
0%完成率!Claude、GPT、Gemini 全灭,SWE-Bench作者新作把AI圈干沉默了
0%完成率!Claude、GPT、Gemini 全灭,SWE-Bench作者新作把AI圈干沉默了SWE-Bench 的创建者,刚刚又放出了一个地狱级新 benchmark。
来自主题: AI技术研报
11954 点击 2026-05-07 15:31
 搜索
搜索
SWE-Bench 的创建者,刚刚又放出了一个地狱级新 benchmark。

UniGeo通过视频模型的连续视角先验与统一几何引导,实现稳定、高质量的相机可控图像生成,全面超越现有方法,在不同幅度的相机运动中提升跨视角一致性与结构稳定性。
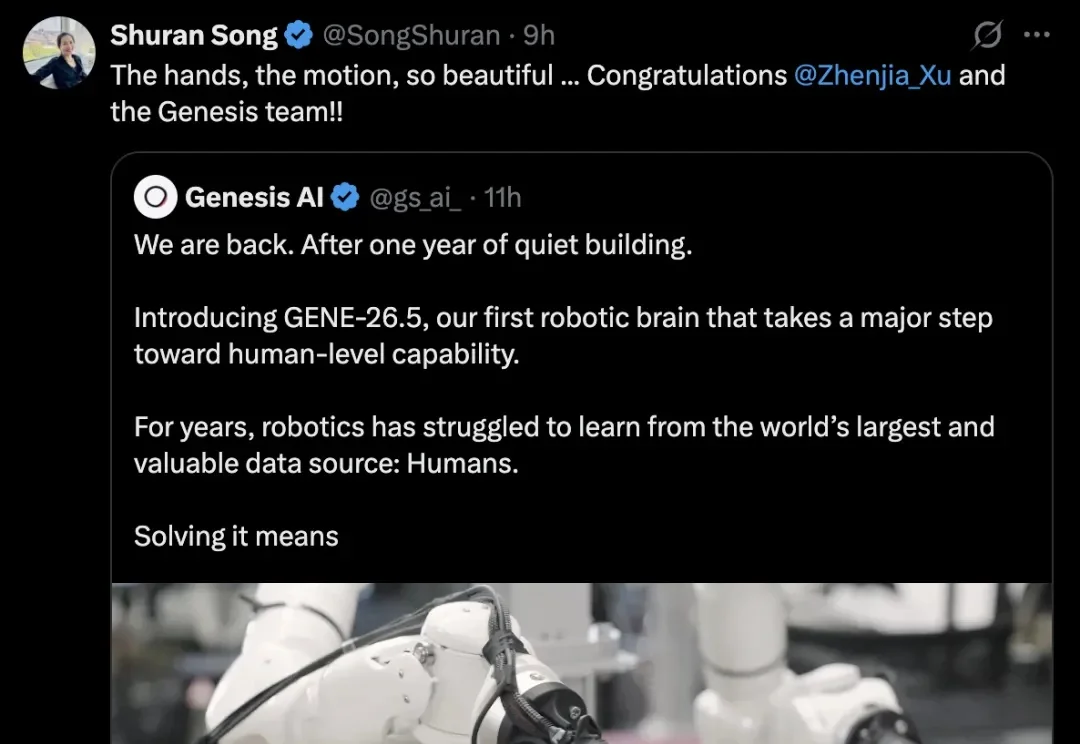
看过的人已经傻眼了,因为这可能是今年为止最炸的机器人demo。
