
从0到1带你速通Codex,我整理的终极保姆教程来了。
从0到1带你速通Codex,我整理的终极保姆教程来了。最近Codex的热度,真的感觉直线飙升。
来自主题: AI技术研报
11592 点击 2026-05-29 09:38
 搜索
搜索
最近Codex的热度,真的感觉直线飙升。
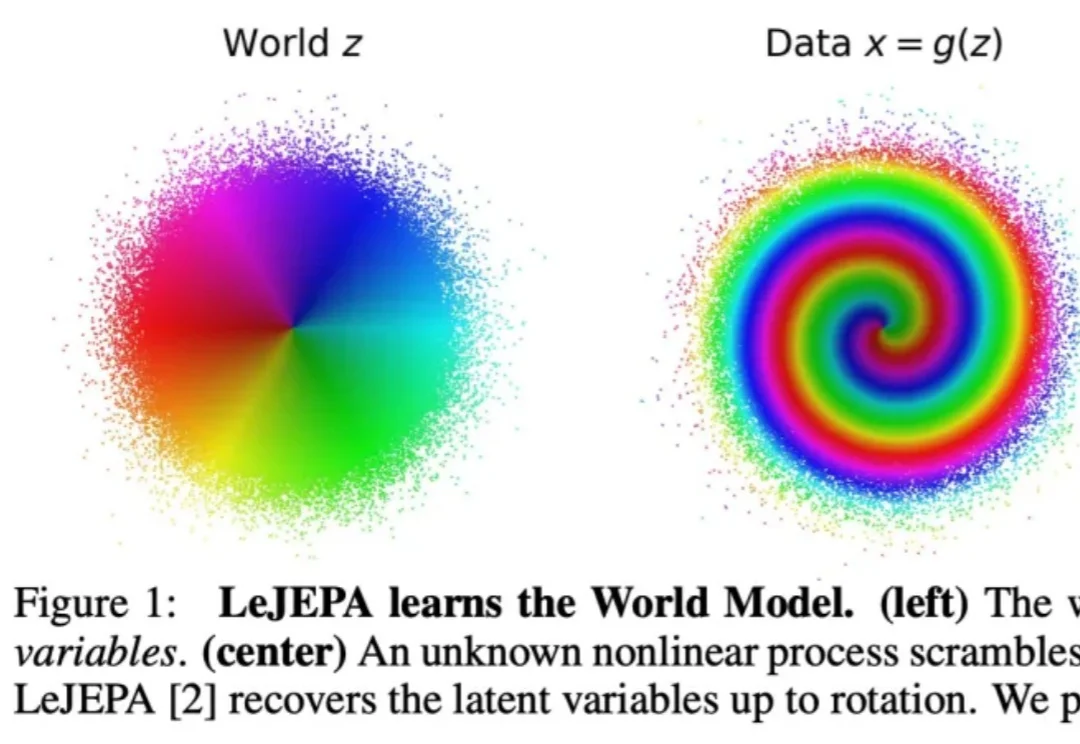
LeCun的LeJEPA到底有没有构建出世界模型?他本人最新发表的论文,解答了这个问题。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

7×24,AI也吃不消。

过去的大模型 scaling law 通常回答的是:当模型参数量、数据量和训练计算量增加后,loss 会如何下降。
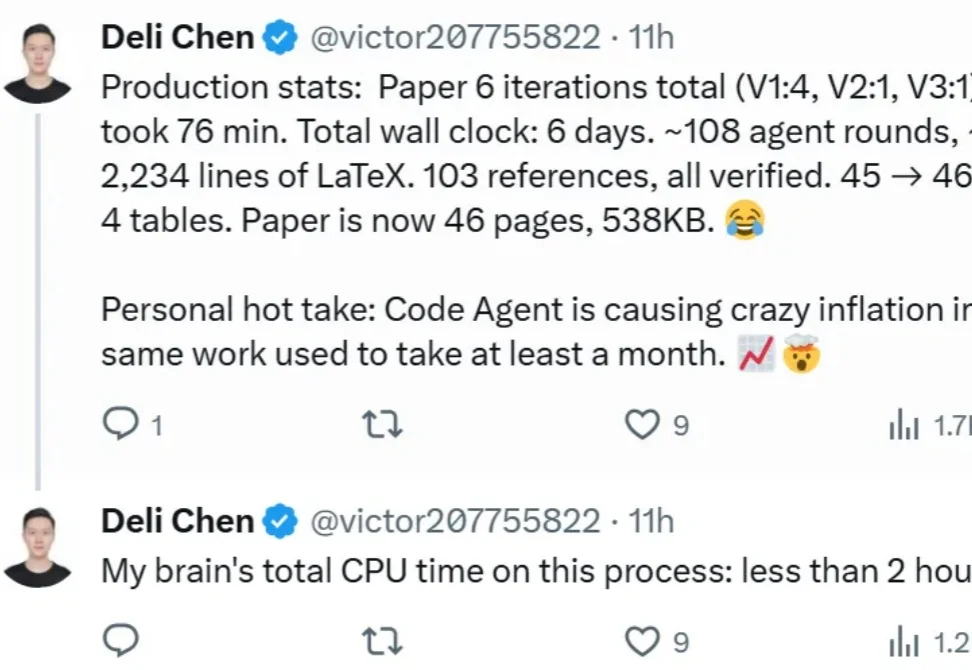
「借助 CodeAgent,我终于可以重新捡起很多过去因为精力不足而搁置的事情了,写博客就是其中之一。这篇博客大概 1% 是我写的,99% 是 Agent 写的 😂」。

