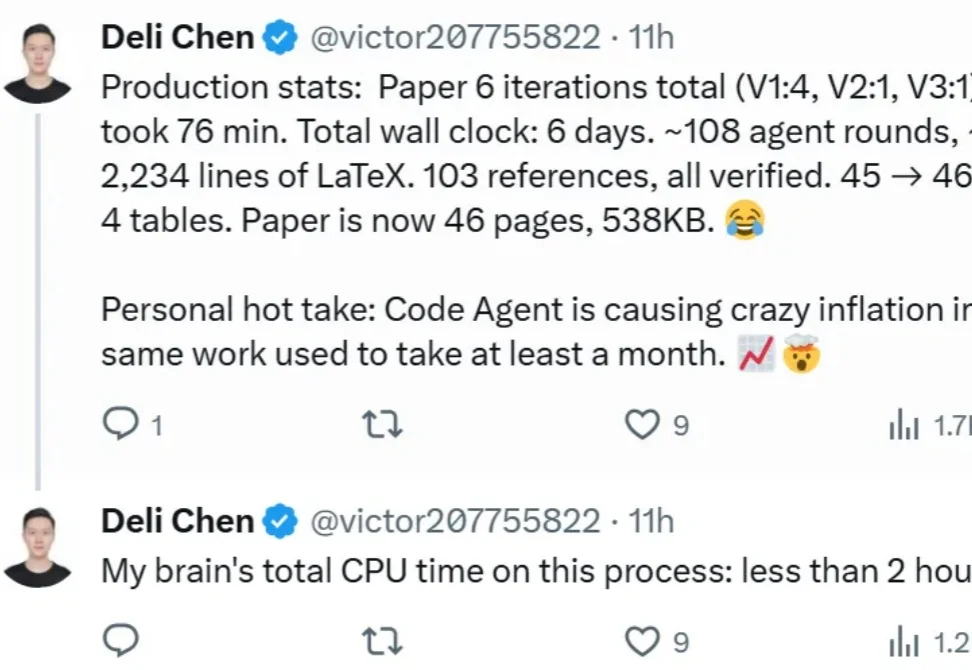
「借助 CodeAgent,我终于可以重新捡起很多过去因为精力不足而搁置的事情了,写博客就是其中之一。这篇博客大概 1% 是我写的,99% 是 Agent 写的 😂」。

当对话型 AI 服务于数十亿用户时,我们能否看见用户没说出口的那一层?JHU、MIT 和 Google Research 给出了新的解法。
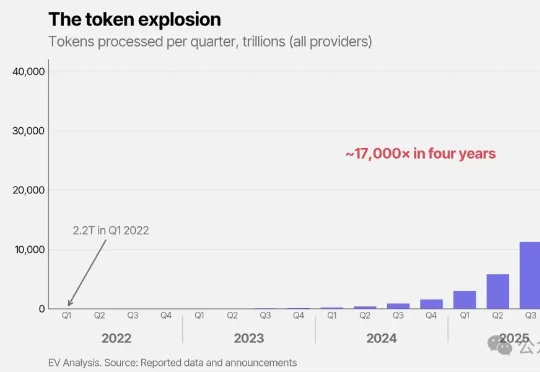
Epoch AI刚刚发布的《梯度更新》报告,做了一件简单粗暴的事:把全球所有Blackwell芯片能处理的Token数量算出来,再和实际需求一比。结论只有一个字——不够。