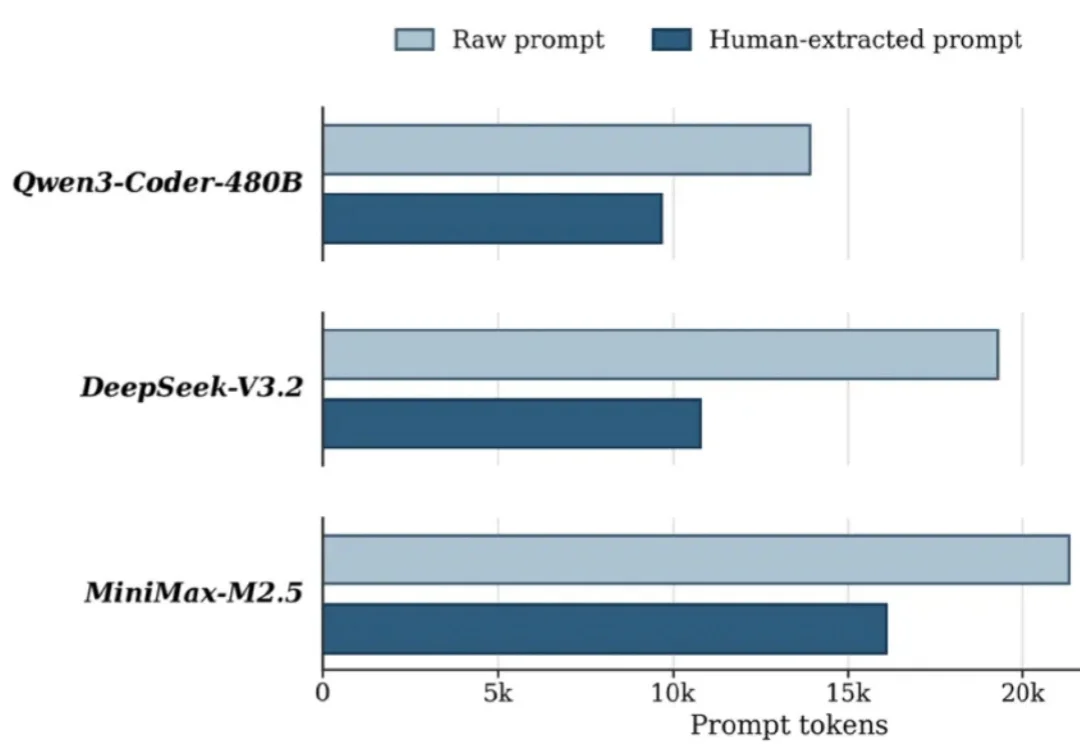
随着代码智能从 code foundation models 走向 autonomous coding agents,CLI/terminal 正在成为智能体进入真实软件工程工作流的重要入口。

在代码大模型和代码智能体技术快速发展的今天,一个日益凸显的现象是:能够在经典代码生成基准上取得优异成绩的模型,一旦被放入真实软件工程环境中,表现却往往大幅下滑。

别人做AI中训练都在堆语料、补知识。

SWE-Bench上能拿72%的模型,换张考卷直接归零!Meta联合斯坦福、哈佛放出ProgramBench,200个项目从零手写,9大顶级模型完整通过率0%。最强的Claude Opus 4.7平均通过率也才51.2%。更离谱的是一联网,就有模型在36%的任务里跑去GitHub扒源码。