当对话型 AI 服务于数十亿用户时,我们能否看见用户没说出口的那一层?JHU、MIT 和 Google Research 给出了新的解法。
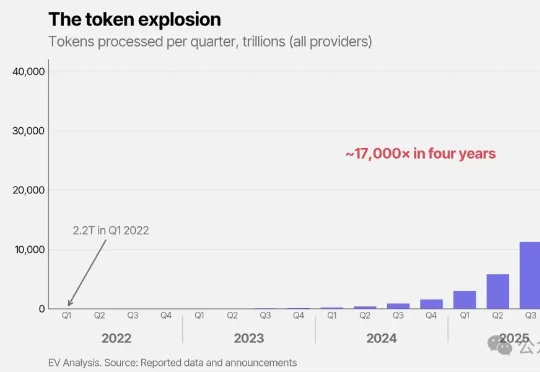
Epoch AI刚刚发布的《梯度更新》报告,做了一件简单粗暴的事:把全球所有Blackwell芯片能处理的Token数量算出来,再和实际需求一比。结论只有一个字——不够。

近期,深圳河套学院(SLAI)AI训练平台项目团队,联合哈尔滨工业大学(深圳)、深圳大数据研究院、华为GTS(全球技术服务)团队与深智城AI算力平台,仅用1个月,共同基于昇腾910C国产算力集群实现DeepSeek-V4-Pro全参数续训练/SFT稳定运行,完成长稳训练1500+步,训练MFU超30%,关键训练算子效率提升14%。
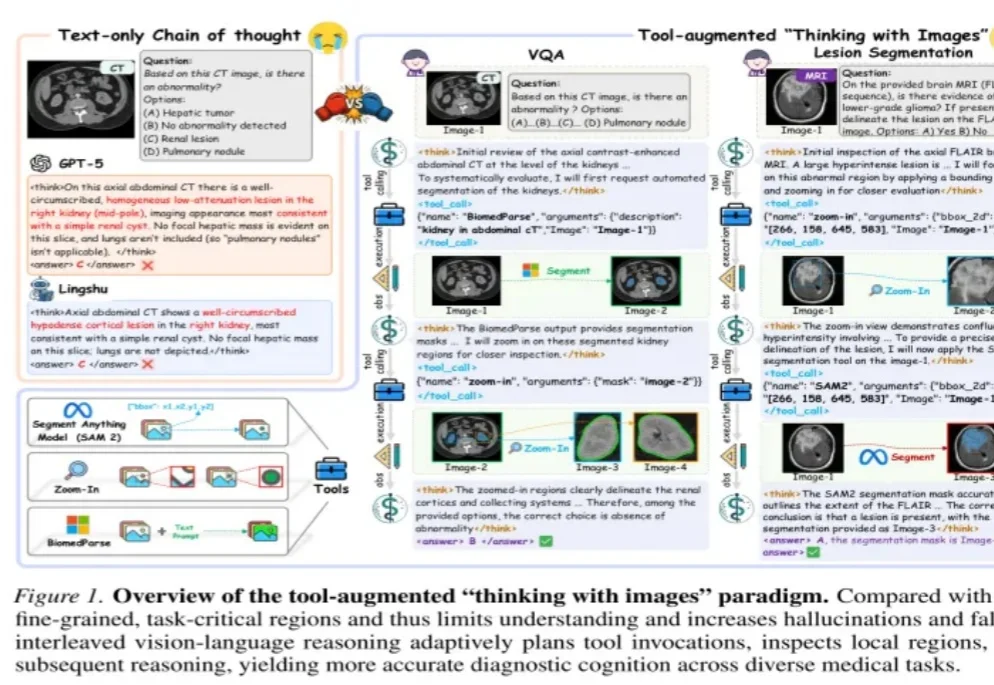
医学AI会写解释,但不代表它真的“看到”了关键证据。

