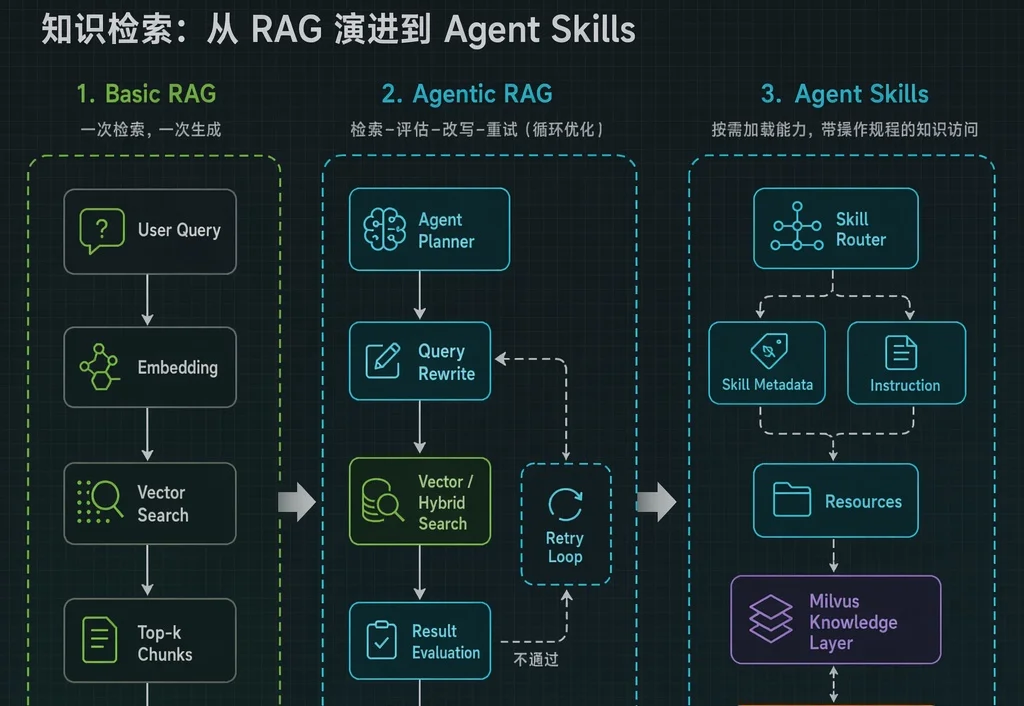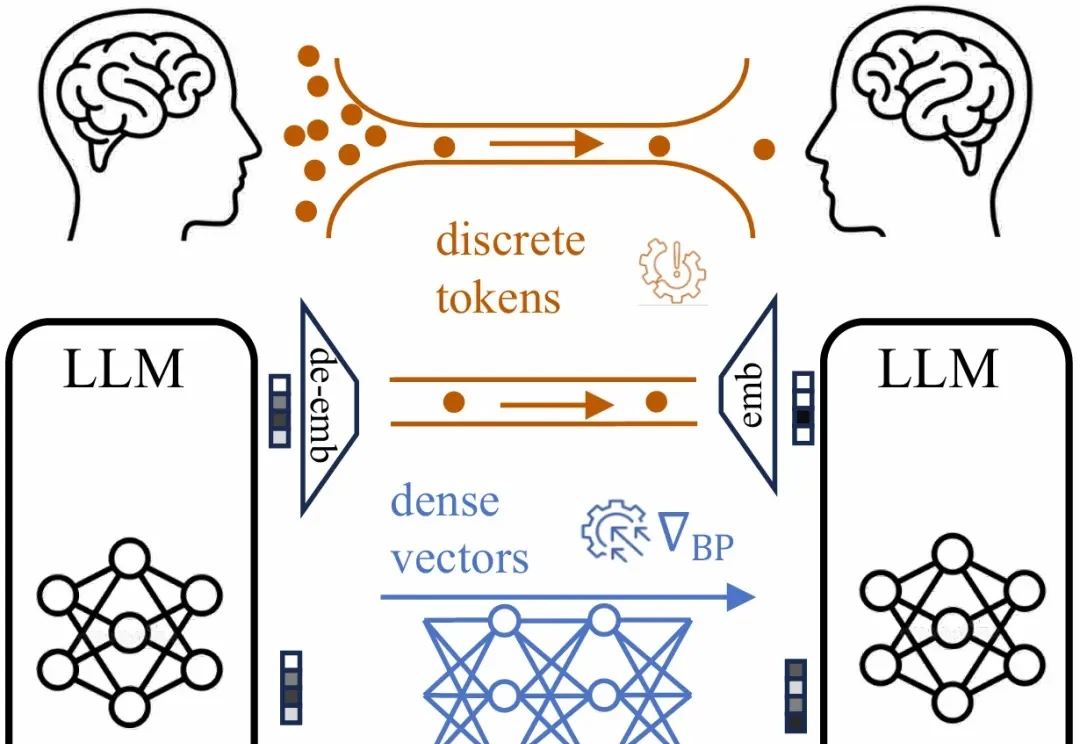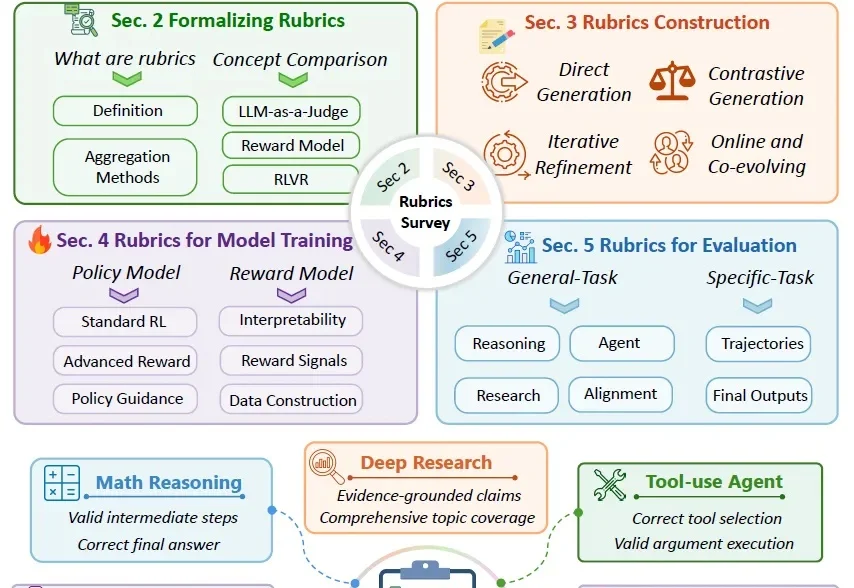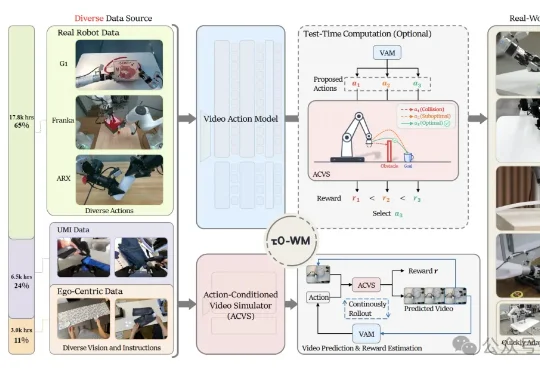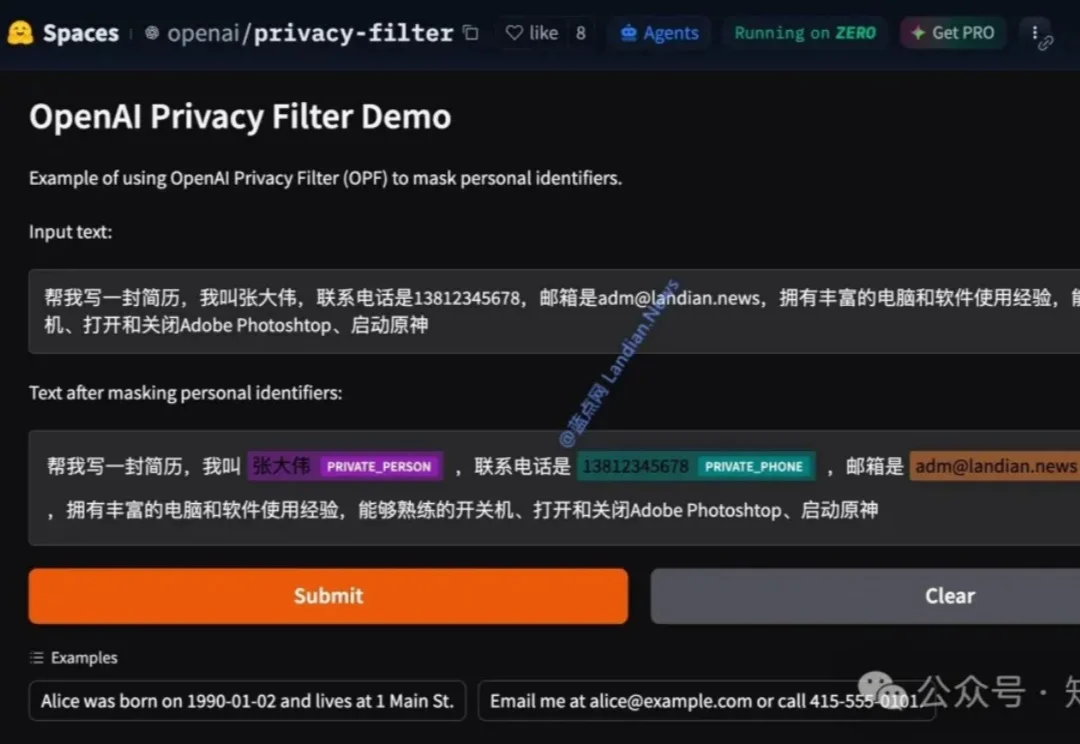
OpenAI 刚开源了一个 1.5B 参数的隐私过滤模型,却只用 50M 活跃参数就能精准标记姓名、电话、密码这些敏感信息。
OpenAI 刚开源了一个 1.5B 参数的隐私过滤模型,却只用 50M 活跃参数就能精准标记姓名、电话、密码这些敏感信息。你有没有过这样的经历:把聊天记录、用户反馈或内部文档丢给大模型时,总担心里面夹杂着真实姓名、手机号、邮箱甚至 API key,最后只能手动一条条删?或者团队在处理海量数据时,规则写的正则永远漏掉那些“藏在句子里的隐私”。
来自主题: AI技术研报
9760 点击 2026-06-01 10:29