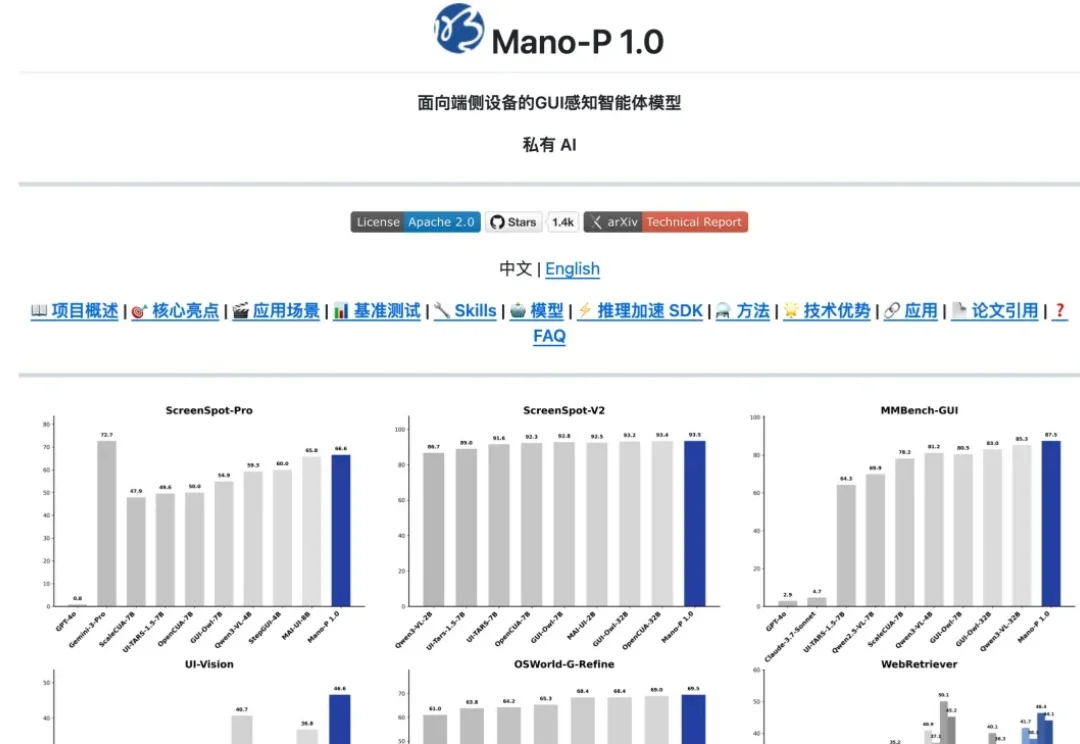
上次给大家分享了一个 CUA 的开源项目,能让 AI Agent 直接操控电脑界面,相当于把任何 App 都变成 Agent 的 Skill。反响还不错。
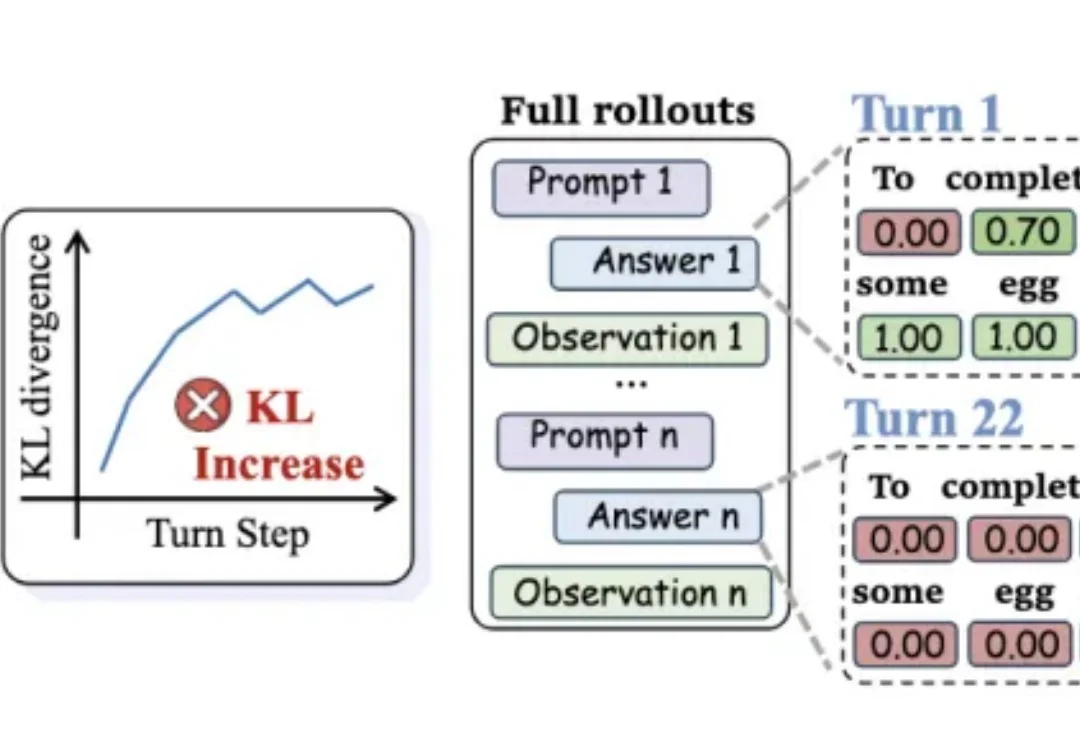
把强大模型的能力“蒸馏”给小模型,听起来很美—— 但放到多轮对话Agent场景里,效果往往一塌糊涂。

Agent Skills不应该只以SKILL.md、README或自然语言说明文档的形式存在,而应该被转成一种机器可检索、可检查、可治理的结构化表示。这是《From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills》这篇论文的核心主张。