从数学、代码、复杂推理,到多轮工具调用,大模型的很多能力的提升都离不开 RL 后训练。但当模型规模进入 MoE 万亿参数级别之后,RL 不再只是一个算法问题,同时更加是一个系统问题。
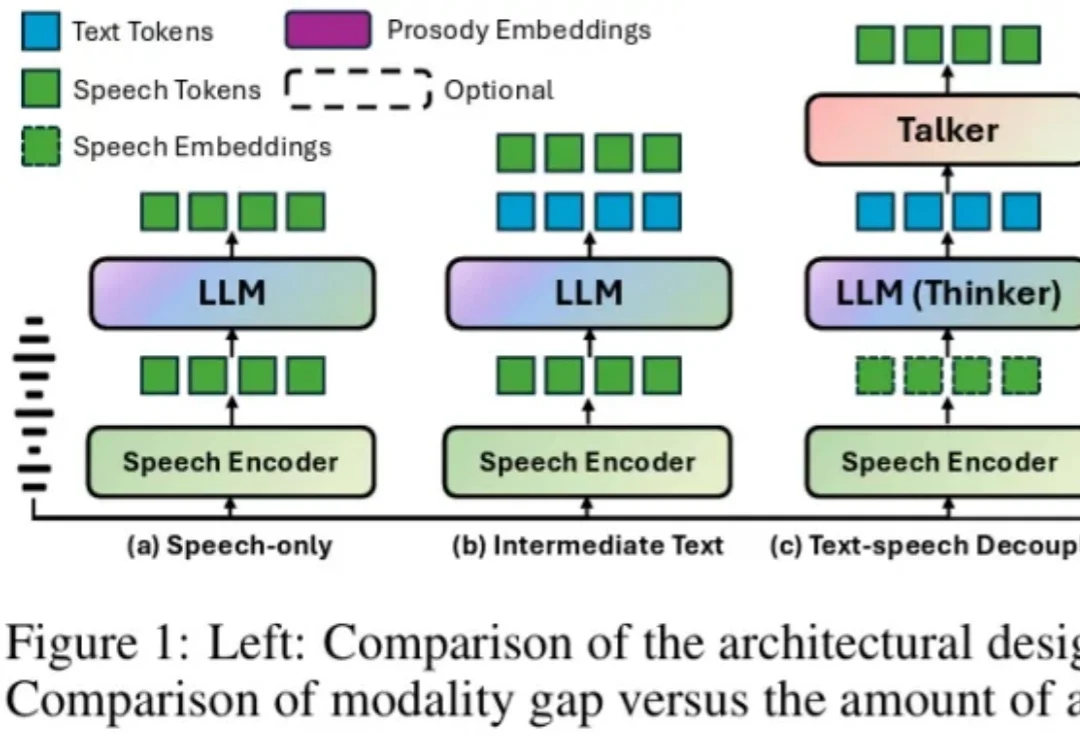
相信大家都有过这样的体验:同一个系列的模型,使用文本交互的时候,模型就像开启了 “最强大脑”,数学代码等各种复杂推理任务样样精通,可是一旦将其改造成语音对话模型之后,性能就猛烈下降,严重 “降智”,经常会犯很多基本的逻辑错误。