当Agent开始真正进入生产环境,安全问题不再是「功能模块」,而是贯穿调用链、运行时与生态层的系统性风险。过去依赖提示词规则、日志审计与框架级防护的方式,正在逐步失效。来自清华大学人工智能学院、交叉信息研究院的方寸跃迁提出一套面向Agent运行全生命周期的多层安全体系。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

2026 年 3 月底,Ollama 发布了一则更新公告:其 Mac 版本的底层推理引擎,将从沿用多年的 llama.cpp 切换为苹果的 MLX 框架。
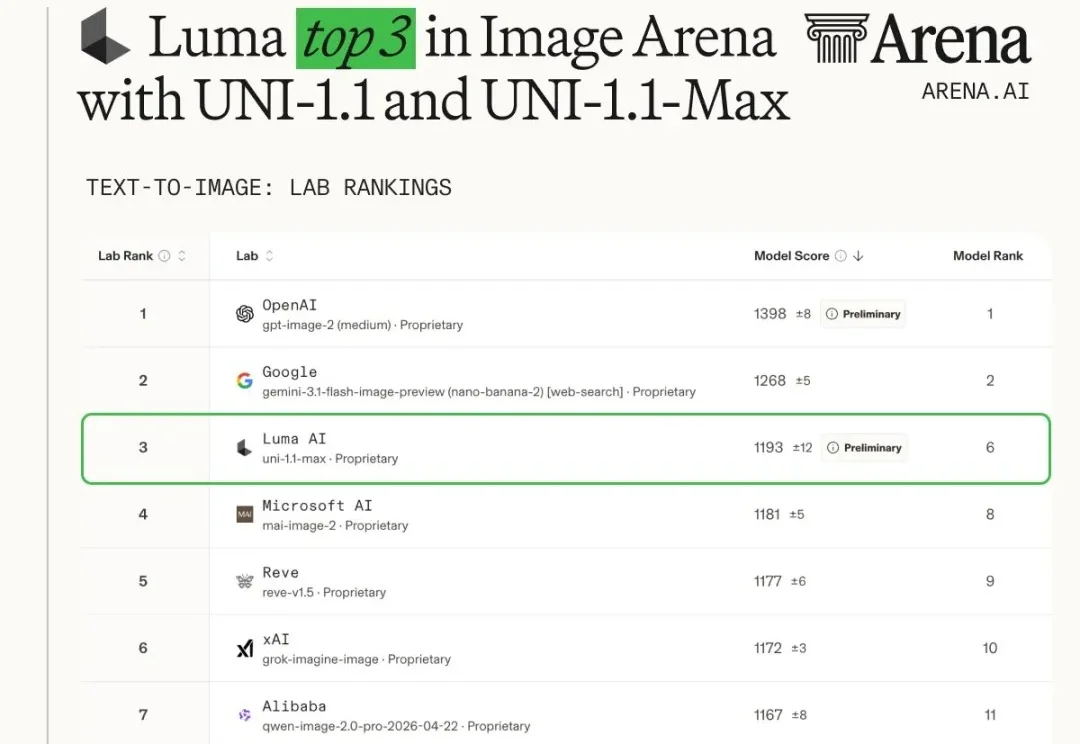
今年以来,图像生成模型的迭代节奏明显加快。

你有没有想过,为什么 AI 读一篇短文游刃有余,却在面对一整个代码库时频频出错?
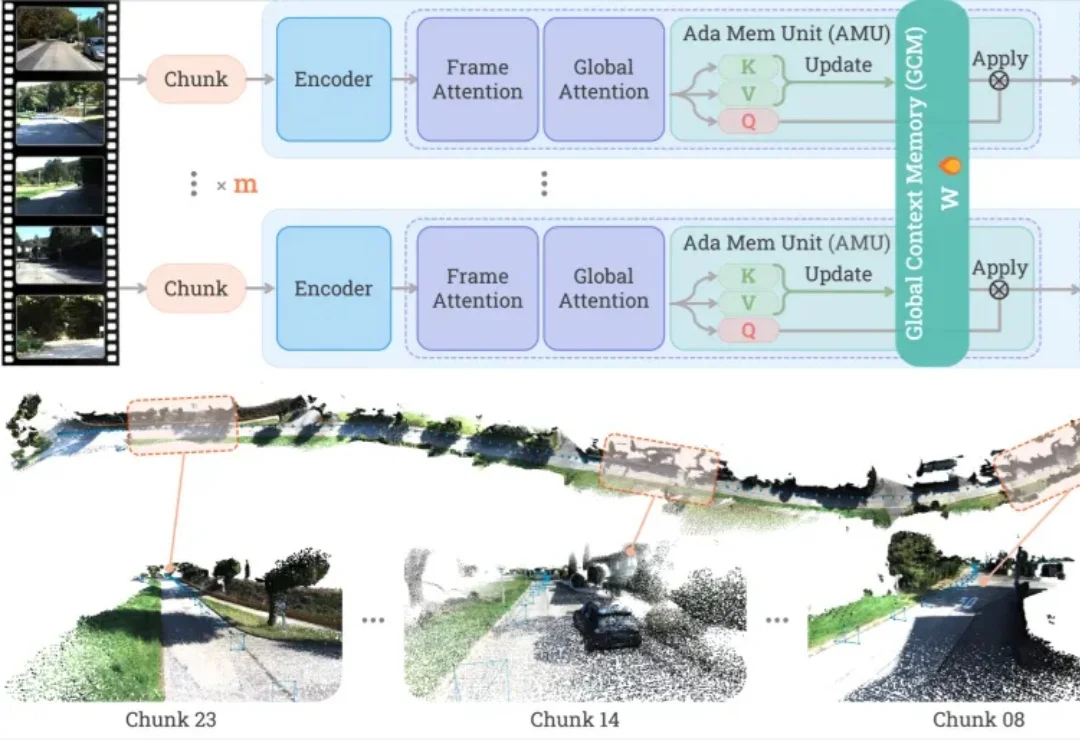
长视频 3D 重建最怕的,其实不是 "看不清"。
感谢鲸鱼兄弟开源。

用强化学习(RL)优化文生图模型的 prompt following 能力,是一条被广泛验证的路径 —— 让模型根据 prompt 用不同随机种子生成多张图片,通过 reward model 计算 reward,再利用相关 RL 算法优化模型。
我发现囤Agent的Skills有瘾, 今天刚装了一大堆同类Skill,还没用熟就想提前知道这类里最好的到底是哪一个。转头又发现某个佬推荐了自留的20个Skills,回回路过我都忍不住点进去看。

Realtime API 是 OpenAI 的实时语音交互接口,在 24 年的 DevDay 首次亮相,当时还是 beta,调用贵到离谱,音频输出 200 刀/百万 token:OpenAI 凌晨发布:Realtime 实时多模态 API,及其他
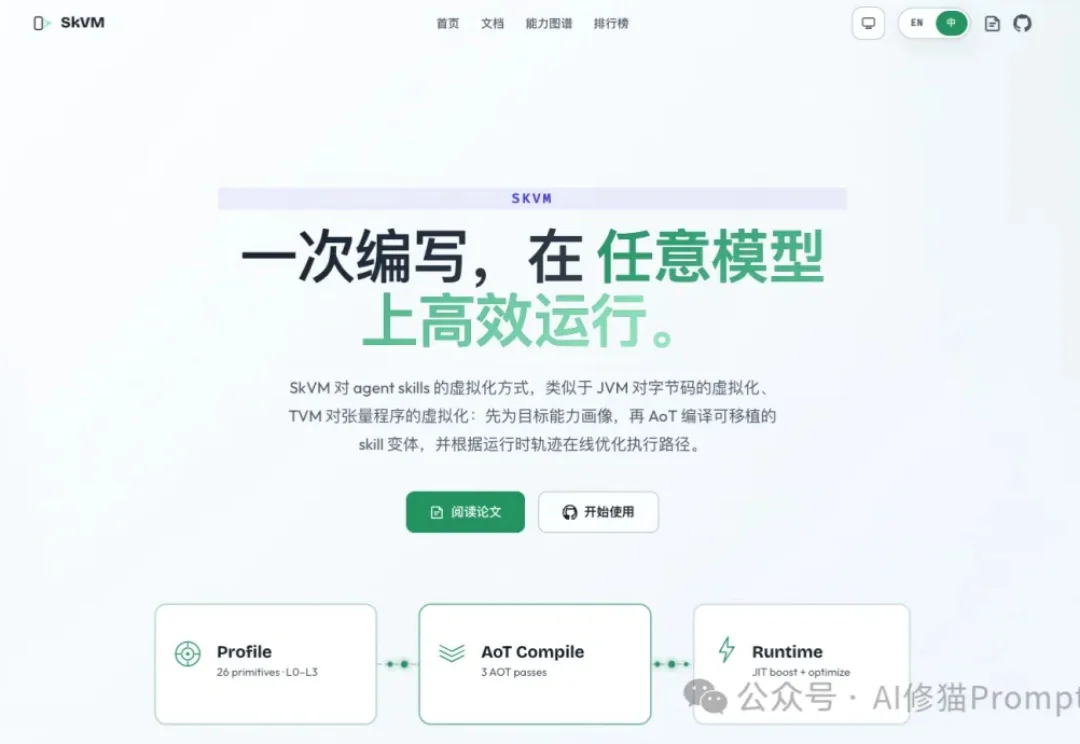