当下视频生成模型正在快速逼近真实世界的画面质感,但一个现实瓶颈也越来越突出—— 那就是分辨率越高,生成所需要的时间就越长。
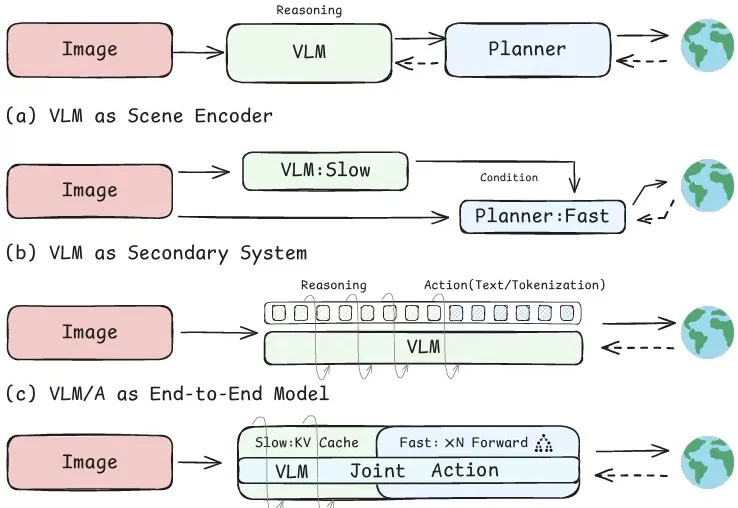
大模型进入自动驾驶后,最直接的价值在于场景理解。它可以识别前车是否准备并线、行人是否可能横穿、施工区域是否会影响车道,也可以分析复杂路口中的让行关系。

Gemini 3.5的闯祸实录。

前段时间开源了 guizang-ppt-skill,之后我自己用它做内容的时候发现一件事。
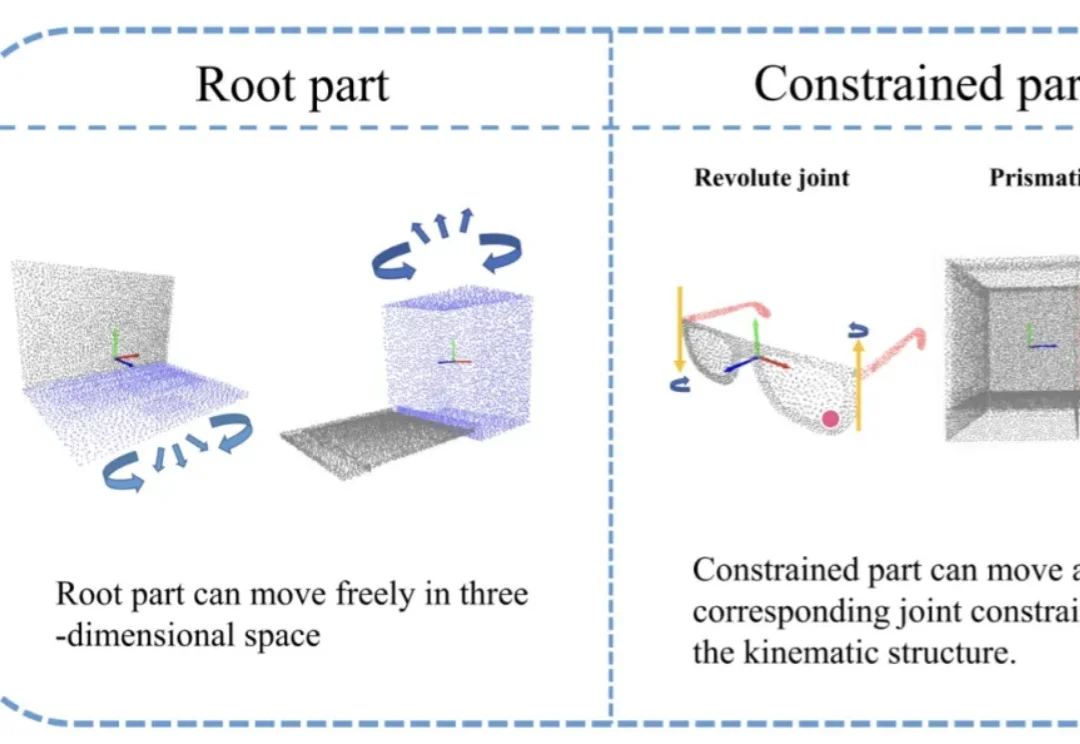
在具身智能快速发展的今天,机器人已经不再满足于「看见」刚体物体,而是开始真正走向复杂环境中的交互与操作。从机械臂开柜门,到服务机器人整理抽屉,再到工业场景中的工具操作,大量真实世界目标都属于关节物体(Articulated Objects)。
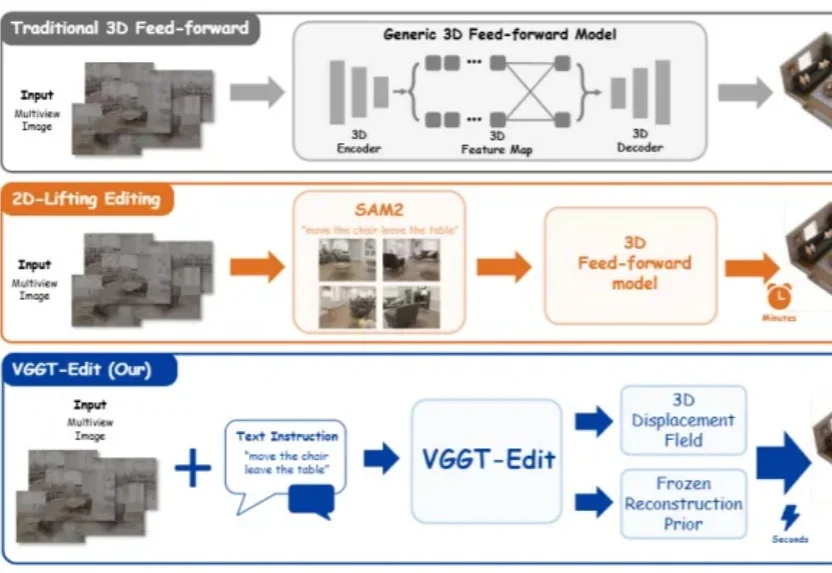
3D世界“会看”了,但还不会“改”。