如果您经常用Claude Code、OpenCode、OpenClaw这类Agent框架,大概率会遇到一种不稳定现象:同一个Skills,用Claude能跑,换成Qwen就不行了;在Claude Code里稳定的流程,换到OpenClaw可能输出格式崩掉;在作者环境里正常的脚本,到了自己机器上可能因为缺依赖进入反复报错。
真的,你有过这种时刻吗。
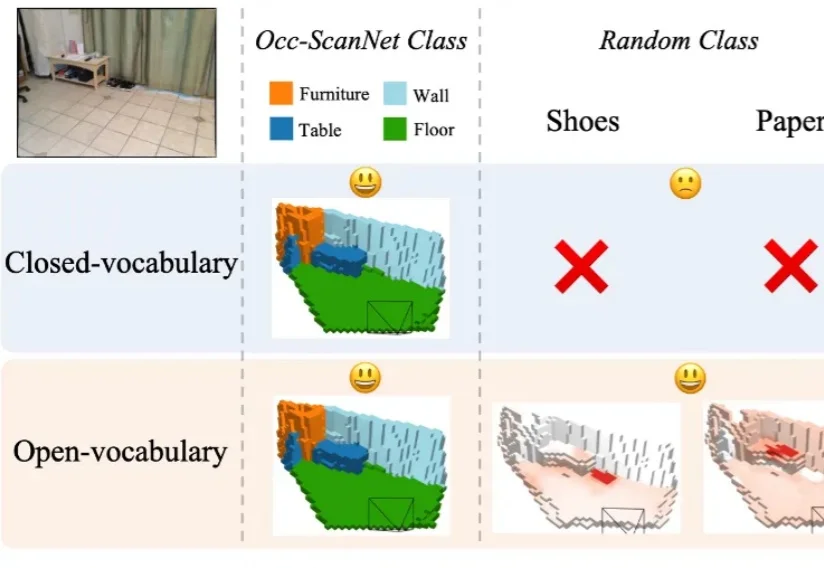
在具身智能研究中,如何让智能体精准理解周围环境的精细几何结构与开放语义信息,始终是具身感知的核心难题。近年来,语义占据预测(Semantic Occupancy Prediction) 将稠密几何与语义信息统一到三维体素网格中,用于构建 3D 语义占据地图,为机器人的空间推理、导航与交互操作提供了场景表达基础。
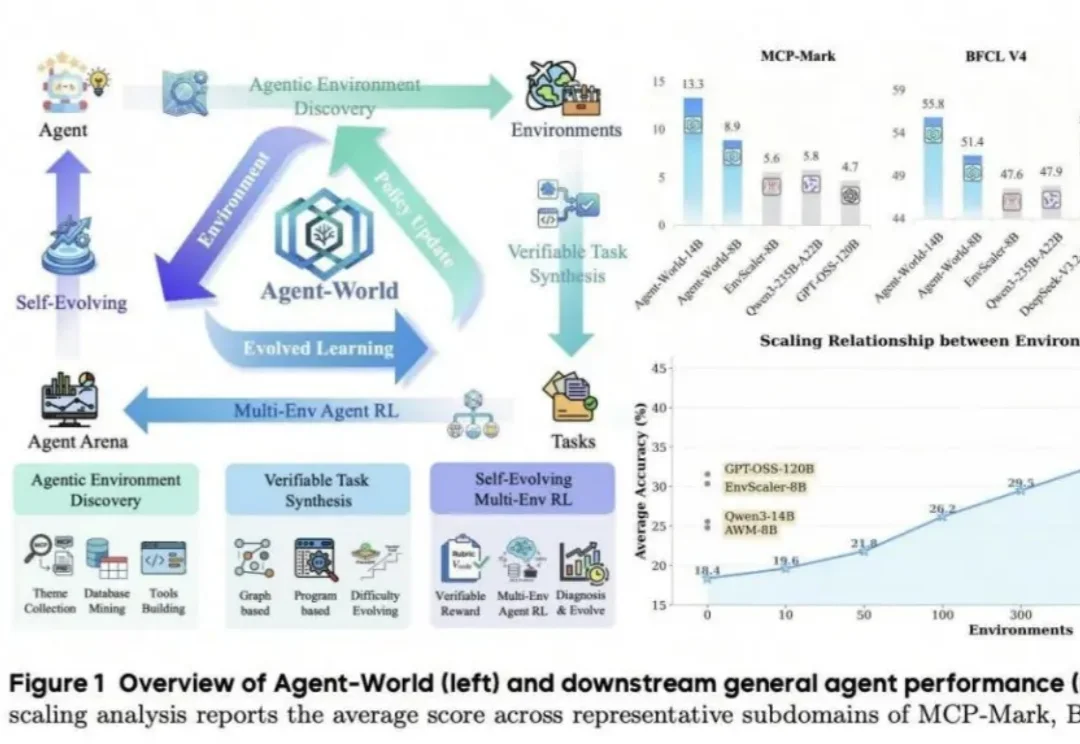
随着MCP、Agent Skills与各类Harness的快速发展,大模型能轻松调用成百上千种外部工具,但在多工具,具备复杂状态、长程交互的任务上仍有明显短板。尽管一系列环境扩展方法尝试复刻真实世界的交互环境(如订票系统,外卖平台),但仍受限于环境扩展的规模与真实性。

2026年,一群AI研究者给模型制造了毒品。 没错,论文中就叫毒品——AI Drugs。 他们生成了一些256×256像素的图片,这些我们看着全是毫无意义的色块。但AI看了之后表现得近乎狂喜——它自己报告的幸福感飙到6.5/7。
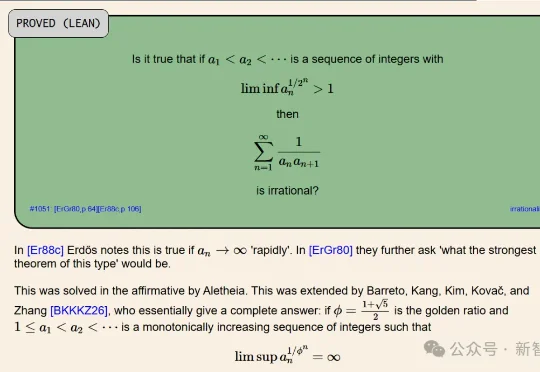
Google DeepMind再次血洗数学圈!700个地狱级难题被丢进Gemini的熔炉,结果让数学家集体破防:这哪是证明,这分明是「逻辑拆迁」。DeepMind这一波不仅贴脸爆杀了OpenAI,还砸烂了人类所有的优越感。

UC伯克利联合斯坦福提出的Combee,正是为此而来。它把Prompt Learning从低并发、顺序式更新,推进到高并发、分布式经验聚合,并已在ACE和GEPA中完成验证。
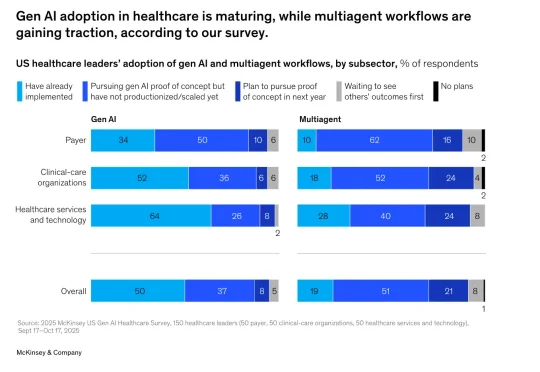