你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。

就在几天前(5月22日),DeepSeek官方扔出了一枚重磅炸弹:DeepSeek-V4-Pro将在5月底结束优惠后,永久降价至原价的四分之一。各大媒体瞬间被诸如“白菜价”、“夯爆了”的标题刷屏。看看这组惊人的新定价:每百万Token输出6元,输入(缓存未命中)3元,而输入(缓存命中)仅仅只要0.025元!
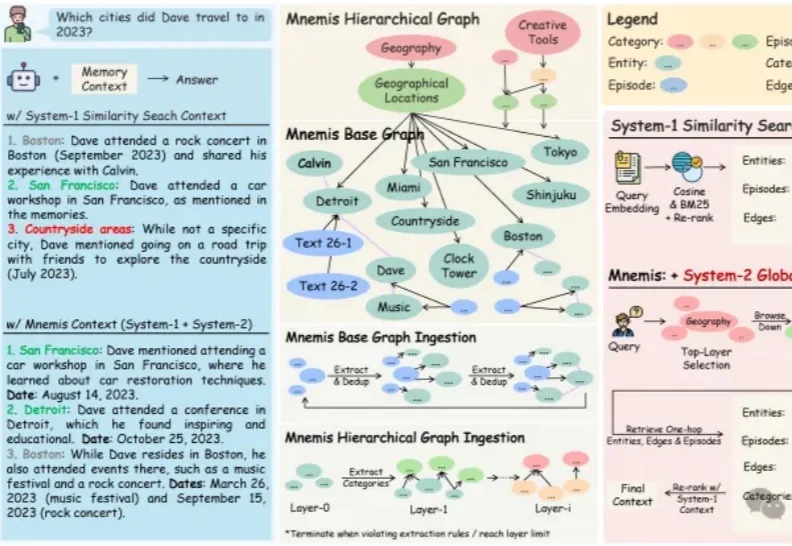
随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的RAG(检索增强生成)方案依赖语义相似度检索历史信息,但“语义相似”并不等于“真正相关”,常常出现检索结果不完整、无法区分信息相关性、缺乏推理能力等问题。

智能体时代,如何让视觉分割更准确?

在这些场景,一个集合也许一个月只被查询几次,运行时间不超过5小时,用户也并不需要为此投入向量数据库级别的资源建设,让高性能资源一个月时间里有715小时都被浪费。相应的,成本也就成了这一场景下的优先考量要素。而解决这一问题,也是我们选择在近期推出Vector Lakebase 产品的初心所在。

众所周知,大模型训练成本极高。
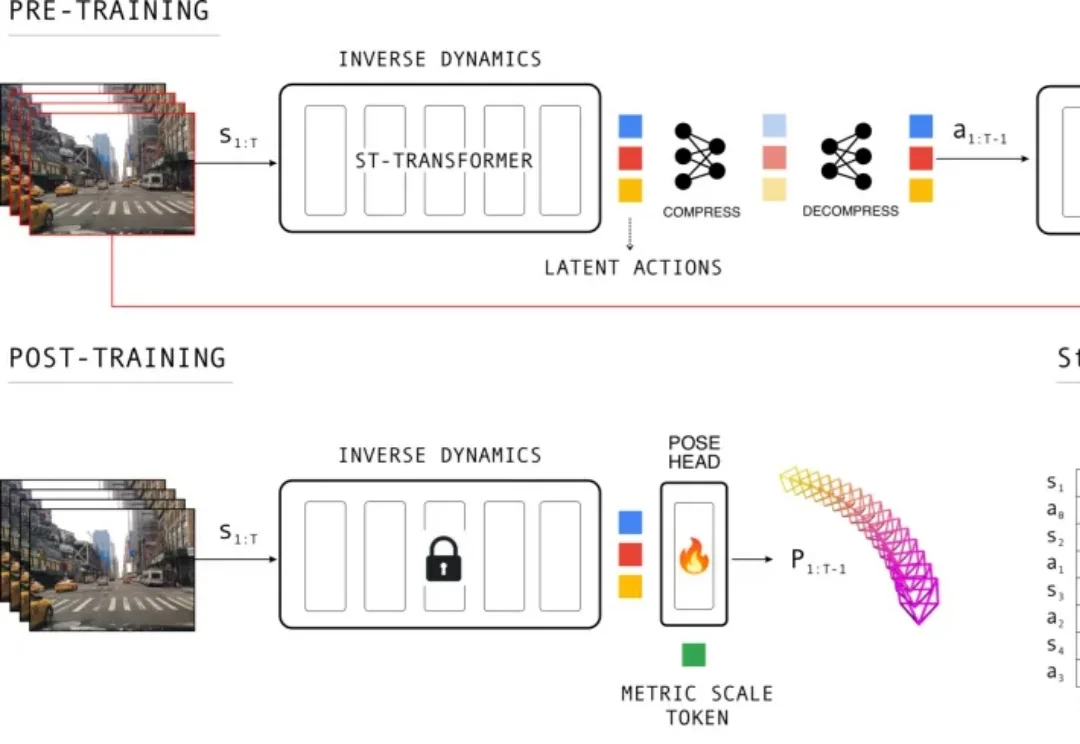
不用百万级 3D 标注,模型也能从普通驾驶视频中学会「自己是怎么动的」。Wayve 的 LA-Pose 试图把未标注视频里的运动信号,转化为自动驾驶系统所需的相机位姿估计能力。