近日,麦肯锡发布了关于“生成式人工智能在医疗领域的应用”的报告。报告调研覆盖150家医疗保健机构的领导者,具体包括50家医疗支付方、50家临床医疗机构和50家医疗健康服务与科技企业,覆盖医疗各细分领域,样本具有代表性。
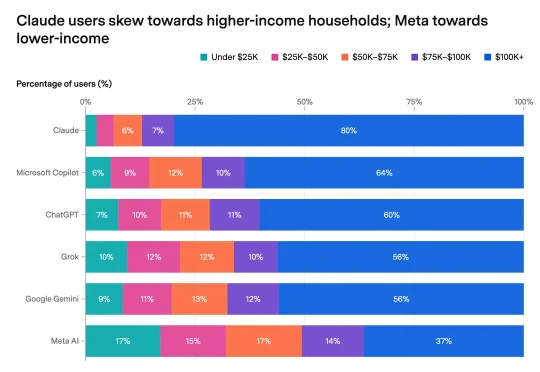
Epoch AI 与 Ipsos 调查显示,美国 Claude 周活用户 80% 来自年入 10 万美元以上家庭。AI 助手开始按价格、入口和工作场景分层,高收入用户率先进入更高阶的 AI 服务。
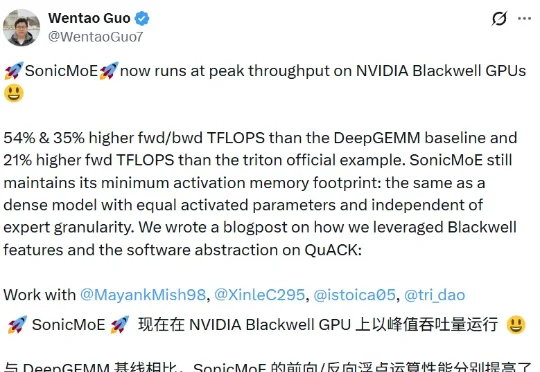
近日,由普林斯顿大学 Tri Dao(FlashAttention 的一作)和加州大学伯克利分校 Ion Stoica 领导的一个联合研究团队也做出了一个超快的索尼克:SonicMoE。据介绍,SonicMoE 能在英伟达 Blackwell GPU 上以峰值吞吐量运行!并且运算性能超过了 DeepSeek 之前开源并引发巨大轰动的 DeepGEMM。