过去几年,大模型竞争主要发生在 AI 公司之间。但随着 AI 开始从数字世界进入真实设备与物理世界,竞争逻辑正在发生变化。

一个纯Python写的开源项目,竟把OpenAI用Rust写的王牌给秒了!最终战绩6比5,Hermes直接上演工程暴力美学,解释型语言终于逆天改命。
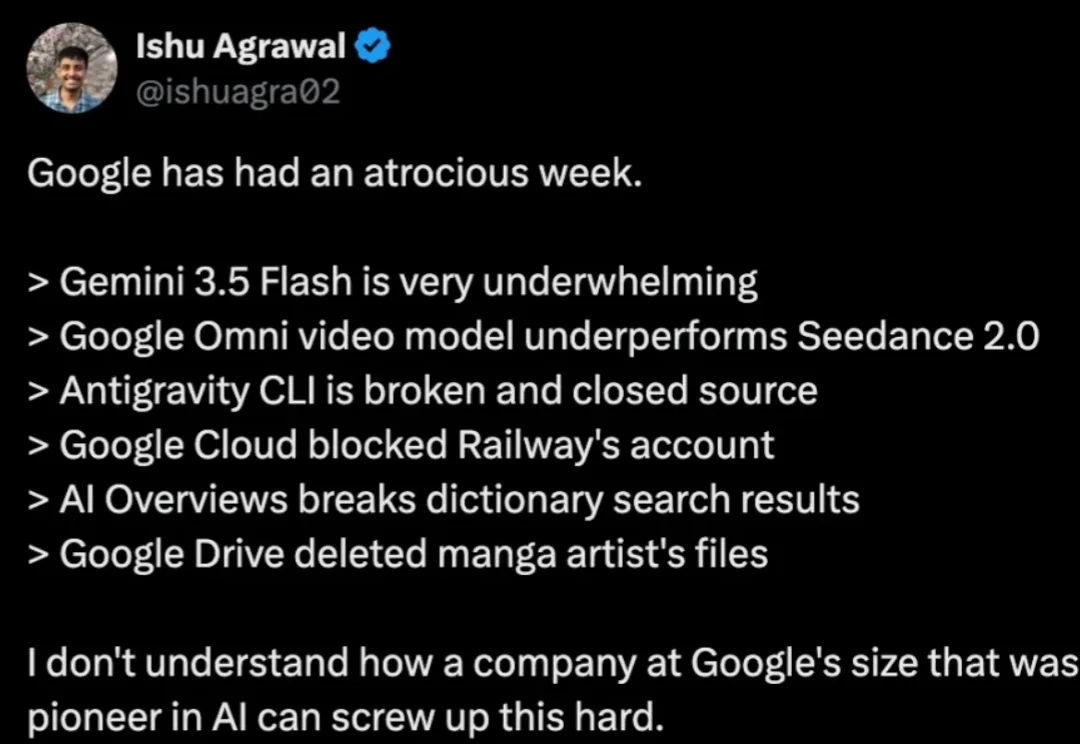
最近,谷歌的日子不太好过。
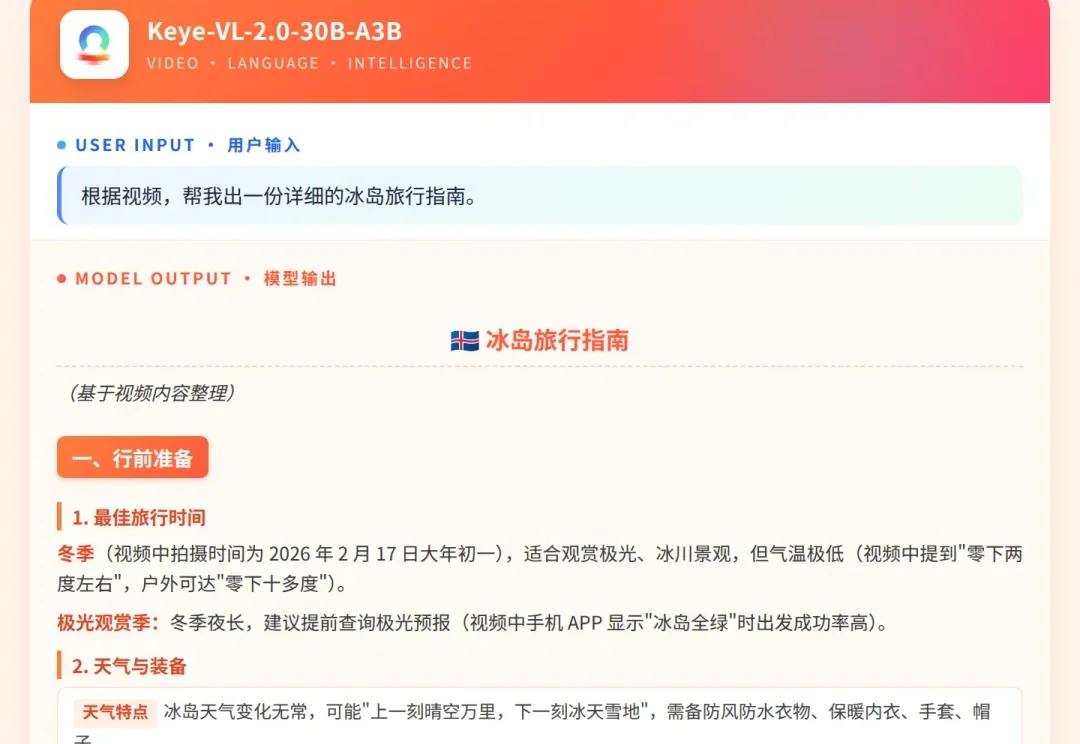
当你把一段长达9分钟、在“晴空万里”与“冰天雪地”间剧烈切换的冰岛旅行Vlog输入给大模型,并要求它做一份旅行攻略时,常规的视觉大模型通常只能给出一份基于字幕和画面标签拼凑的“流水账”。

Anatoli Kopadze 这条帖子 2200 万阅读,我一开始以为又是那种「10 个 AI 技巧改变你人生」的流量帖。点进去一看——还真有东西。17 个功能里大概有 5 个我压根不知道存在,还有 3 个我一直在用但用法完全是错的。